 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointTransformerX:Portable and Efficient 3D Point Cloud Processing without Sparse Algorithms
Apr 27, 20263D point cloud perception remains tightly coupled to custom CUDA operators for spatial operations, limiting portability and efficiency on non-NVIDIA, AMD, and embedded hardware. We introduce PointTransformerX (PTX), a fully PyTorch-native vision transformer backbone for 3D point clouds, removing all custom CUDA operators and external libraries while retaining competitive accuracy. PTX introduces 3D-GS-RoPE, a rotary positional embedding that encodes 3D spatial relationships directly in self-attention without neighborhood construction, and further replaces sparse convolutional patch embedding with a linear projection. PTX explores inference-time scaling of attention windows to improve accuracy without retraining. With a redesigned feed-forward network, PTX achieves 98.7\% of PointTransformer V3's accuracy on ScanNet with 79.2\% fewer parameters and executing 1.6\times faster while requiring just 253 MB memory. PTX runs natively on NVIDIA GPUs, AMD GPUs (ROCm), and CPUs, providing an efficient and portable foundation for point cloud perception.
D-PLS: Decoupled Semantic Segmentation for 4D-Panoptic-LiDAR-Segmentation
Jan 27, 2025



This paper introduces a novel approach to 4D Panoptic LiDAR Segmentation that decouples semantic and instance segmentation, leveraging single-scan semantic predictions as prior information for instance segmentation. Our method D-PLS first performs single-scan semantic segmentation and aggregates the results over time, using them to guide instance segmentation. The modular design of D-PLS allows for seamless integration on top of any semantic segmentation architecture, without requiring architectural changes or retraining. We evaluate our approach on the SemanticKITTI dataset, where it demonstrates significant improvements over the baseline in both classification and association tasks, as measured by the LiDAR Segmentation and Tracking Quality (LSTQ) metric. Furthermore, we show that our decoupled architecture not only enhances instance prediction but also surpasses the baseline due to advancements in single-scan semantic segmentation.
Classifier Ensemble for Efficient Uncertainty Calibration of Deep Neural Networks for Image Classification
Jan 17, 2025



This paper investigates novel classifier ensemble techniques for uncertainty calibration applied to various deep neural networks for image classification. We evaluate both accuracy and calibration metrics, focusing on Expected Calibration Error (ECE) and Maximum Calibration Error (MCE). Our work compares different methods for building simple yet efficient classifier ensembles, including majority voting and several metamodel-based approaches. Our evaluation reveals that while state-of-the-art deep neural networks for image classification achieve high accuracy on standard datasets, they frequently suffer from significant calibration errors. Basic ensemble techniques like majority voting provide modest improvements, while metamodel-based ensembles consistently reduce ECE and MCE across all architectures. Notably, the largest of our compared metamodels demonstrate the most substantial calibration improvements, with minimal impact on accuracy. Moreover, classifier ensembles with metamodels outperform traditional model ensembles in calibration performance, while requiring significantly fewer parameters. In comparison to traditional post-hoc calibration methods, our approach removes the need for a separate calibration dataset. These findings underscore the potential of our proposed metamodel-based classifier ensembles as an efficient and effective approach to improving model calibration, thereby contributing to more reliable deep learning systems.
Text3DAug -- Prompted Instance Augmentation for LiDAR Perception
Aug 27, 2024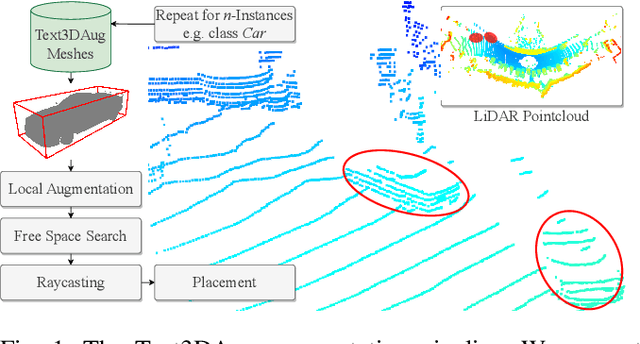



LiDAR data of urban scenarios poses unique challenges, such as heterogeneous characteristics and inherent class imbalance. Therefore, large-scale datasets are necessary to apply deep learning methods. Instance augmentation has emerged as an efficient method to increase dataset diversity. However, current methods require the time-consuming curation of 3D models or costly manual data annotation. To overcome these limitations, we propose Text3DAug, a novel approach leveraging generative models for instance augmentation. Text3DAug does not depend on labeled data and is the first of its kind to generate instances and annotations from text. This allows for a fully automated pipeline, eliminating the need for manual effort in practical applications. Additionally, Text3DAug is sensor agnostic and can be applied regardless of the LiDAR sensor used. Comprehensive experimental analysis on LiDAR segmentation, detection and novel class discovery demonstrates that Text3DAug is effective in supplementing existing methods or as a standalone method, performing on par or better than established methods, however while overcoming their specific drawbacks. The code is publicly available.
RadarPillars: Efficient Object Detection from 4D Radar Point Clouds
Aug 09, 2024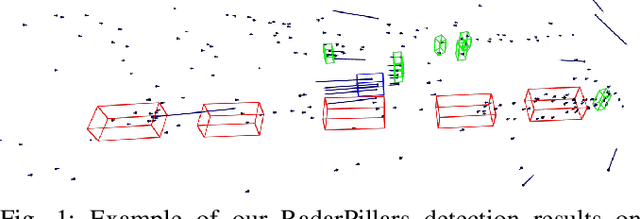
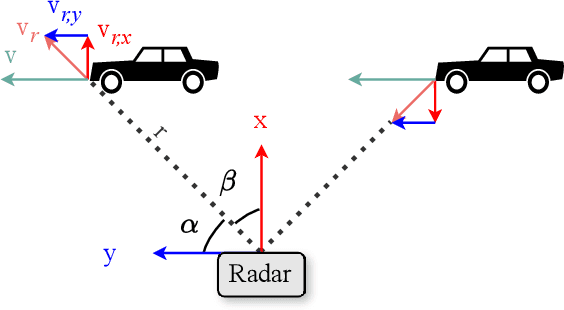
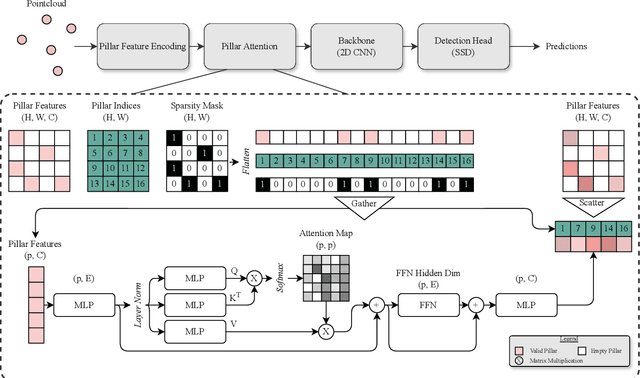
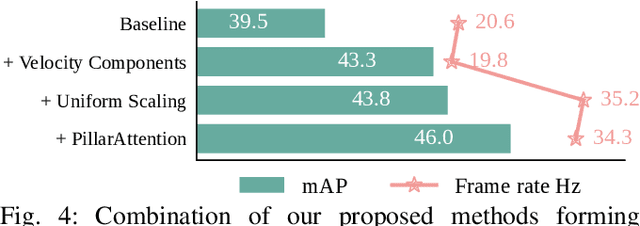
Automotive radar systems have evolved to provide not only range, azimuth and Doppler velocity, but also elevation data. This additional dimension allows for the representation of 4D radar as a 3D point cloud. As a result, existing deep learning methods for 3D object detection, which were initially developed for LiDAR data, are often applied to these radar point clouds. However, this neglects the special characteristics of 4D radar data, such as the extreme sparsity and the optimal utilization of velocity information. To address these gaps in the state-of-the-art, we present RadarPillars, a pillar-based object detection network. By decomposing radial velocity data, introducing PillarAttention for efficient feature extraction, and studying layer scaling to accommodate radar sparsity, RadarPillars significantly outperform state-of-the-art detection results on the View-of-Delft dataset. Importantly, this comes at a significantly reduced parameter count, surpassing existing methods in terms of efficiency and enabling real-time performance on edge devices.
360$^\circ$ from a Single Camera: A Few-Shot Approach for LiDAR Segmentation
Sep 12, 2023



Deep learning applications on LiDAR data suffer from a strong domain gap when applied to different sensors or tasks. In order for these methods to obtain similar accuracy on different data in comparison to values reported on public benchmarks, a large scale annotated dataset is necessary. However, in practical applications labeled data is costly and time consuming to obtain. Such factors have triggered various research in label-efficient methods, but a large gap remains to their fully-supervised counterparts. Thus, we propose ImageTo360, an effective and streamlined few-shot approach to label-efficient LiDAR segmentation. Our method utilizes an image teacher network to generate semantic predictions for LiDAR data within a single camera view. The teacher is used to pretrain the LiDAR segmentation student network, prior to optional fine-tuning on 360$^\circ$ data. Our method is implemented in a modular manner on the point level and as such is generalizable to different architectures. We improve over the current state-of-the-art results for label-efficient methods and even surpass some traditional fully-supervised segmentation networks.
Light-Weight Vision Transformer with Parallel Local and Global Self-Attention
Jul 18, 2023



While transformer architectures have dominated computer vision in recent years, these models cannot easily be deployed on hardware with limited resources for autonomous driving tasks that require real-time-performance. Their computational complexity and memory requirements limits their use, especially for applications with high-resolution inputs. In our work, we redesign the powerful state-of-the-art Vision Transformer PLG-ViT to a much more compact and efficient architecture that is suitable for such tasks. We identify computationally expensive blocks in the original PLG-ViT architecture and propose several redesigns aimed at reducing the number of parameters and floating-point operations. As a result of our redesign, we are able to reduce PLG-ViT in size by a factor of 5, with a moderate drop in performance. We propose two variants, optimized for the best trade-off between parameter count to runtime as well as parameter count to accuracy. With only 5 million parameters, we achieve 79.5$\%$ top-1 accuracy on the ImageNet-1K classification benchmark. Our networks demonstrate great performance on general vision benchmarks like COCO instance segmentation. In addition, we conduct a series of experiments, demonstrating the potential of our approach in solving various tasks specifically tailored to the challenges of autonomous driving and transportation.
DVMN: Dense Validity Mask Network for Depth Completion
Jul 14, 2021

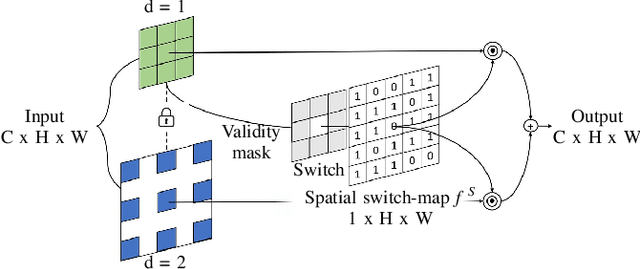
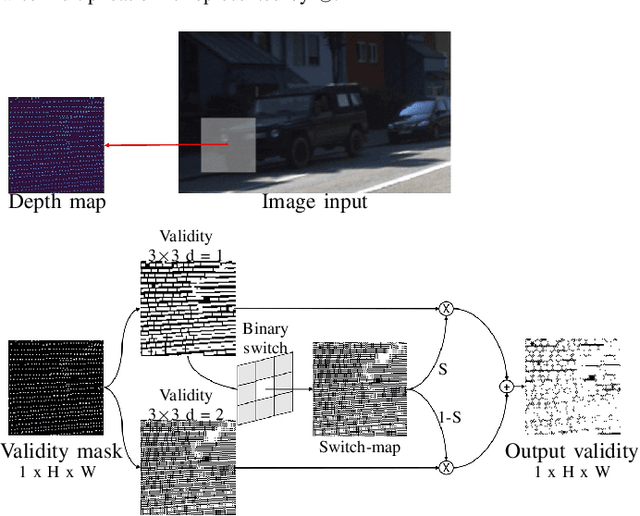
LiDAR depth maps provide environmental guidance in a variety of applications. However, such depth maps are typically sparse and insufficient for complex tasks such as autonomous navigation. State of the art methods use image guided neural networks for dense depth completion. We develop a guided convolutional neural network focusing on gathering dense and valid information from sparse depth maps. To this end, we introduce a novel layer with spatially variant and content-depended dilation to include additional data from sparse input. Furthermore, we propose a sparsity invariant residual bottleneck block. We evaluate our Dense Validity Mask Network (DVMN) on the KITTI depth completion benchmark and achieve state of the art results. At the time of submission, our network is the leading method using sparsity invariant convolution.