 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Network for Joint Object Detection, Semantic Segmentation and Human Pose Estimation in Vehicle Occupancy Monitoring
May 03, 2022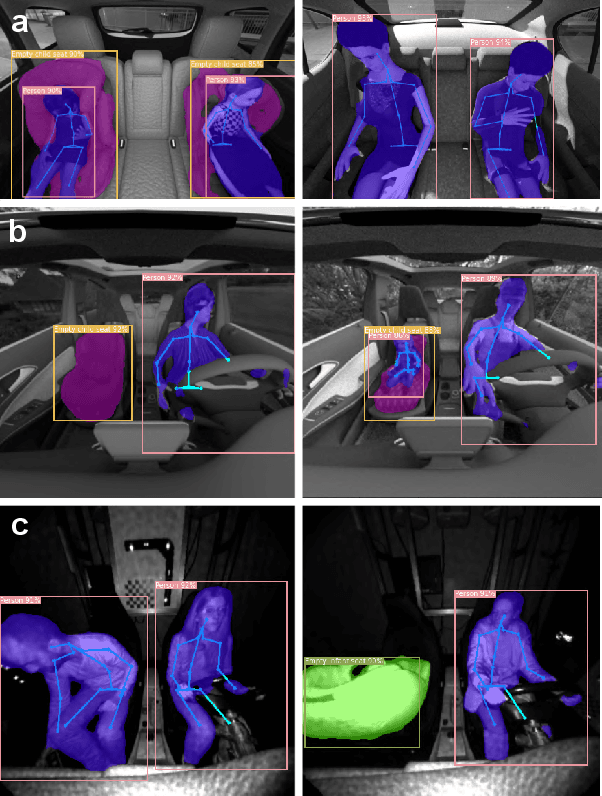
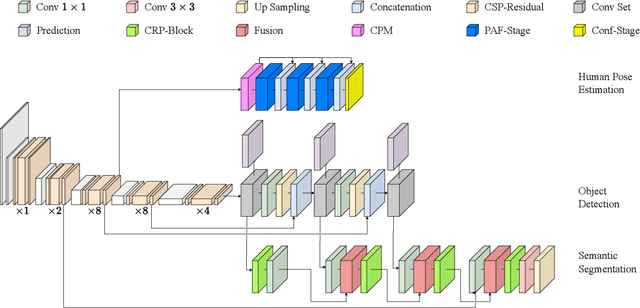


In order to ensure safe autonomous driving, precise information about the conditions in and around the vehicle must be available. Accordingly, the monitoring of occupants and objects inside the vehicle is crucial. In the state-of-the-art, single or multiple deep neural networks are used for either object recognition, semantic segmentation, or human pose estimation. In contrast, we propose our Multitask Detection, Segmentation and Pose Estimation Network (MDSP) -- the first multitask network solving all these three tasks jointly in the area of occupancy monitoring. Due to the shared architecture, memory and computing costs can be saved while achieving higher accuracy. Furthermore, our architecture allows a flexible combination of the three mentioned tasks during a simple end-to-end training. We perform comprehensive evaluations on the public datasets SVIRO and TiCaM in order to demonstrate the superior performance.
Detection of Driver Drowsiness by Calculating the Speed of Eye Blinking
Oct 21, 2021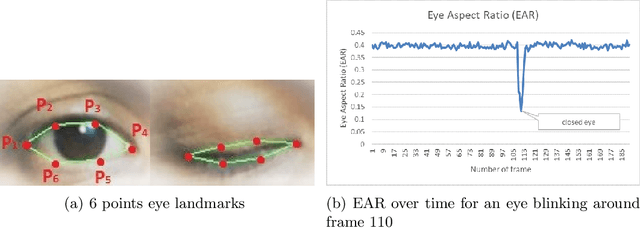
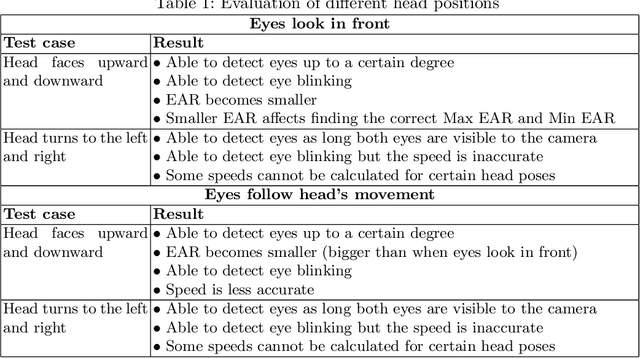
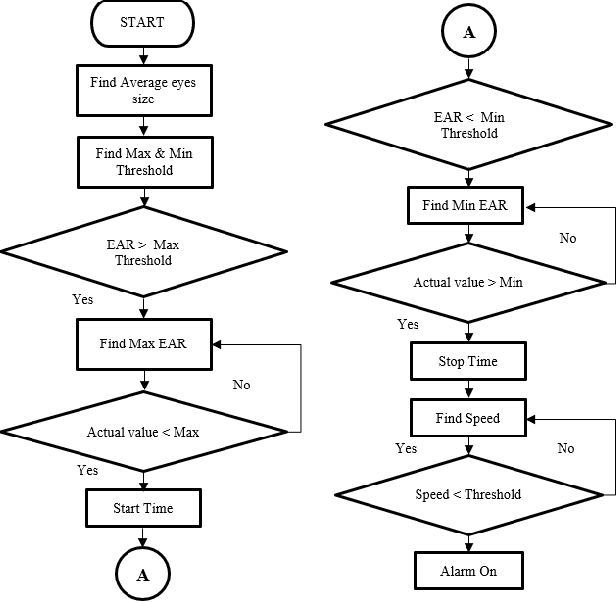
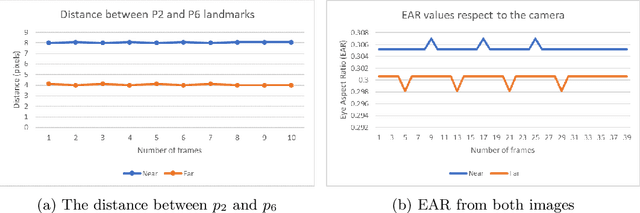
Many road accidents are caused by drowsiness of the driver. While there are methods to detect closed eyes, it is a non-trivial task to detect the gradual process of a driver becoming drowsy. We consider a simple real-time detection system for drowsiness merely based on the eye blinking rate derived from the eye aspect ratio. For the eye detection we use HOG and a linear SVM. If the speed of the eye blinking drops below some empirically determined threshold, the system triggers an alarm, hence preventing the driver from falling into microsleep. In this paper, we extensively evaluate the minimal requirements for the proposed system. We find that this system works well if the face is directed to the camera, but it becomes less reliable once the head is tilted significantly. The results of our evaluations provide the foundation for further developments of our drowsiness detection system.
PDC: Piecewise Depth Completion utilizing Superpixels
Jul 14, 2021



Depth completion from sparse LiDAR and high-resolution RGB data is one of the foundations for autonomous driving techniques. Current approaches often rely on CNN-based methods with several known drawbacks: flying pixel at depth discontinuities, overfitting to both a given data set as well as error metric, and many more. Thus, we propose our novel Piecewise Depth Completion (PDC), which works completely without deep learning. PDC segments the RGB image into superpixels corresponding the regions with similar depth value. Superpixels corresponding to same objects are gathered using a cost map. At the end, we receive detailed depth images with state of the art accuracy. In our evaluation, we can show both the influence of the individual proposed processing steps and the overall performance of our method on the challenging KITTI dataset.
DVMN: Dense Validity Mask Network for Depth Completion
Jul 14, 2021

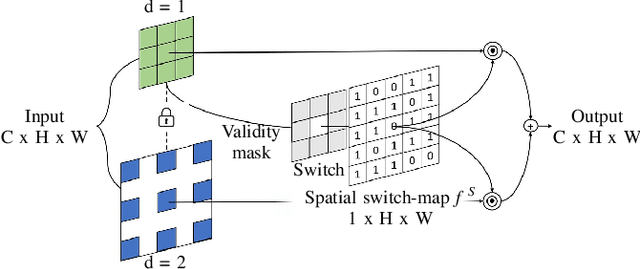
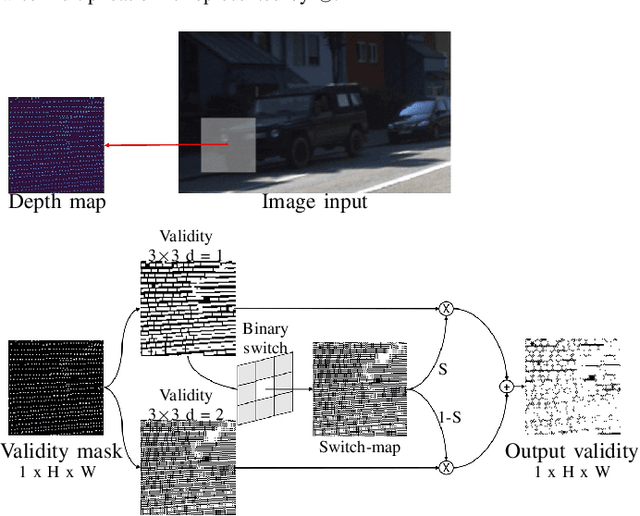
LiDAR depth maps provide environmental guidance in a variety of applications. However, such depth maps are typically sparse and insufficient for complex tasks such as autonomous navigation. State of the art methods use image guided neural networks for dense depth completion. We develop a guided convolutional neural network focusing on gathering dense and valid information from sparse depth maps. To this end, we introduce a novel layer with spatially variant and content-depended dilation to include additional data from sparse input. Furthermore, we propose a sparsity invariant residual bottleneck block. We evaluate our Dense Validity Mask Network (DVMN) on the KITTI depth completion benchmark and achieve state of the art results. At the time of submission, our network is the leading method using sparsity invariant convolution.