 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQirK: Question Answering via Intermediate Representation on Knowledge Graphs
Aug 14, 2024

We demonstrate QirK, a system for answering natural language questions on Knowledge Graphs (KG). QirK can answer structurally complex questions that are still beyond the reach of emerging Large Language Models (LLMs). It does so using a unique combination of database technology, LLMs, and semantic search over vector embeddings. The glue for these components is an intermediate representation (IR). The input question is mapped to IR using LLMs, which is then repaired into a valid relational database query with the aid of a semantic search on vector embeddings. This allows a practical synthesis of LLM capabilities and KG reliability. A short video demonstrating QirK is available at https://youtu.be/6c81BLmOZ0U.
AnnotatedTables: A Large Tabular Dataset with Language Model Annotations
Jun 24, 2024



Tabular data is ubiquitous in real-world applications and abundant on the web, yet its annotation has traditionally required human labor, posing a significant scalability bottleneck for tabular machine learning. Our methodology can successfully annotate a large amount of tabular data and can be flexibly steered to generate various types of annotations based on specific research objectives, as we demonstrate with SQL annotation and input-target column annotation as examples. As a result, we release AnnotatedTables, a collection of 32,119 databases with LLM-generated annotations. The dataset includes 405,616 valid SQL programs, making it the largest SQL dataset with associated tabular data that supports query execution. To further demonstrate the value of our methodology and dataset, we perform two follow-up research studies. 1) We investigate whether LLMs can translate SQL programs to Rel programs, a database language previously unknown to LLMs, while obtaining the same execution results. Using our Incremental Prompt Engineering methods based on execution feedback, we show that LLMs can produce adequate translations with few-shot learning. 2) We evaluate the performance of TabPFN, a recent neural tabular classifier trained on Bayesian priors, on 2,720 tables with input-target columns identified and annotated by LLMs. On average, TabPFN performs on par with the baseline AutoML method, though the relative performance can vary significantly from one data table to another, making both models viable for practical applications depending on the situation. Our findings underscore the potential of LLMs in automating the annotation of large volumes of diverse tabular data.
CHORUS: Foundation Models for Unified Data Discovery and Exploration
Jun 16, 2023We explore the application of foundation models to data discovery and exploration tasks. Foundation models are large language models (LLMs) that show promising performance on a range of diverse tasks unrelated to their training. We show that these models are highly applicable to the data discovery and data exploration domain. When carefully used, they have superior capability on three representative tasks: table-class detection, column-type annotation and join-column prediction. On all three tasks, we show that a foundation-model-based approach outperforms the task-specific models and so the state of the art. Further, our approach often surpasses human-expert task performance. This suggests a future direction in which disparate data management tasks can be unified under foundation models.
On algorithmically boosting fixed-point computations
Apr 04, 2023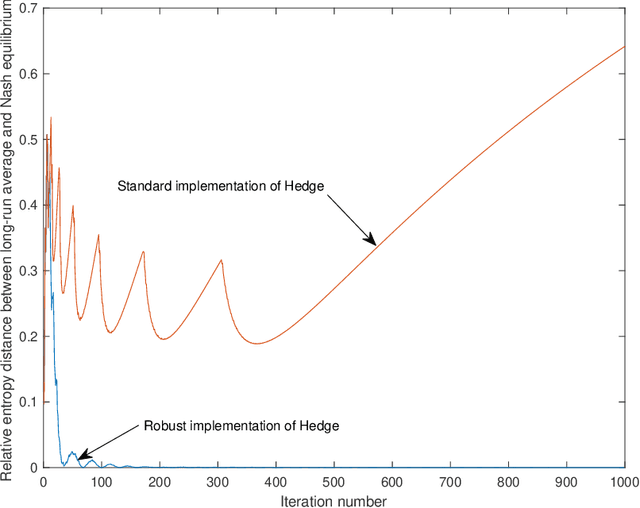
This paper is a thought experiment on exponentiating algorithms. One of the main contributions of this paper is to show that this idea finds material implementation in exponentiating fixed-point computation algorithms. Various problems in computer science can be cast as instances of computing a fixed point of a map. In this paper, we present a general method of boosting the convergence of iterative fixed-point computations that we call algorithmic boosting, which is a (slight) generalization of algorithmic exponentiation. We first define our method in the general setting of nonlinear maps. Secondly, we restrict attention to convergent linear maps and show that our algorithmic boosting method can set in motion exponential speedups in the convergence rate. Thirdly, we show that algorithmic boosting can convert a (weak) non-convergent iterator to a (strong) convergent one. We then consider a variational approach to algorithmic boosting providing tools to convert a non-convergent continuous flow to a convergent one. We, finally, discuss implementations of the exponential function, an important issue even for the scalar case.
Multi-way Interacting Regression via Factorization Machines
Sep 27, 2017
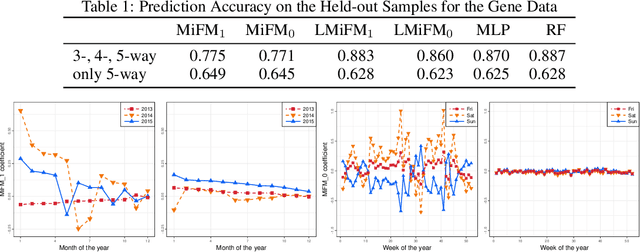

We propose a Bayesian regression method that accounts for multi-way interactions of arbitrary orders among the predictor variables. Our model makes use of a factorization mechanism for representing the regression coefficients of interactions among the predictors, while the interaction selection is guided by a prior distribution on random hypergraphs, a construction which generalizes the Finite Feature Model. We present a posterior inference algorithm based on Gibbs sampling, and establish posterior consistency of our regression model. Our method is evaluated with extensive experiments on simulated data and demonstrated to be able to identify meaningful interactions in applications in genetics and retail demand forecasting.
Practical Attacks Against Graph-based Clustering
Aug 29, 2017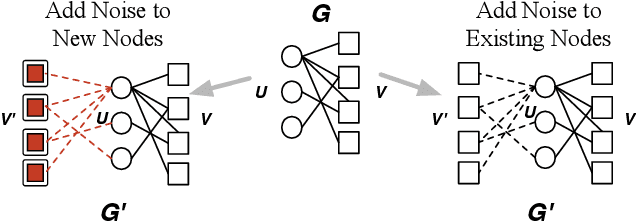


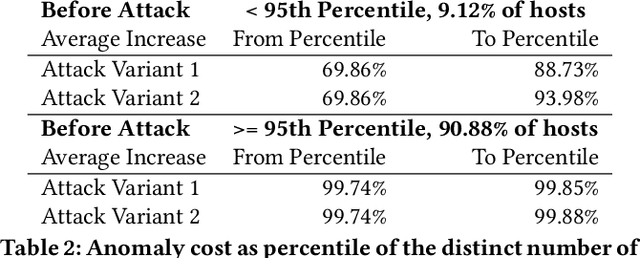
Graph modeling allows numerous security problems to be tackled in a general way, however, little work has been done to understand their ability to withstand adversarial attacks. We design and evaluate two novel graph attacks against a state-of-the-art network-level, graph-based detection system. Our work highlights areas in adversarial machine learning that have not yet been addressed, specifically: graph-based clustering techniques, and a global feature space where realistic attackers without perfect knowledge must be accounted for (by the defenders) in order to be practical. Even though less informed attackers can evade graph clustering with low cost, we show that some practical defenses are possible.
ERBlox: Combining Matching Dependencies with Machine Learning for Entity Resolution
Jan 18, 2017
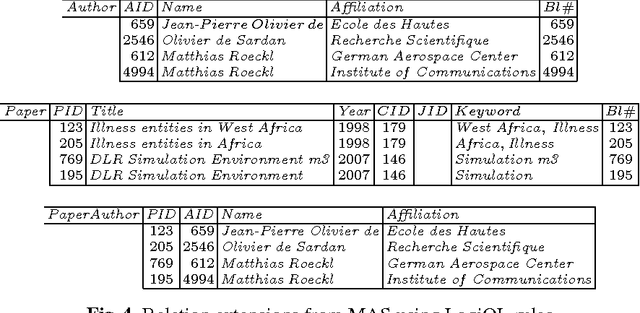
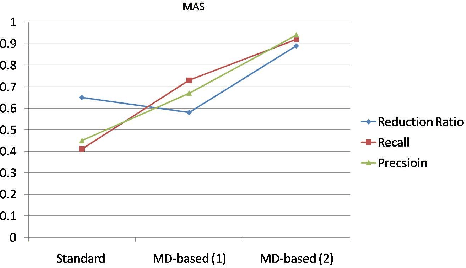
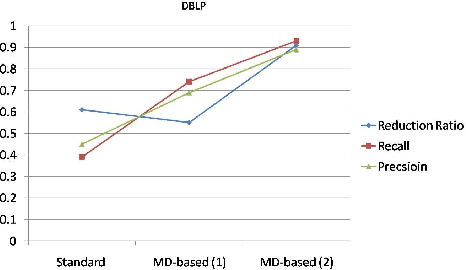
Entity resolution (ER), an important and common data cleaning problem, is about detecting data duplicate representations for the same external entities, and merging them into single representations. Relatively recently, declarative rules called "matching dependencies" (MDs) have been proposed for specifying similarity conditions under which attribute values in database records are merged. In this work we show the process and the benefits of integrating four components of ER: (a) Building a classifier for duplicate/non-duplicate record pairs built using machine learning (ML) techniques; (b) Use of MDs for supporting the blocking phase of ML; (c) Record merging on the basis of the classifier results; and (d) The use of the declarative language "LogiQL" -an extended form of Datalog supported by the "LogicBlox" platform- for all activities related to data processing, and the specification and enforcement of MDs.
Non-Negative Matrix Factorization, Convexity and Isometry
Apr 22, 2009

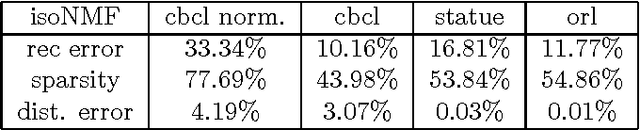

In this paper we explore avenues for improving the reliability of dimensionality reduction methods such as Non-Negative Matrix Factorization (NMF) as interpretive exploratory data analysis tools. We first explore the difficulties of the optimization problem underlying NMF, showing for the first time that non-trivial NMF solutions always exist and that the optimization problem is actually convex, by using the theory of Completely Positive Factorization. We subsequently explore four novel approaches to finding globally-optimal NMF solutions using various ideas from convex optimization. We then develop a new method, isometric NMF (isoNMF), which preserves non-negativity while also providing an isometric embedding, simultaneously achieving two properties which are helpful for interpretation. Though it results in a more difficult optimization problem, we show experimentally that the resulting method is scalable and even achieves more compact spectra than standard NMF.
Learning Isometric Separation Maps
Apr 15, 2009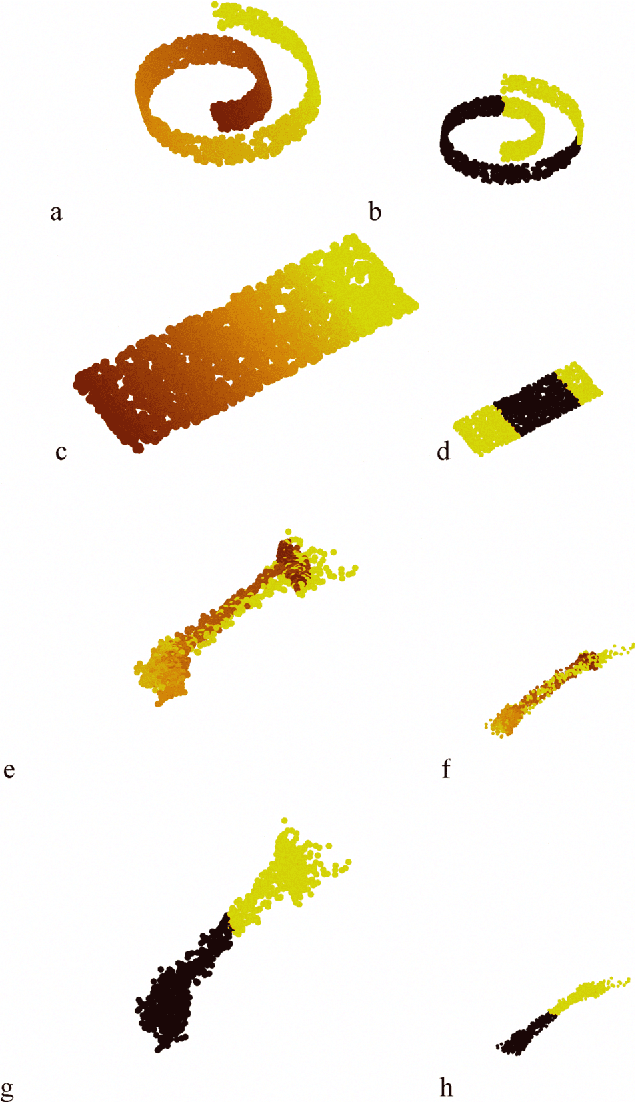
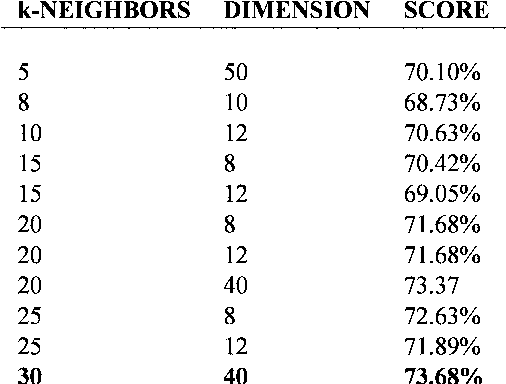

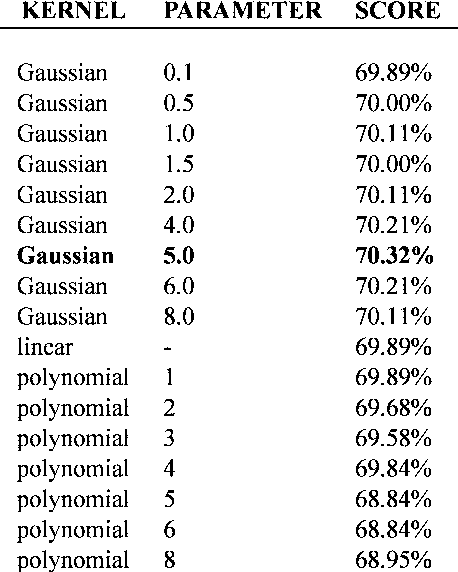
Maximum Variance Unfolding (MVU) and its variants have been very successful in embedding data-manifolds in lower dimensional spaces, often revealing the true intrinsic dimension. In this paper we show how to also incorporate supervised class information into an MVU-like method without breaking its convexity. We call this method the Isometric Separation Map and we show that the resulting kernel matrix can be used as a binary/multiclass Support Vector Machine-like method in a semi-supervised (transductive) framework. We also show that the method always finds a kernel matrix that linearly separates the training data exactly without projecting them in infinite dimensional spaces. In traditional SVMs we choose a kernel and hope that the data become linearly separable in the kernel space. In this paper we show how the hyperplane can be chosen ad-hoc and the kernel is trained so that data are always linearly separable. Comparisons with Large Margin SVMs show comparable performance.