 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatabase Views as Explanations for Relational Deep Learning
Sep 11, 2025In recent years, there has been significant progress in the development of deep learning models over relational databases, including architectures based on heterogeneous graph neural networks (hetero-GNNs) and heterogeneous graph transformers. In effect, such architectures state how the database records and links (e.g., foreign-key references) translate into a large, complex numerical expression, involving numerous learnable parameters. This complexity makes it hard to explain, in human-understandable terms, how a model uses the available data to arrive at a given prediction. We present a novel framework for explaining machine-learning models over relational databases, where explanations are view definitions that highlight focused parts of the database that mostly contribute to the model's prediction. We establish such global abductive explanations by adapting the classic notion of determinacy by Nash, Segoufin, and Vianu (2010). In addition to tuning the tradeoff between determinacy and conciseness, the framework allows controlling the level of granularity by adopting different fragments of view definitions, such as ones highlighting whole columns, foreign keys between tables, relevant groups of tuples, and so on. We investigate the realization of the framework in the case of hetero-GNNs. We develop heuristic algorithms that avoid the exhaustive search over the space of all databases. We propose techniques that are model-agnostic, and others that are tailored to hetero-GNNs via the notion of learnable masking. Our approach is evaluated through an extensive empirical study on the RelBench collection, covering a variety of domains and different record-level tasks. The results demonstrate the usefulness of the proposed explanations, as well as the efficiency of their generation.
QirK: Question Answering via Intermediate Representation on Knowledge Graphs
Aug 14, 2024

We demonstrate QirK, a system for answering natural language questions on Knowledge Graphs (KG). QirK can answer structurally complex questions that are still beyond the reach of emerging Large Language Models (LLMs). It does so using a unique combination of database technology, LLMs, and semantic search over vector embeddings. The glue for these components is an intermediate representation (IR). The input question is mapped to IR using LLMs, which is then repaired into a valid relational database query with the aid of a semantic search on vector embeddings. This allows a practical synthesis of LLM capabilities and KG reliability. A short video demonstrating QirK is available at https://youtu.be/6c81BLmOZ0U.
AnnotatedTables: A Large Tabular Dataset with Language Model Annotations
Jun 24, 2024



Tabular data is ubiquitous in real-world applications and abundant on the web, yet its annotation has traditionally required human labor, posing a significant scalability bottleneck for tabular machine learning. Our methodology can successfully annotate a large amount of tabular data and can be flexibly steered to generate various types of annotations based on specific research objectives, as we demonstrate with SQL annotation and input-target column annotation as examples. As a result, we release AnnotatedTables, a collection of 32,119 databases with LLM-generated annotations. The dataset includes 405,616 valid SQL programs, making it the largest SQL dataset with associated tabular data that supports query execution. To further demonstrate the value of our methodology and dataset, we perform two follow-up research studies. 1) We investigate whether LLMs can translate SQL programs to Rel programs, a database language previously unknown to LLMs, while obtaining the same execution results. Using our Incremental Prompt Engineering methods based on execution feedback, we show that LLMs can produce adequate translations with few-shot learning. 2) We evaluate the performance of TabPFN, a recent neural tabular classifier trained on Bayesian priors, on 2,720 tables with input-target columns identified and annotated by LLMs. On average, TabPFN performs on par with the baseline AutoML method, though the relative performance can vary significantly from one data table to another, making both models viable for practical applications depending on the situation. Our findings underscore the potential of LLMs in automating the annotation of large volumes of diverse tabular data.
CHORUS: Foundation Models for Unified Data Discovery and Exploration
Jun 16, 2023


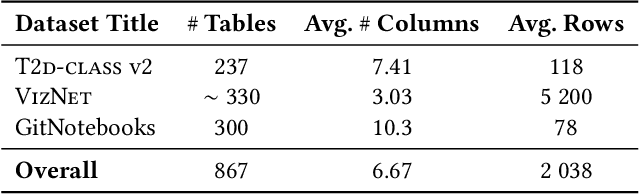
We explore the application of foundation models to data discovery and exploration tasks. Foundation models are large language models (LLMs) that show promising performance on a range of diverse tasks unrelated to their training. We show that these models are highly applicable to the data discovery and data exploration domain. When carefully used, they have superior capability on three representative tasks: table-class detection, column-type annotation and join-column prediction. On all three tasks, we show that a foundation-model-based approach outperforms the task-specific models and so the state of the art. Further, our approach often surpasses human-expert task performance. This suggests a future direction in which disparate data management tasks can be unified under foundation models.