 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiosockets: A Python socket package for Real-Time Audio Processing
Mar 14, 2024

There are many packages in Python which allow one to perform real-time processing on audio data. Unfortunately, due to the synchronous nature of the language, there lacks a framework which allows for distributed parallel processing of the data without requiring a large programming overhead and in which the data acquisition is not blocked by subsequent processing operations. This work improves on packages used for audio data collection with a light-weight backend and a simple interface that allows for distributed processing through a socket-based structure. This is intended for real-time audio machine learning and data processing in Python with a quick deployment of multiple parallel operations on the same data, allowing users to spend less time debugging and more time developing.
I-vector Based Within Speaker Voice Quality Identification on connected speech
Feb 15, 2021
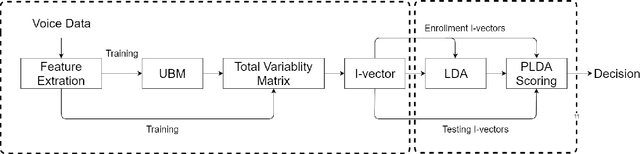
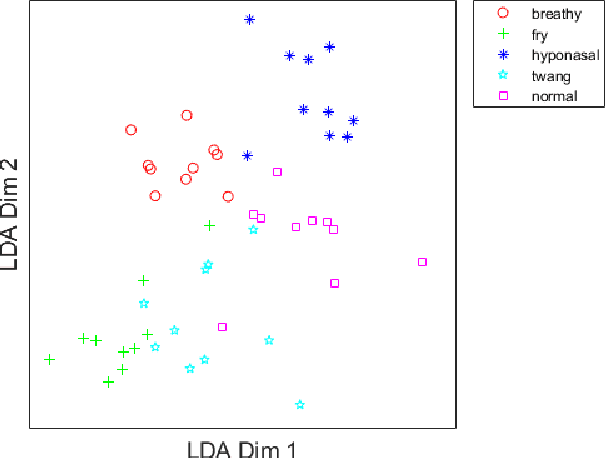

Voice disorders affect a large portion of the population, especially heavy voice users such as teachers or call-center workers. Most voice disorders can be treated effectively with behavioral voice therapy, which teaches patients to replace problematic, habituated voice production mechanics with optimal voice production technique(s), yielding improved voice quality. However, treatment often fails because patients have difficulty differentiating their habitual voice from the target technique independently, when clinician feedback is unavailable between therapy sessions. Therefore, with the long term aim to extend clinician feedback to extra-clinical settings, we built two systems that automatically differentiate various voice qualities produced by the same individual. We hypothesized that 1) a system based on i-vectors could classify these qualities as if they represent different speakers and 2) such a system would outperform one based on traditional voice signal processing algorithms. Training recordings were provided by thirteen amateur actors, each producing 5 perceptually different voice qualities in connected speech: normal, breathy, fry, twang, and hyponasal. As hypothesized, the i-vector system outperformed the acoustic measure system in classification accuracy (i.e. 97.5\% compared to 77.2\%, respectively). Findings are expected because the i-vector system maps features to an integrated space which better represents each voice quality than the 22-feature space of the baseline system. Therefore, an i-vector based system has potential for clinical application in voice therapy and voice training.
Non-Negative Matrix Factorization, Convexity and Isometry
Apr 22, 2009

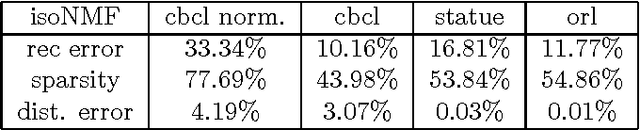

In this paper we explore avenues for improving the reliability of dimensionality reduction methods such as Non-Negative Matrix Factorization (NMF) as interpretive exploratory data analysis tools. We first explore the difficulties of the optimization problem underlying NMF, showing for the first time that non-trivial NMF solutions always exist and that the optimization problem is actually convex, by using the theory of Completely Positive Factorization. We subsequently explore four novel approaches to finding globally-optimal NMF solutions using various ideas from convex optimization. We then develop a new method, isometric NMF (isoNMF), which preserves non-negativity while also providing an isometric embedding, simultaneously achieving two properties which are helpful for interpretation. Though it results in a more difficult optimization problem, we show experimentally that the resulting method is scalable and even achieves more compact spectra than standard NMF.
Learning Isometric Separation Maps
Apr 15, 2009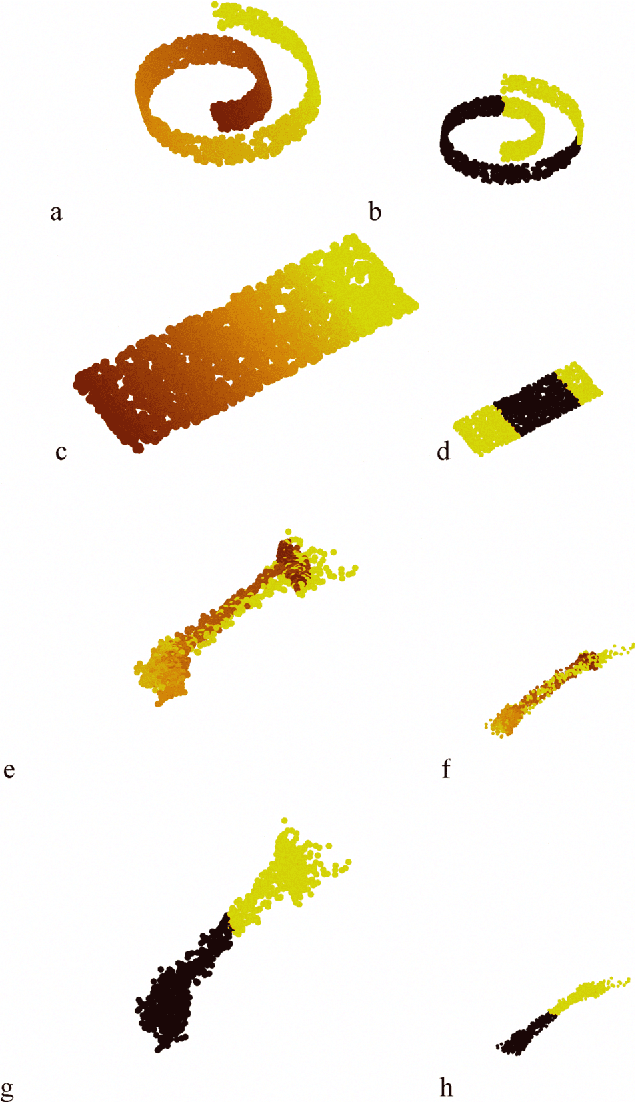
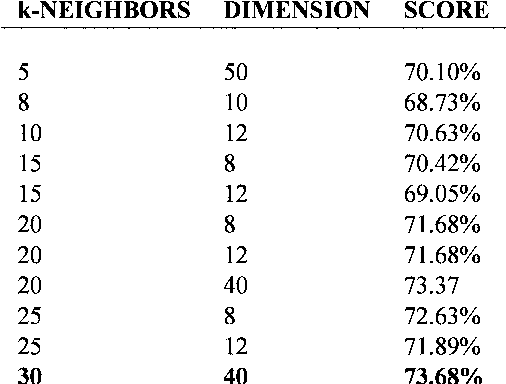

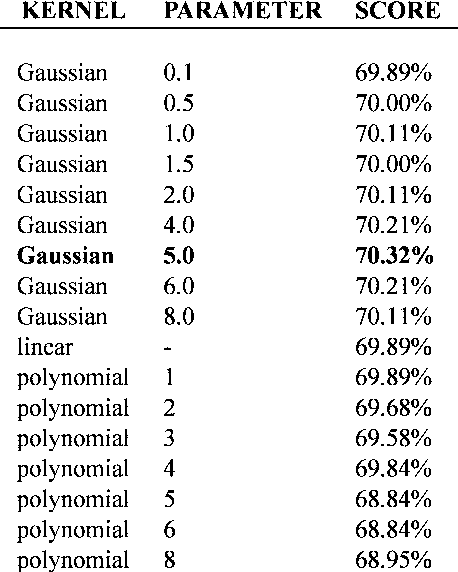
Maximum Variance Unfolding (MVU) and its variants have been very successful in embedding data-manifolds in lower dimensional spaces, often revealing the true intrinsic dimension. In this paper we show how to also incorporate supervised class information into an MVU-like method without breaking its convexity. We call this method the Isometric Separation Map and we show that the resulting kernel matrix can be used as a binary/multiclass Support Vector Machine-like method in a semi-supervised (transductive) framework. We also show that the method always finds a kernel matrix that linearly separates the training data exactly without projecting them in infinite dimensional spaces. In traditional SVMs we choose a kernel and hope that the data become linearly separable in the kernel space. In this paper we show how the hyperplane can be chosen ad-hoc and the kernel is trained so that data are always linearly separable. Comparisons with Large Margin SVMs show comparable performance.