 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-vector Based Within Speaker Voice Quality Identification on connected speech
Feb 15, 2021
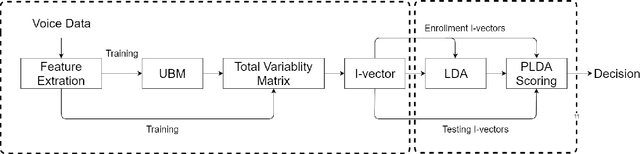
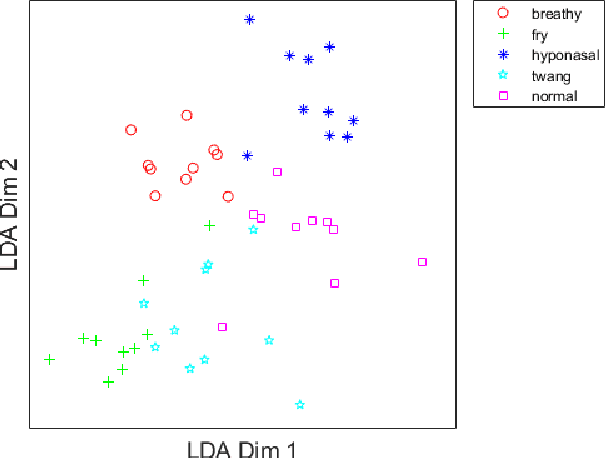

Voice disorders affect a large portion of the population, especially heavy voice users such as teachers or call-center workers. Most voice disorders can be treated effectively with behavioral voice therapy, which teaches patients to replace problematic, habituated voice production mechanics with optimal voice production technique(s), yielding improved voice quality. However, treatment often fails because patients have difficulty differentiating their habitual voice from the target technique independently, when clinician feedback is unavailable between therapy sessions. Therefore, with the long term aim to extend clinician feedback to extra-clinical settings, we built two systems that automatically differentiate various voice qualities produced by the same individual. We hypothesized that 1) a system based on i-vectors could classify these qualities as if they represent different speakers and 2) such a system would outperform one based on traditional voice signal processing algorithms. Training recordings were provided by thirteen amateur actors, each producing 5 perceptually different voice qualities in connected speech: normal, breathy, fry, twang, and hyponasal. As hypothesized, the i-vector system outperformed the acoustic measure system in classification accuracy (i.e. 97.5\% compared to 77.2\%, respectively). Findings are expected because the i-vector system maps features to an integrated space which better represents each voice quality than the 22-feature space of the baseline system. Therefore, an i-vector based system has potential for clinical application in voice therapy and voice training.