 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Rigid-Body Dynamics Algorithms for Systems with Kinematic Loops
Nov 22, 2023



We propose a novel approach for generalizing the following rigid-body dynamics algorithms: Recursive Newton-Euler Algorithm, Articulated-Body Algorithm, and Extended-Force-Propagator Algorithm. The classic versions of these recursive algorithms require systems to have an open chain structure. Dealing with closed-chains has, conventionally, required different algorithms. In this paper, we demonstrate that the classic recursive algorithms can be modified to work for closed-chain mechanisms. The critical insight of our generalized algorithms is the clustering of bodies involved in local loop constraints. Clustering bodies enables loop constraints to be resolved locally, i.e., only when that group of bodies is encountered during a forward or backward pass. This local treatment avoids the need for large-scale matrix factorization. We provide self-contained derivations of the algorithms using familiar, physically meaningful concepts. Overall, our approach provides a foundation for simulating robotic systems with traditionally difficult-to-simulate designs, such as geared motors, differential drives, and four-bar mechanisms. The performance of our library of algorithms is validated numerically in C++ on various modern legged robots: the MIT Mini Cheetah, the MIT Humanoid, the UIUC Tello Humanoid, and a modified version of the JVRC-1 Humanoid. Our algorithms are shown to outperform state-of-the-art algorithms for computing constrained rigid-body dynamics.
Task-Space Clustering for Mobile Manipulator Task Sequencing
May 27, 2023



Mobile manipulators have gained attention for the potential in performing large-scale tasks which are beyond the reach of fixed-base manipulators. The Robotic Task Sequencing Problem for mobile manipulators often requires optimizing the motion sequence of the robot to visit multiple targets while reducing the number of base placements. A two-step approach to this problem is clustering the task-space into clusters of targets before sequencing the robot motion. In this paper, we propose a task-space clustering method which formulates the clustering step as a Set Cover Problem using bipartite graph and reachability analysis, then solves it to obtain the minimum number of target clusters with corresponding base placements. We demonstrated the practical usage of our method in a mobile drilling experiment containing hundreds of targets. Multiple simulations were conducted to benchmark the algorithm and also showed that our proposed method found, in practical time, better solutions than the existing state-of-the-art methods.
DFBVS: Deep Feature-Based Visual Servo
Jan 20, 2022



Classical Visual Servoing (VS) rely on handcrafted visual features, which limit their generalizability. Recently, a number of approaches, some based on Deep Neural Networks, have been proposed to overcome this limitation by comparing directly the entire target and current camera images. However, by getting rid of the visual features altogether, those approaches require the target and current images to be essentially similar, which precludes the generalization to unknown, cluttered, scenes. Here we propose to perform VS based on visual features as in classical VS approaches but, contrary to the latter, we leverage recent breakthroughs in Deep Learning to automatically extract and match the visual features. By doing so, our approach enjoys the advantages from both worlds: (i) because our approach is based on visual features, it is able to steer the robot towards the object of interest even in presence of significant distraction in the background; (ii) because the features are automatically extracted and matched, our approach can easily and automatically generalize to unseen objects and scenes. In addition, we propose to use a render engine to synthesize the target image, which offers a further level of generalization. We demonstrate these advantages in a robotic grasping task, where the robot is able to steer, with high accuracy, towards the object to grasp, based simply on an image of the object rendered from the camera view corresponding to the desired robot grasping pose.
MoboTSP: Solving the Task Sequencing Problem for Mobile Manipulators
Nov 09, 2020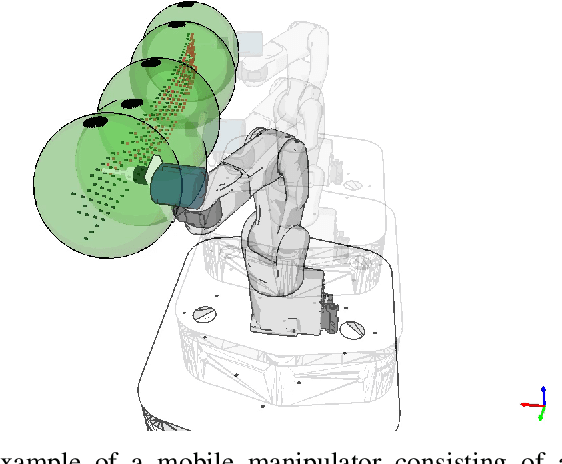
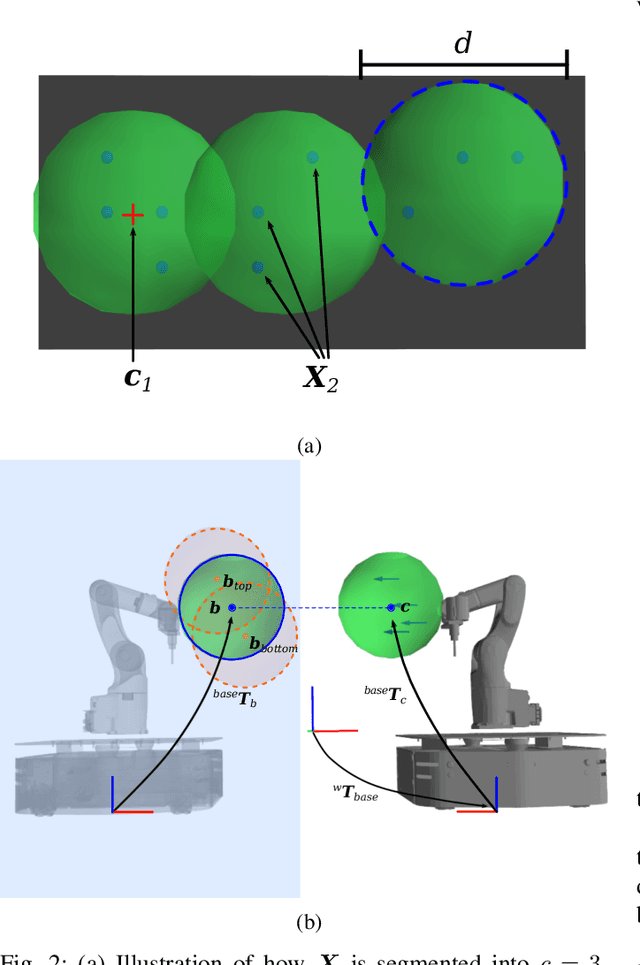

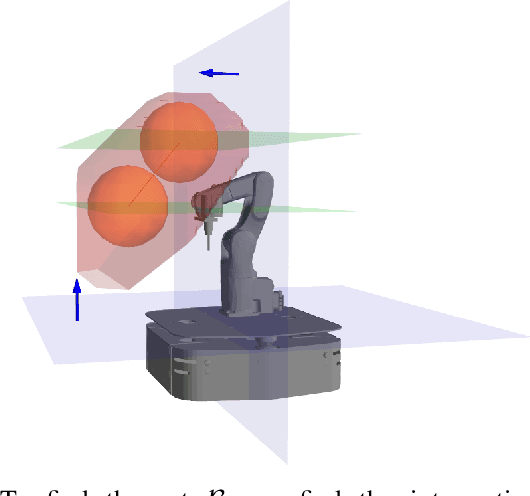
We introduce a new approach to tackle the mobile manipulator task sequencing problem. We leverage computational geometry, graph theory and combinatorial optimization to yield a principled method to segment the task-space targets into reachable clusters, analytically determine base pose for each cluster, and find task sequences that minimize the number of base movements and robot execution time. By clustering targets first and by doing so from first principles, our solution is more general and computationally efficient when compared to existing methods.
Development of a Robotic System for Automated Decaking of 3D-Printed Parts
Mar 11, 2020

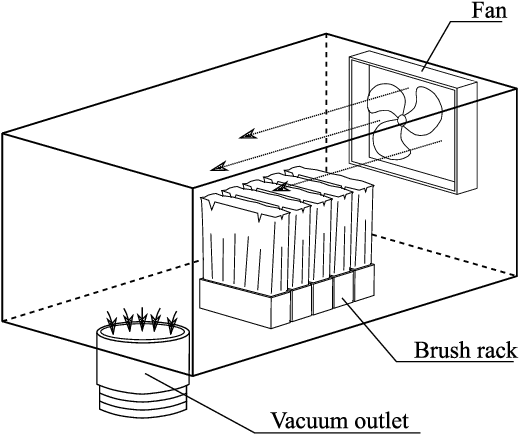
With the rapid rise of 3D-printing as a competitive mass manufacturing method, manual "decaking" - i.e. removing the residual powder that sticks to a 3D-printed part - has become a significant bottleneck. Here, we introduce, for the first time to our knowledge, a robotic system for automated decaking of 3D-printed parts. Combining Deep Learning for 3D perception, smart mechanical design, motion planning, and force control for industrial robots, we developed a system that can automatically decake parts in a fast and efficient way. Through a series of decaking experiments performed on parts printed by a Multi Jet Fusion printer, we demonstrated the feasibility of robotic decaking for 3D-printing-based mass manufacturing.
Locating Transparent Objects to Millimetre Accuracy
Mar 07, 2019
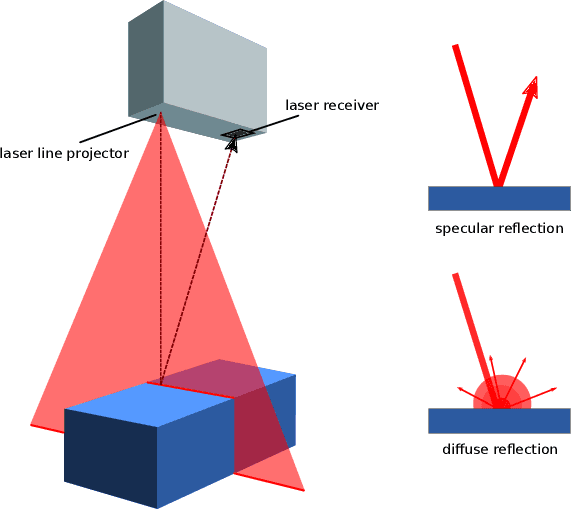
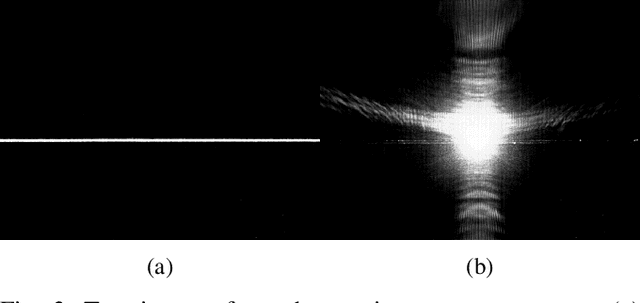

Transparent surfaces, such as glass, transmit most of the visible light that falls on them, making accurate pose estimation challenging. We propose a method to locate glass objects to millimetre accuracy using a simple Laser Range Finder (LRF) attached to the robot end-effector. The method, derived from a physical understanding of laser-glass interactions, consists of (i) sampling points on the glass border by looking at the glass surface from an angle of approximately 45 degrees, and (ii) performing Iterative Closest Point registration on the sampled points. We verify experimentally that the proposed method can locate a transparent, non-planar, side car glass to millimetre accuracy.