 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Price of Implicit Bias in Adversarially Robust Generalization
Jun 07, 2024



We study the implicit bias of optimization in robust empirical risk minimization (robust ERM) and its connection with robust generalization. In classification settings under adversarial perturbations with linear models, we study what type of regularization should ideally be applied for a given perturbation set to improve (robust) generalization. We then show that the implicit bias of optimization in robust ERM can significantly affect the robustness of the model and identify two ways this can happen; either through the optimization algorithm or the architecture. We verify our predictions in simulations with synthetic data and experimentally study the importance of implicit bias in robust ERM with deep neural networks.
The Adversarial Consistency of Surrogate Risks for Binary Classification
May 17, 2023We study the consistency of surrogate risks for robust binary classification. It is common to learn robust classifiers by adversarial training, which seeks to minimize the expected $0$-$1$ loss when each example can be maliciously corrupted within a small ball. We give a simple and complete characterization of the set of surrogate loss functions that are \emph{consistent}, i.e., that can replace the $0$-$1$ loss without affecting the minimizing sequences of the original adversarial risk, for any data distribution. We also prove a quantitative version of adversarial consistency for the $\rho$-margin loss. Our results reveal that the class of adversarially consistent surrogates is substantially smaller than in the standard setting, where many common surrogates are known to be consistent.
Calibration and Consistency of Adversarial Surrogate Losses
May 04, 2021

Adversarial robustness is an increasingly critical property of classifiers in applications. The design of robust algorithms relies on surrogate losses since the optimization of the adversarial loss with most hypothesis sets is NP-hard. But which surrogate losses should be used and when do they benefit from theoretical guarantees? We present an extensive study of this question, including a detailed analysis of the H-calibration and H-consistency of adversarial surrogate losses. We show that, under some general assumptions, convex loss functions, or the supremum-based convex losses often used in applications, are not H-calibrated for important hypothesis sets such as generalized linear models or one-layer neural networks. We then give a characterization of H-calibration and prove that some surrogate losses are indeed H-calibrated for the adversarial loss, with these hypothesis sets. Next, we show that H-calibration is not sufficient to guarantee consistency and prove that, in the absence of any distributional assumption, no continuous surrogate loss is consistent in the adversarial setting. This, in particular, proves that a claim presented in a COLT 2020 publication is inaccurate. (Calibration results there are correct modulo subtle definition differences, but the consistency claim does not hold.) Next, we identify natural conditions under which some surrogate losses that we describe in detail are H-consistent for hypothesis sets such as generalized linear models and one-layer neural networks. We also report a series of empirical results with simulated data, which show that many H-calibrated surrogate losses are indeed not H-consistent, and validate our theoretical assumptions.
On the Rademacher Complexity of Linear Hypothesis Sets
Jul 21, 2020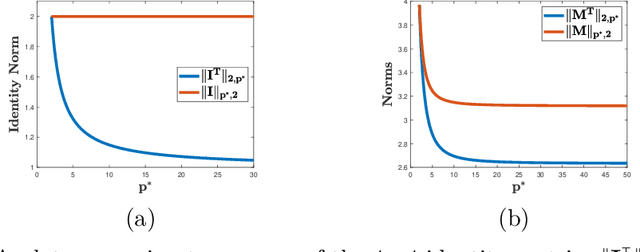
Linear predictors form a rich class of hypotheses used in a variety of learning algorithms. We present a tight analysis of the empirical Rademacher complexity of the family of linear hypothesis classes with weight vectors bounded in $\ell_p$-norm for any $p \geq 1$. This provides a tight analysis of generalization using these hypothesis sets and helps derive sharp data-dependent learning guarantees. We give both upper and lower bounds on the Rademacher complexity of these families and show that our bounds improve upon or match existing bounds, which are known only for $1 \leq p \leq 2$.
Adversarial Learning Guarantees for Linear Hypotheses and Neural Networks
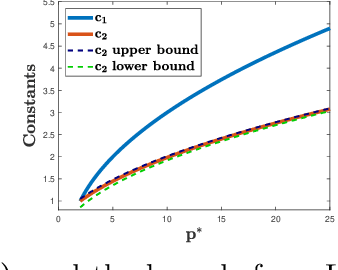
Apr 28, 2020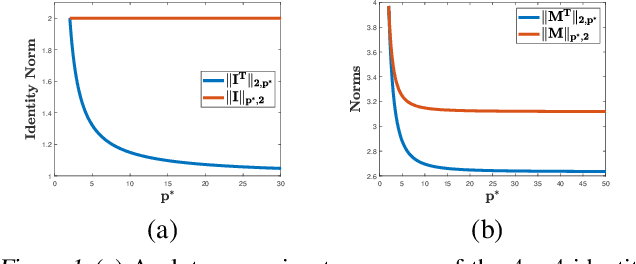
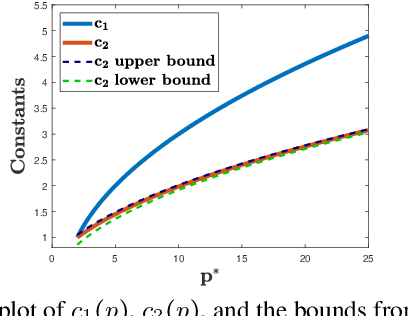
Adversarial or test time robustness measures the susceptibility of a classifier to perturbations to the test input. While there has been a flurry of recent work on designing defenses against such perturbations, the theory of adversarial robustness is not well understood. In order to make progress on this, we focus on the problem of understanding generalization in adversarial settings, via the lens of Rademacher complexity. We give upper and lower bounds for the adversarial empirical Rademacher complexity of linear hypotheses with adversarial perturbations measured in $l_r$-norm for an arbitrary $r \geq 1$. This generalizes the recent result of [Yin et al.'19] that studies the case of $r = \infty$, and provides a finer analysis of the dependence on the input dimensionality as compared to the recent work of [Khim and Loh'19] on linear hypothesis classes. We then extend our analysis to provide Rademacher complexity lower and upper bounds for a single ReLU unit. Finally, we give adversarial Rademacher complexity bounds for feed-forward neural networks with one hidden layer. Unlike previous works we directly provide bounds on the adversarial Rademacher complexity of the given network, as opposed to a bound on a surrogate. A by-product of our analysis also leads to tighter bounds for the Rademacher complexity of linear hypotheses, for which we give a detailed analysis and present a comparison with existing bounds.