 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart of speech and gramset tagging algorithms for unknown words based on morphological dictionaries of the Veps and Karelian languages
Mar 22, 2021
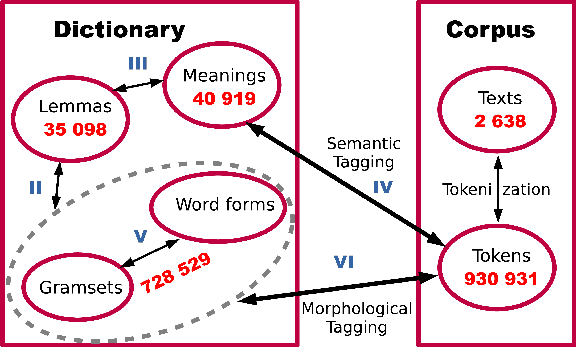

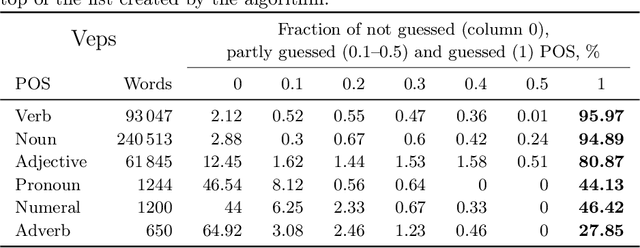
This research devoted to the low-resource Veps and Karelian languages. Algorithms for assigning part of speech tags to words and grammatical properties to words are presented in the article. These algorithms use our morphological dictionaries, where the lemma, part of speech and a set of grammatical features (gramset) are known for each word form. The algorithms are based on the analogy hypothesis that words with the same suffixes are likely to have the same inflectional models, the same part of speech and gramset. The accuracy of these algorithms were evaluated and compared. 313 thousand Vepsian and 66 thousand Karelian words were used to verify the accuracy of these algorithms. The special functions were designed to assess the quality of results of the developed algorithms. 92.4% of Vepsian words and 86.8% of Karelian words were assigned a correct part of speech by the developed algorithm. 95.3% of Vepsian words and 90.7% of Karelian words were assigned a correct gramset by our algorithm. Morphological and semantic tagging of texts, which are closely related and inseparable in our corpus processes, are described in the paper.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020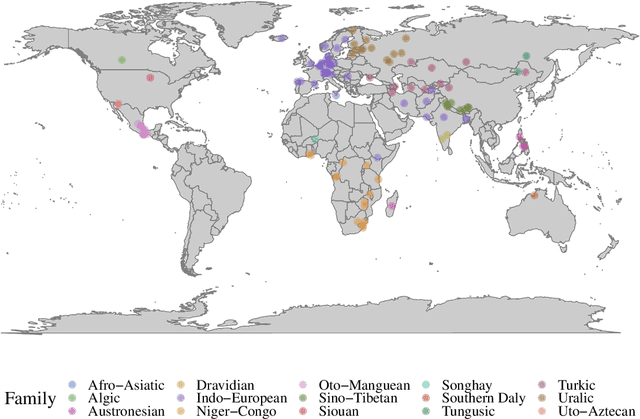
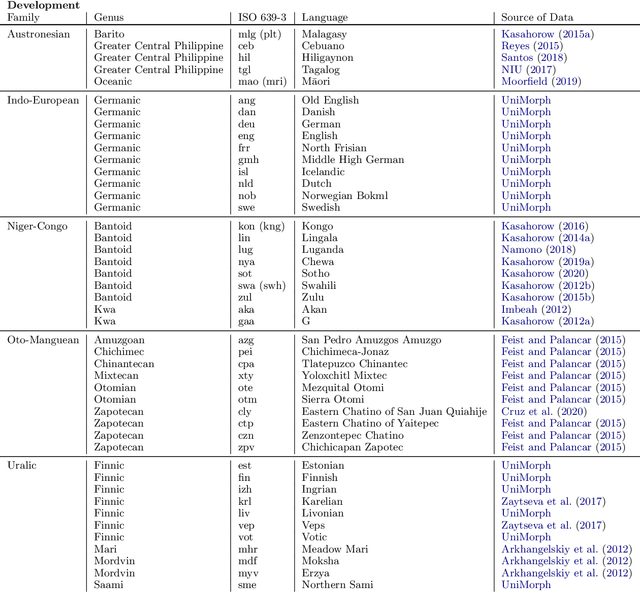
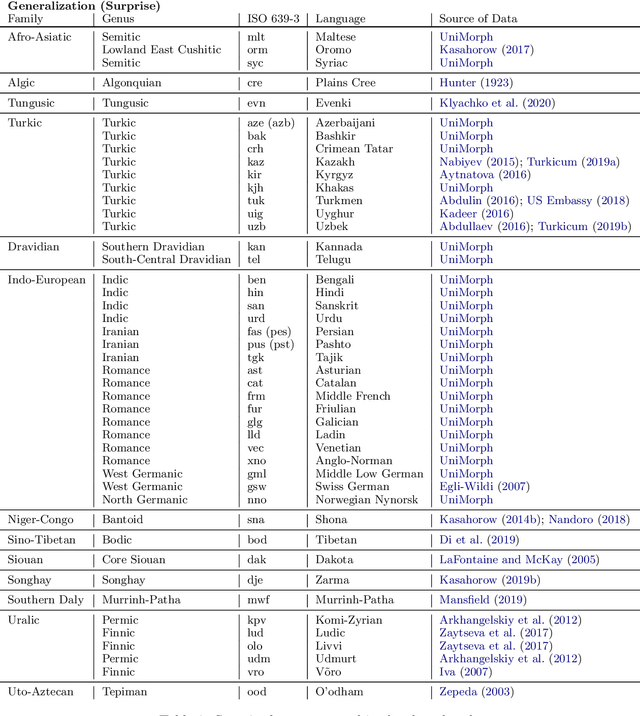
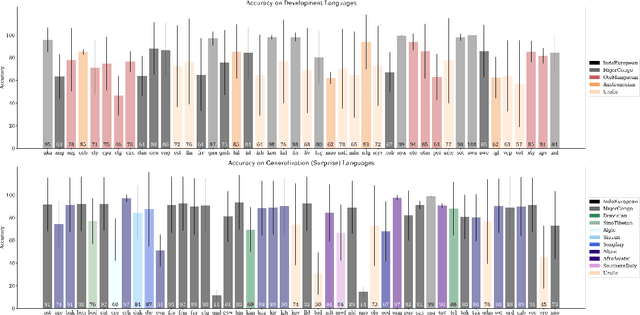
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.
WSD algorithm based on a new method of vector-word contexts proximity calculation via epsilon-filtration
Jun 18, 2018
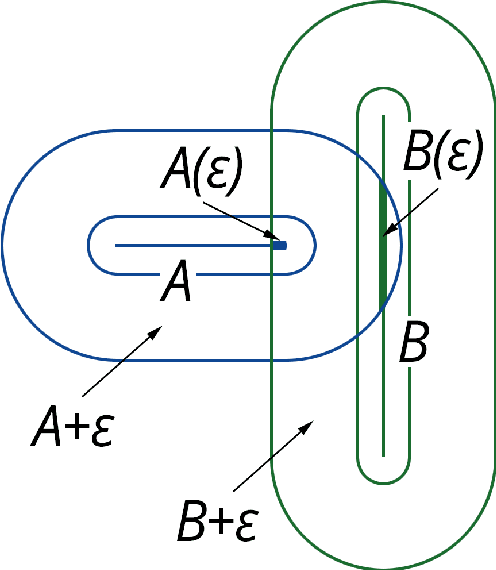

The problem of word sense disambiguation (WSD) is considered in the article. Given a set of synonyms (synsets) and sentences with these synonyms. It is necessary to select the meaning of the word in the sentence automatically. 1285 sentences were tagged by experts, namely, one of the dictionary meanings was selected by experts for target words. To solve the WSD-problem, an algorithm based on a new method of vector-word contexts proximity calculation is proposed. In order to achieve higher accuracy, a preliminary epsilon-filtering of words is performed, both in the sentence and in the set of synonyms. An extensive program of experiments was carried out. Four algorithms are implemented, including a new algorithm. Experiments have shown that in a number of cases the new algorithm shows better results. The developed software and the tagged corpus have an open license and are available online. Wiktionary and Wikisource are used. A brief description of this work can be viewed in slides (https://goo.gl/9ak6Gt). Video lecture in Russian on this research is available online (https://youtu.be/-DLmRkepf58).
* 15 pages, 1 table, 15 figures, accepted in the journal Transactions of Karelian Research Centre of the Russian Academy of Sciences