 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Open corpus of the Veps and Karelian languages: overview and applications
Jun 08, 2022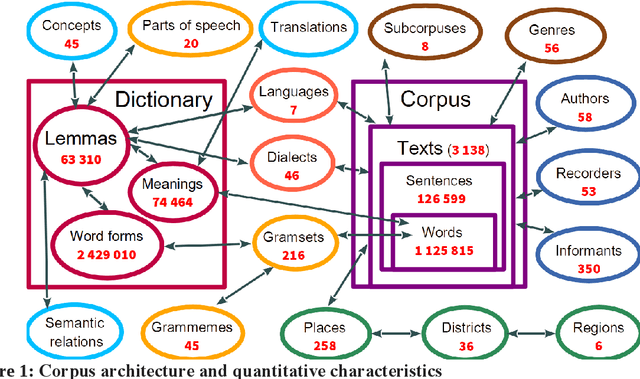
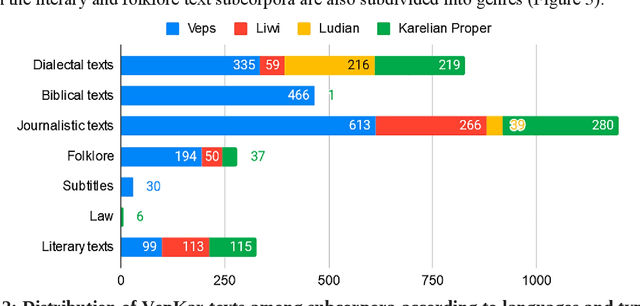
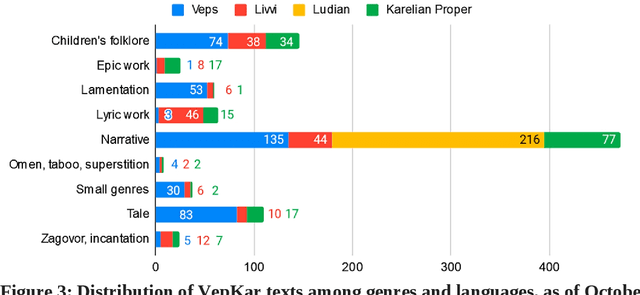
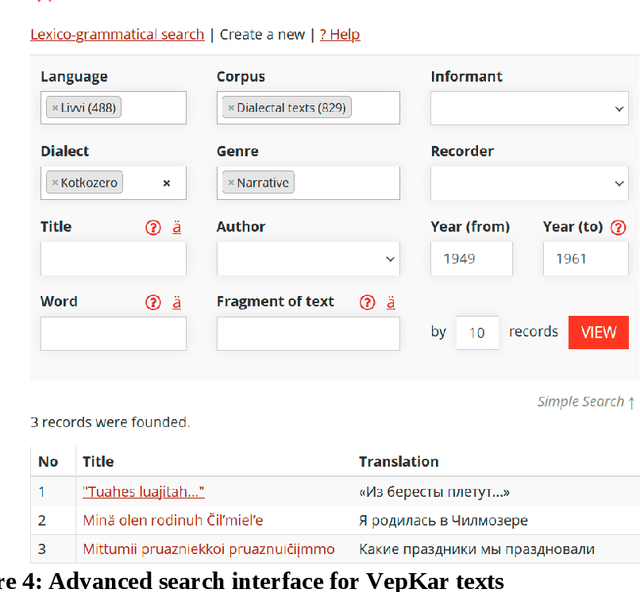
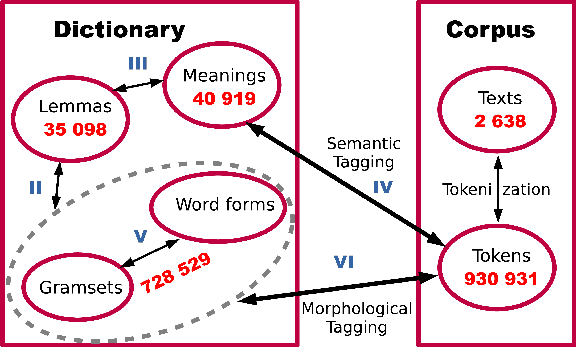
A growing priority in the study of Baltic-Finnic languages of the Republic of Karelia has been the methods and tools of corpus linguistics. Since 2016, linguists, mathematicians, and programmers at the Karelian Research Centre have been working with the Open Corpus of the Veps and Karelian Languages (VepKar), which is an extension of the Veps Corpus created in 2009. The VepKar corpus comprises texts in Karelian and Veps, multifunctional dictionaries linked to them, and software with an advanced system of search using various criteria of the texts (language, genre, etc.) and numerous linguistic categories (lexical and grammatical search in texts was implemented thanks to the generator of word forms that we created earlier). A corpus of 3000 texts was compiled, texts were uploaded and marked up, the system for classifying texts into languages, dialects, types and genres was introduced, and the word-form generator was created. Future plans include developing a speech module for working with audio recordings and a syntactic tagging module using morphological analysis outputs. Owing to continuous functional advancements in the corpus manager and ongoing VepKar enrichment with new material and text markup, users can handle a wide range of scientific and applied tasks. In creating the universal national VepKar corpus, its developers and managers strive to preserve and exhibit as fully as possible the state of the Veps and Karelian languages in the 19th-21st centuries.
* 9 pages, 9 figures, published in the journal
Part of speech and gramset tagging algorithms for unknown words based on morphological dictionaries of the Veps and Karelian languages
Mar 22, 2021

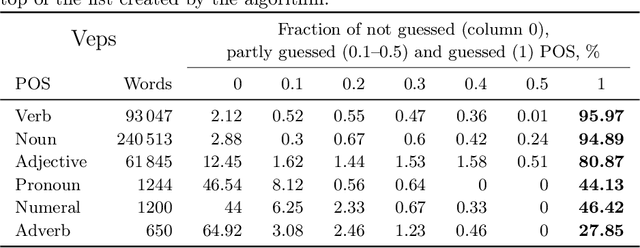
This research devoted to the low-resource Veps and Karelian languages. Algorithms for assigning part of speech tags to words and grammatical properties to words are presented in the article. These algorithms use our morphological dictionaries, where the lemma, part of speech and a set of grammatical features (gramset) are known for each word form. The algorithms are based on the analogy hypothesis that words with the same suffixes are likely to have the same inflectional models, the same part of speech and gramset. The accuracy of these algorithms were evaluated and compared. 313 thousand Vepsian and 66 thousand Karelian words were used to verify the accuracy of these algorithms. The special functions were designed to assess the quality of results of the developed algorithms. 92.4% of Vepsian words and 86.8% of Karelian words were assigned a correct part of speech by the developed algorithm. 95.3% of Vepsian words and 90.7% of Karelian words were assigned a correct gramset by our algorithm. Morphological and semantic tagging of texts, which are closely related and inseparable in our corpus processes, are described in the paper.