 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCM-SD: A Large Dataset for Syndrome Differentiation in Traditional Chinese Medicine
Mar 21, 2022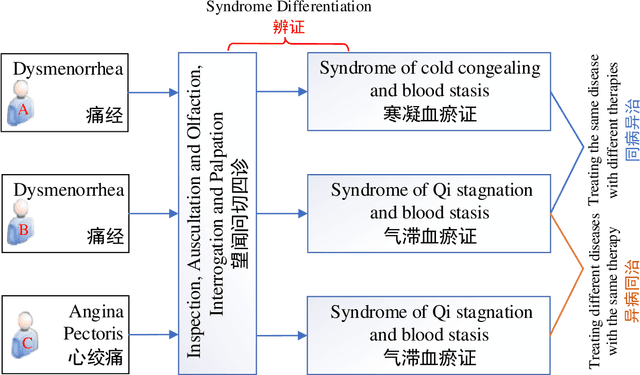
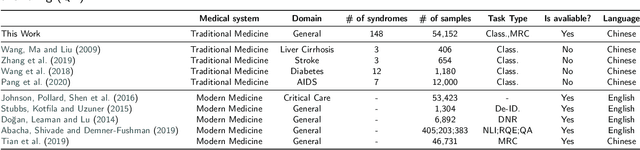

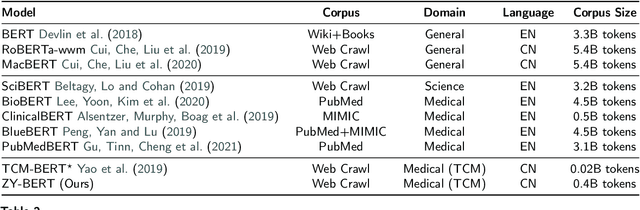
Traditional Chinese Medicine (TCM) is a natural, safe, and effective therapy that has spread and been applied worldwide. The unique TCM diagnosis and treatment system requires a comprehensive analysis of a patient's symptoms hidden in the clinical record written in free text. Prior studies have shown that this system can be informationized and intelligentized with the aid of artificial intelligence (AI) technology, such as natural language processing (NLP). However, existing datasets are not of sufficient quality nor quantity to support the further development of data-driven AI technology in TCM. Therefore, in this paper, we focus on the core task of the TCM diagnosis and treatment system -- syndrome differentiation (SD) -- and we introduce the first public large-scale dataset for SD, called TCM-SD. Our dataset contains 54,152 real-world clinical records covering 148 syndromes. Furthermore, we collect a large-scale unlabelled textual corpus in the field of TCM and propose a domain-specific pre-trained language model, called ZY-BERT. We conducted experiments using deep neural networks to establish a strong performance baseline, reveal various challenges in SD, and prove the potential of domain-specific pre-trained language model. Our study and analysis reveal opportunities for incorporating computer science and linguistics knowledge to explore the empirical validity of TCM theories.
Ask to Understand: Question Generation for Multi-hop Question Answering
Mar 17, 2022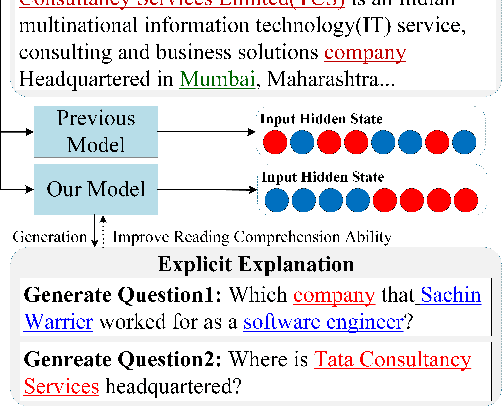
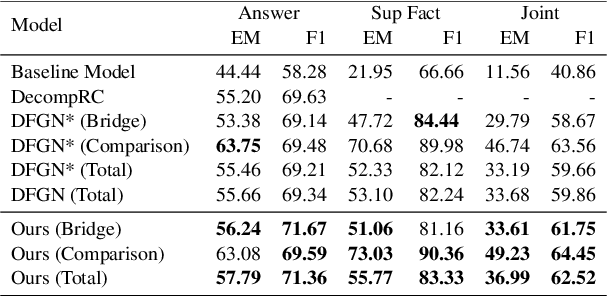

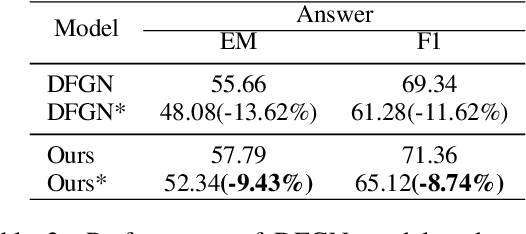
Multi-hop Question Answering (QA) requires the machine to answer complex questions by finding scattering clues and reasoning from multiple documents. Graph Network (GN) and Question Decomposition (QD) are two common approaches at present. The former uses the "black-box" reasoning process to capture the potential relationship between entities and sentences, thus achieving good performance. At the same time, the latter provides a clear reasoning logical route by decomposing multi-hop questions into simple single-hop sub-questions. In this paper, we propose a novel method to complete multi-hop QA from the perspective of Question Generation (QG). Specifically, we carefully design an end-to-end QG module on the basis of a classical QA module, which could help the model understand the context by asking inherently logical sub-questions, thus inheriting interpretability from the QD-based method and showing superior performance. Experiments on the HotpotQA dataset demonstrate that the effectiveness of our proposed QG module, human evaluation further clarifies its interpretability quantitatively, and thorough analysis shows that the QG module could generate better sub-questions than QD methods in terms of fluency, consistency, and diversity.
Prediction or Comparison: Toward Interpretable Qualitative Reasoning
Jun 04, 2021
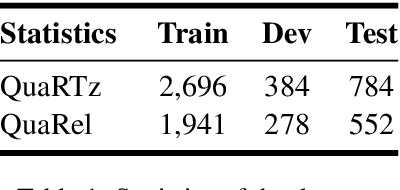
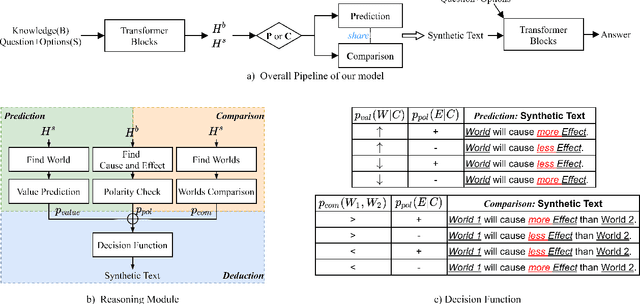
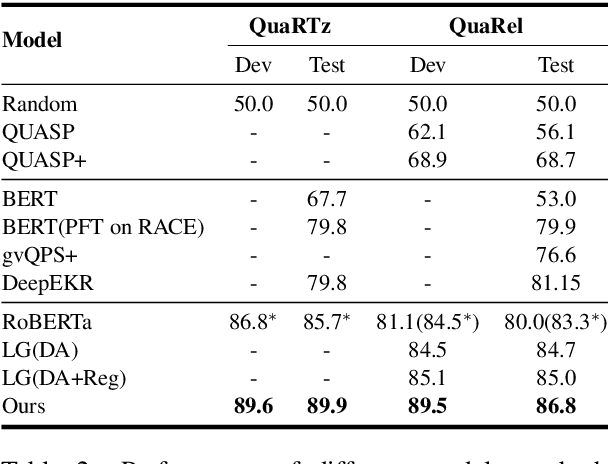
Qualitative relationships illustrate how changing one property (e.g., moving velocity) affects another (e.g., kinetic energy) and constitutes a considerable portion of textual knowledge. Current approaches use either semantic parsers to transform natural language inputs into logical expressions or a "black-box" model to solve them in one step. The former has a limited application range, while the latter lacks interpretability. In this work, we categorize qualitative reasoning tasks into two types: prediction and comparison. In particular, we adopt neural network modules trained in an end-to-end manner to simulate the two reasoning processes. Experiments on two qualitative reasoning question answering datasets, QuaRTz and QuaRel, show our methods' effectiveness and generalization capability, and the intermediate outputs provided by the modules make the reasoning process interpretable.
Towards Interpretable Reasoning over Paragraph Effects in Situation
Oct 03, 2020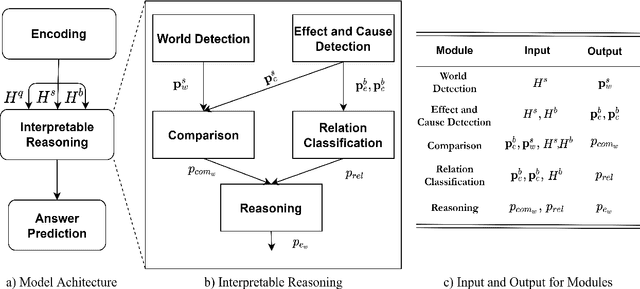
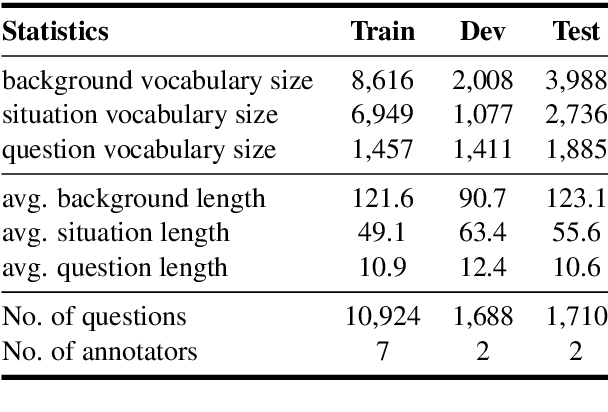
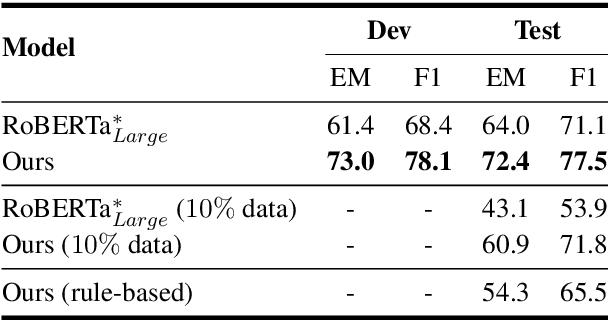

We focus on the task of reasoning over paragraph effects in situation, which requires a model to understand the cause and effect described in a background paragraph, and apply the knowledge to a novel situation. Existing works ignore the complicated reasoning process and solve it with a one-step "black box" model. Inspired by human cognitive processes, in this paper we propose a sequential approach for this task which explicitly models each step of the reasoning process with neural network modules. In particular, five reasoning modules are designed and learned in an end-to-end manner, which leads to a more interpretable model. Experimental results on the ROPES dataset demonstrate the effectiveness and explainability of our proposed approach.