 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascading Robustness Verification: Toward Efficient Model-Agnostic Certification
Feb 04, 2026Certifying neural network robustness against adversarial examples is challenging, as formal guarantees often require solving non-convex problems. Hence, incomplete verifiers are widely used because they scale efficiently and substantially reduce the cost of robustness verification compared to complete methods. However, relying on a single verifier can underestimate robustness because of loose approximations or misalignment with training methods. In this work, we propose Cascading Robustness Verification (CRV), which goes beyond an engineering improvement by exposing fundamental limitations of existing robustness metric and introducing a framework that enhances both reliability and efficiency. CRV is a model-agnostic verifier, meaning that its robustness guarantees are independent of the model's training process. The key insight behind the CRV framework is that, when using multiple verification methods, an input is certifiably robust if at least one method certifies it as robust. Rather than relying solely on a single verifier with a fixed constraint set, CRV progressively applies multiple verifiers to balance the tightness of the bound and computational cost. Starting with the least expensive method, CRV halts as soon as an input is certified as robust; otherwise, it proceeds to more expensive methods. For computationally expensive methods, we introduce a Stepwise Relaxation Algorithm (SR) that incrementally adds constraints and checks for certification at each step, thereby avoiding unnecessary computation. Our theoretical analysis demonstrates that CRV achieves equal or higher verified accuracy compared to powerful but computationally expensive incomplete verifiers in the cascade, while significantly reducing verification overhead. Empirical results confirm that CRV certifies at least as many inputs as benchmark approaches, while improving runtime efficiency by up to ~90%.
Two-Hop Age of Information Scheduling for Multi-UAV Assisted Mobile Edge Computing: FRL vs MADDPG
Jun 19, 2022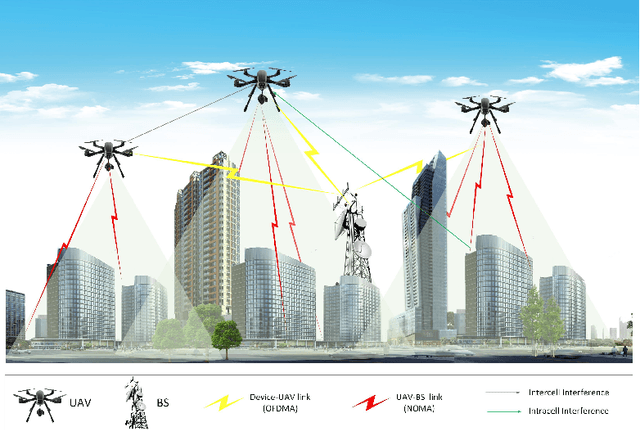
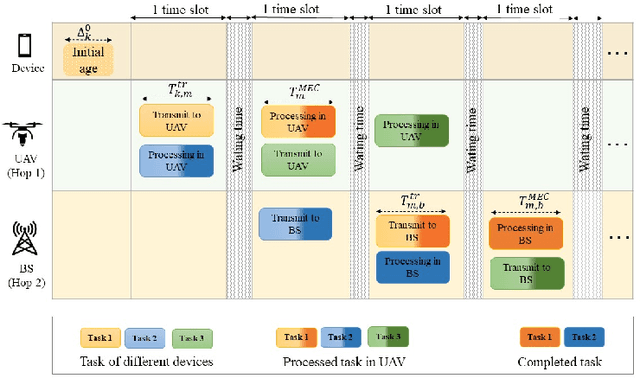
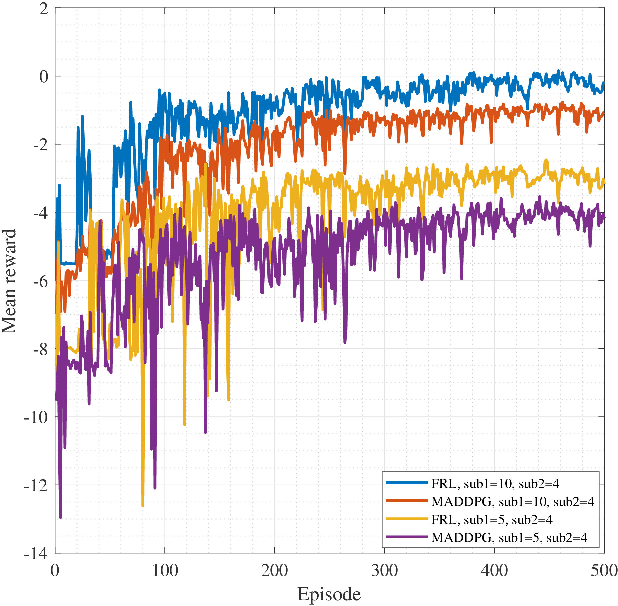
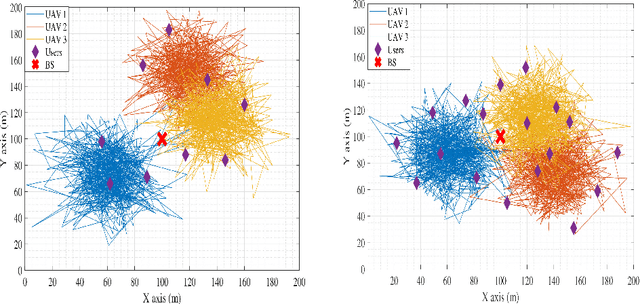
In this work, we adopt the emerging technology of mobile edge computing (MEC) in the Unmanned aerial vehicles (UAVs) for communication-computing systems, to optimize the age of information (AoI) in the network. We assume that tasks are processed jointly on UAVs and BS to enhance edge performance with limited connectivity and computing. Using UAVs and BS jointly with MEC can reduce AoI on the network. To maintain the freshness of the tasks, we formulate the AoI minimization in two-hop communication framework, the first hop at the UAVs and the second hop at the BS. To approach the challenge, we optimize the problem using a deep reinforcement learning (DRL) framework, called federated reinforcement learning (FRL). In our network we have two types of agents with different states and actions but with the same policy. Our FRL enables us to handle the two-step AoI minimization and UAV trajectory problems. In addition, we compare our proposed algorithm, which has a centralized processing unit to update the weights, with fully decentralized multi-agent deep deterministic policy gradient (MADDPG), which enhances the agent's performance. As a result, the suggested algorithm outperforms the MADDPG by about 38\%