 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny and Efficient Model for the Edge Detection Generalization
Aug 12, 2023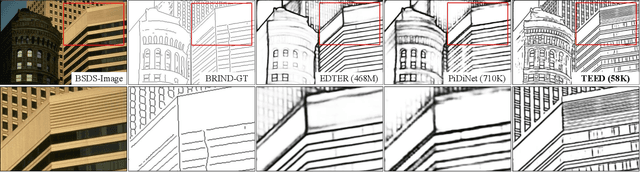
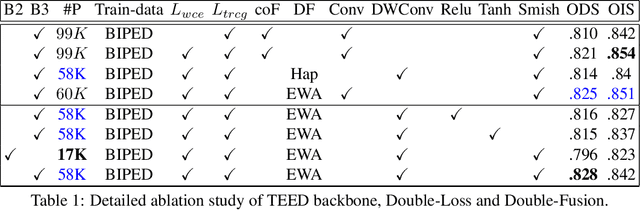
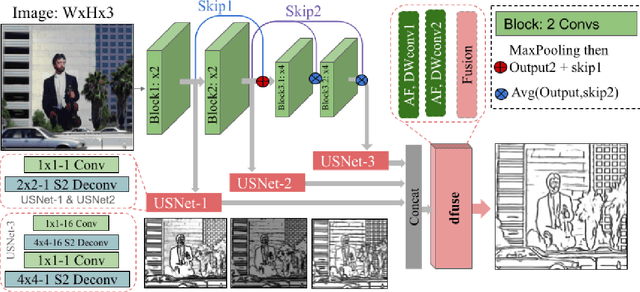

Most high-level computer vision tasks rely on low-level image operations as their initial processes. Operations such as edge detection, image enhancement, and super-resolution, provide the foundations for higher level image analysis. In this work we address the edge detection considering three main objectives: simplicity, efficiency, and generalization since current state-of-the-art (SOTA) edge detection models are increased in complexity for better accuracy. To achieve this, we present Tiny and Efficient Edge Detector (TEED), a light convolutional neural network with only $58K$ parameters, less than $0.2$% of the state-of-the-art models. Training on the BIPED dataset takes $less than 30 minutes$, with each epoch requiring $less than 5 minutes$. Our proposed model is easy to train and it quickly converges within very first few epochs, while the predicted edge-maps are crisp and of high quality. Additionally, we propose a new dataset to test the generalization of edge detection, which comprises samples from popular images used in edge detection and image segmentation. The source code is available in https://github.com/xavysp/TEED.
Efficient texture mapping via a non-iterative global texture alignment
Nov 02, 2020
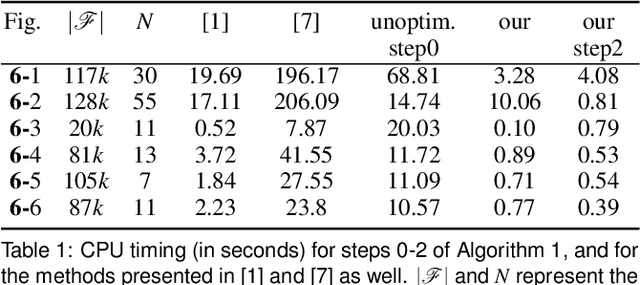


Texture reconstruction techniques generally suffer from the errors in keyframe poses. We present a non-iterative method for seamless texture reconstruction of a given 3D scene. Our method finds the best texture alignment in a single shot using a global optimisation framework. First, we automatically select the best keyframe to texture each face of the mesh. This leads to a decomposition of the mesh into small groups of connected faces associated to a same keyframe. We call such groups fragments. Then, we propose a geometry-aware matching technique between the 3D keypoints extracted around the fragment borders, where the matching zone is controlled by the margin size. These constraints lead to a least squares (LS) model for finding the optimal alignment. Finally, visual seams are further reduced by applying a fast colour correction. In contrast to pixel-wise methods, we find the optimal alignment by solving a sparse system of linear equations, which is very fast and non-iterative. Experimental results demonstrate low computational complexity and outperformance compared to other alignment methods.
IntrinSeqNet: Learning to Estimate the Reflectance from Varying Illumination
Jun 13, 2019



Intrinsic image decomposition describes an image based on its reflectance and shading components. In this paper we tackle the problem of estimating the diffuse reflectance from a sequence of images captured from a fixed viewpoint under various illuminations. To this end we propose a deep learning approach to avoid heuristics and strong assumptions on the reflectance prior. We compare two network architectures: one classic 'U' shaped Convolutional Neural Network (CNN) and a Recurrent Neural Network (RNN) composed of Convolutional Gated Recurrent Units (CGRU). We train our networks on a new dataset specifically designed for the task of intrinsic decomposition from sequences. We test our networks on MIT and BigTime datasets and outperform state-of-the-art algorithms both qualitatively and quantitatively.
Towards Principled Design of Deep Convolutional Networks: Introducing SimpNet
Feb 17, 2018


Major winning Convolutional Neural Networks (CNNs), such as VGGNet, ResNet, DenseNet, \etc, include tens to hundreds of millions of parameters, which impose considerable computation and memory overheads. This limits their practical usage in training and optimizing for real-world applications. On the contrary, light-weight architectures, such as SqueezeNet, are being proposed to address this issue. However, they mainly suffer from low accuracy, as they have compromised between the processing power and efficiency. These inefficiencies mostly stem from following an ad-hoc designing procedure. In this work, we discuss and propose several crucial design principles for an efficient architecture design and elaborate intuitions concerning different aspects of the design procedure. Furthermore, we introduce a new layer called {\it SAF-pooling} to improve the generalization power of the network while keeping it simple by choosing best features. Based on such principles, we propose a simple architecture called {\it SimpNet}. We empirically show that SimpNet provides a good trade-off between the computation/memory efficiency and the accuracy solely based on these primitive but crucial principles. SimpNet outperforms the deeper and more complex architectures such as VGGNet, ResNet, WideResidualNet \etc, on several well-known benchmarks, while having 2 to 25 times fewer number of parameters and operations. We obtain state-of-the-art results (in terms of a balance between the accuracy and the number of involved parameters) on standard datasets, such as CIFAR10, CIFAR100, MNIST and SVHN. The implementations are available at \href{url}{https://github.com/Coderx7/SimpNet}.
Lets keep it simple, Using simple architectures to outperform deeper and more complex architectures
Feb 14, 2018


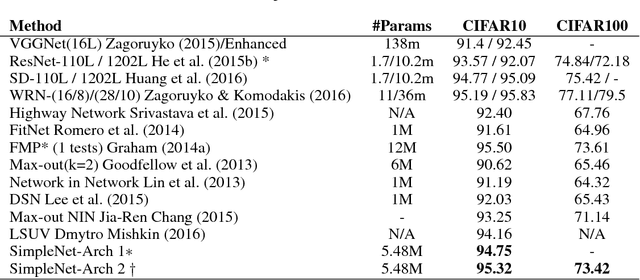
Major winning Convolutional Neural Networks (CNNs), such as AlexNet, VGGNet, ResNet, GoogleNet, include tens to hundreds of millions of parameters, which impose considerable computation and memory overhead. This limits their practical use for training, optimization and memory efficiency. On the contrary, light-weight architectures, being proposed to address this issue, mainly suffer from low accuracy. These inefficiencies mostly stem from following an ad hoc procedure. We propose a simple architecture, called SimpleNet, based on a set of designing principles, with which we empirically show, a well-crafted yet simple and reasonably deep architecture can perform on par with deeper and more complex architectures. SimpleNet provides a good tradeoff between the computation/memory efficiency and the accuracy. Our simple 13-layer architecture outperforms most of the deeper and complex architectures to date such as VGGNet, ResNet, and GoogleNet on several well-known benchmarks while having 2 to 25 times fewer number of parameters and operations. This makes it very handy for embedded system or system with computational and memory limitations. We achieved state-of-the-art result on CIFAR10 outperforming several heavier architectures, near state of the art on MNIST and competitive results on CIFAR100 and SVHN. Models are made available at: https://github.com/Coderx7/SimpleNet