 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comprehensive study on Frequent Pattern Mining and Clustering categories for topic detection in Persian text stream
Mar 15, 2024



Topic detection is a complex process and depends on language because it somehow needs to analyze text. There have been few studies on topic detection in Persian, and the existing algorithms are not remarkable. Therefore, we aimed to study topic detection in Persian. The objectives of this study are: 1) to conduct an extensive study on the best algorithms for topic detection, 2) to identify necessary adaptations to make these algorithms suitable for the Persian language, and 3) to evaluate their performance on Persian social network texts. To achieve these objectives, we have formulated two research questions: First, considering the lack of research in Persian, what modifications should be made to existing frameworks, especially those developed in English, to make them compatible with Persian? Second, how do these algorithms perform, and which one is superior? There are various topic detection methods that can be categorized into different categories. Frequent pattern and clustering are selected for this research, and a hybrid of both is proposed as a new category. Then, ten methods from these three categories are selected. All of them are re-implemented from scratch, changed, and adapted with Persian. These ten methods encompass different types of topic detection methods and have shown good performance in English. The text of Persian social network posts is used as the dataset. Additionally, a new multiclass evaluation criterion, called FS, is used in this paper for the first time in the field of topic detection. Approximately 1.4 billion tokens are processed during experiments. The results indicate that if we are searching for keyword-topics that are easily understandable by humans, the hybrid category is better. However, if the aim is to cluster posts for further analysis, the frequent pattern category is more suitable.
A Comparative Study on Transfer Learning and Distance Metrics in Semantic Clustering over the COVID-19 Tweets
Nov 16, 2021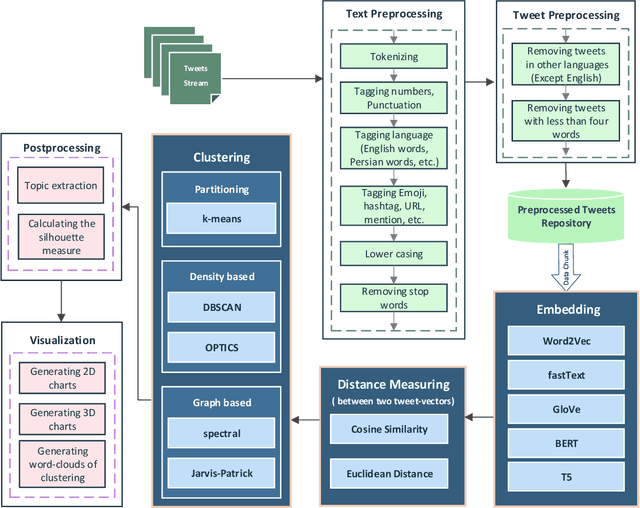

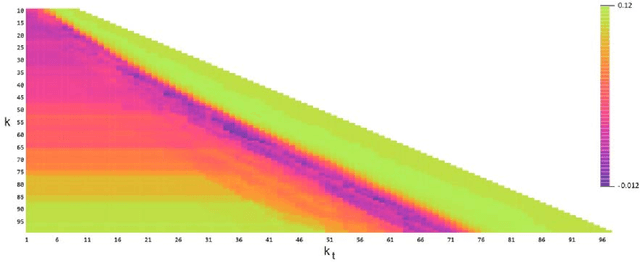
This paper is a comparison study in the context of Topic Detection on COVID-19 data. There are various approaches for Topic Detection, among which the Clustering approach is selected in this paper. Clustering requires distance and calculating distance needs embedding. The aim of this research is to simultaneously study the three factors of embedding methods, distance metrics and clustering methods and their interaction. A dataset including one-month tweets collected with COVID-19-related hashtags is used for this study. Five methods, from earlier to new methods, are selected among the embedding methods: Word2Vec, fastText, GloVe, BERT and T5. Five clustering methods are investigated in this paper that are: k-means, DBSCAN, OPTICS, spectral and Jarvis-Patrick. Euclidian distance and Cosine distance as the most important distance metrics in this field are also examined. First, more than 7,500 tests are performed to tune the parameters. Then, all the different combinations of embedding methods with distance metrics and clustering methods are investigated by silhouette metric. The number of these combinations is 50 cases. First, the results of these 50 tests are examined. Then, the rank of each method is taken into account in all the tests of that method. Finally, the major variables of the research (embedding methods, distance metrics and clustering methods) are studied separately. Averaging is performed over the control variables to neutralize their effect. The experimental results show that T5 strongly outperforms other embedding methods in terms of silhouette metric. In terms of distance metrics, cosine distance is weakly better. DBSCAN is also superior to other methods in terms of clustering methods.
Transfer-based adaptive tree for multimodal sentiment analysis based on user latent aspects
Jun 27, 2021
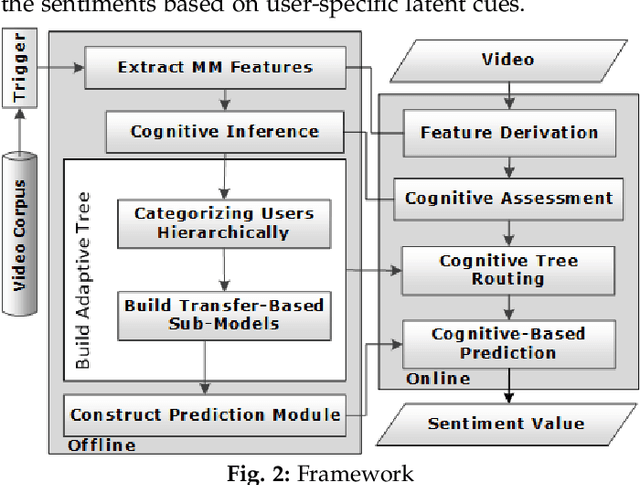

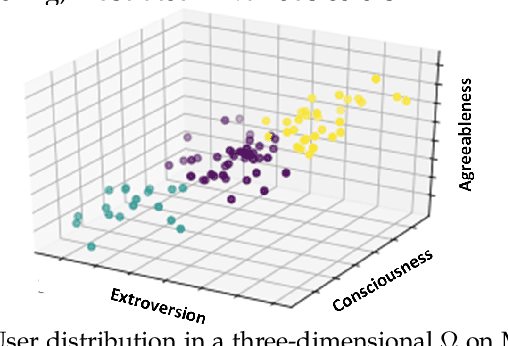
Multimodal sentiment analysis benefits various applications such as human-computer interaction and recommendation systems. It aims to infer the users' bipolar ideas using visual, textual, and acoustic signals. Although researchers affirm the association between cognitive cues and emotional manifestations, most of the current multimodal approaches in sentiment analysis disregard user-specific aspects. To tackle this issue, we devise a novel method to perform multimodal sentiment prediction using cognitive cues, such as personality. Our framework constructs an adaptive tree by hierarchically dividing users and trains the LSTM-based submodels, utilizing an attention-based fusion to transfer cognitive-oriented knowledge within the tree. Subsequently, the framework consumes the conclusive agglomerative knowledge from the adaptive tree to predict final sentiments. We also devise a dynamic dropout method to facilitate data sharing between neighboring nodes, reducing data sparsity. The empirical results on real-world datasets determine that our proposed model for sentiment prediction can surpass trending rivals. Moreover, compared to other ensemble approaches, the proposed transfer-based algorithm can better utilize the latent cognitive cues and foster the prediction outcomes. Based on the given extrinsic and intrinsic analysis results, we note that compared to other theoretical-based techniques, the proposed hierarchical clustering approach can better group the users within the adaptive tree.
Cognitive-aware Short-text Understanding for Inferring Professions
Jun 04, 2021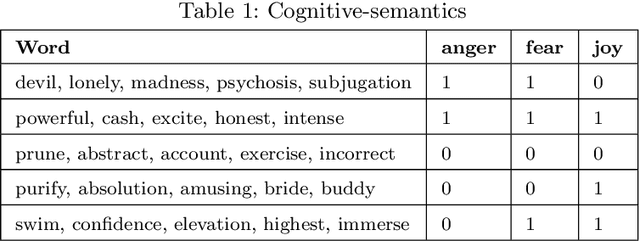
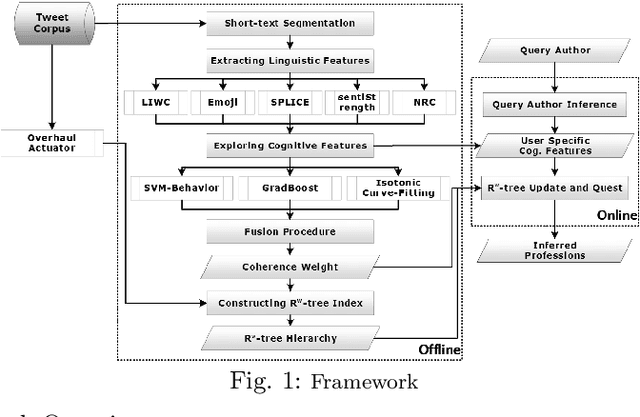
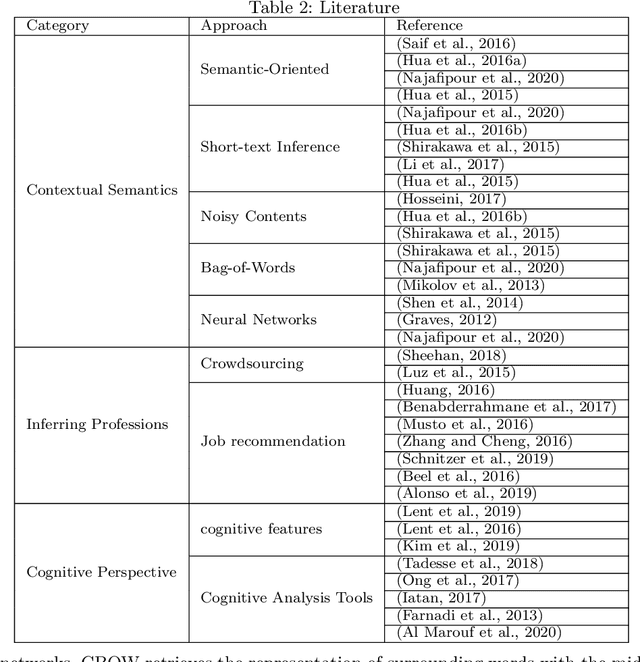
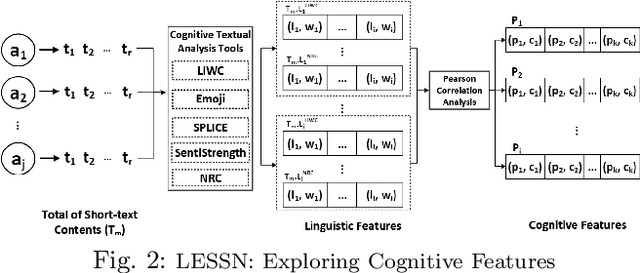
Leveraging short-text contents to estimate the occupation of microblog authors has significant gains in many applications. Yet challenges abound. Firstly brief textual contents come with excessive lexical noise that makes the inference problem challenging. Secondly, cognitive-semantics are not evident, and important linguistic features are latent in short-text contents. Thirdly, it is hard to measure the correlation between the cognitive short-text semantics and the features pertaining various occupations. We argue that the multi-aspect cognitive features are needed to correctly associate short-text contents to a particular job and discover suitable people for the careers. To this end, we devise a novel framework that on the one hand, can infer short-text contents and exploit cognitive features, and on the other hand, fuses various adopted novel algorithms, such as curve fitting, support vector, and boosting modules to better predict the occupation of the authors. The final estimation module manufactures the $R^w$-tree via coherence weight to tune the best outcome in the inferring process. We conduct comprehensive experiments on real-life Twitter data. The experimental results show that compared to other rivals, our cognitive multi-aspect model can achieve a higher performance in the career estimation procedure, where it is inevitable to neglect the contextual semantics of users.
EmoDNN: Understanding emotions from short texts through a deep neural network ensemble
Jun 03, 2021

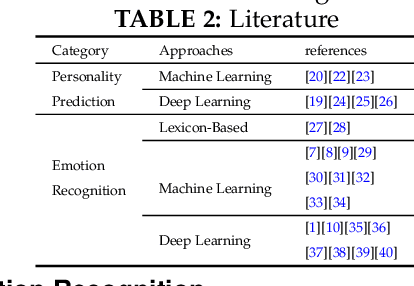

The latent knowledge in the emotions and the opinions of the individuals that are manifested via social networks are crucial to numerous applications including social management, dynamical processes, and public security. Affective computing, as an interdisciplinary research field, linking artificial intelligence to cognitive inference, is capable to exploit emotion-oriented knowledge from brief contents. The textual contents convey hidden information such as personality and cognition about corresponding authors that can determine both correlations and variations between users. Emotion recognition from brief contents should embrace the contrast between authors where the differences in personality and cognition can be traced within emotional expressions. To tackle this challenge, we devise a framework that, on the one hand, infers latent individual aspects, from brief contents and, on the other hand, presents a novel ensemble classifier equipped with dynamic dropout convnets to extract emotions from textual context. To categorize short text contents, our proposed method conjointly leverages cognitive factors and exploits hidden information. We utilize the outcome vectors in a novel embedding model to foster emotion-pertinent features that are collectively assembled by lexicon inductions. Experimental results show that compared to other competitors, our proposed model can achieve a higher performance in recognizing emotion from noisy contents.
SoulMate: Short-text author linking through Multi-aspect temporal-textual embedding
Oct 27, 2019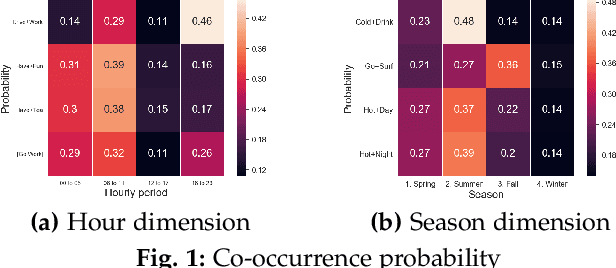

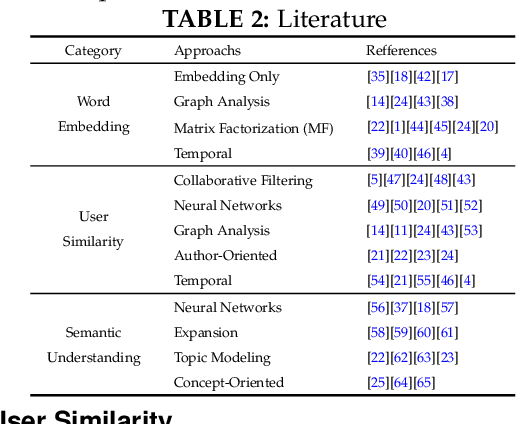
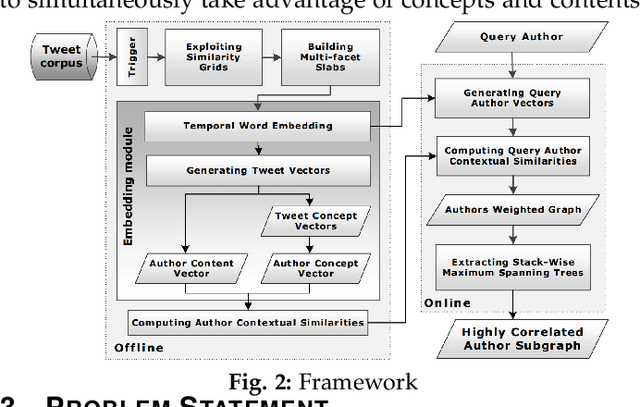
Linking authors of short-text contents has important usages in many applications, including Named Entity Recognition (NER) and human community detection. However, certain challenges lie ahead. Firstly, the input short-text contents are noisy, ambiguous, and do not follow the grammatical rules. Secondly, traditional text mining methods fail to effectively extract concepts through words and phrases. Thirdly, the textual contents are temporally skewed, which can affect the semantic understanding by multiple time facets. Finally, using the complementary knowledge-bases makes the results biased to the content of the external database and deviates the understanding and interpretation away from the real nature of the given short text corpus. To overcome these challenges, we devise a neural network-based temporal-textual framework that generates the tightly connected author subgraphs from microblog short-text contents. Our approach, on the one hand, computes the relevance score (edge weight) between the authors through considering a portmanteau of contents and concepts, and on the other hand, employs a stack-wise graph cutting algorithm to extract the communities of the related authors. Experimental results show that compared to other knowledge-centered competitors, our multi-aspect vector space model can achieve a higher performance in linking short-text authors. Additionally, given the author linking task, the more comprehensive the dataset is, the higher the significance of the extracted concepts will be.
TEAGS: Time-aware Text Embedding Approach to Generate Subgraphs
Aug 21, 2019
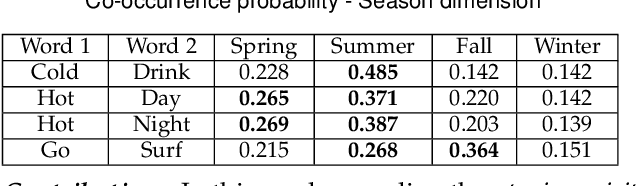
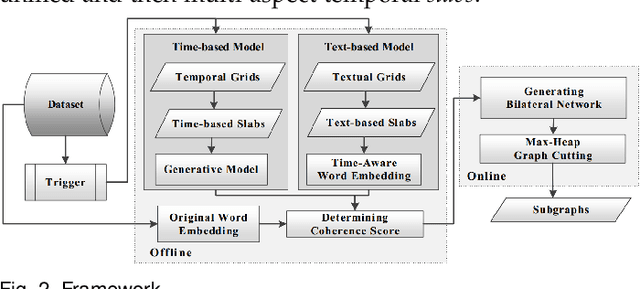

Contagions (e.g. virus, gossip) spread over the nodes in propagation graphs. We can use the temporal and textual data of the nodes to compute the edge weights and then generate subgraphs with highly relevant nodes. This is beneficial to many applications. Yet, challenges abound. First, the propagation pattern between each pair of nodes may change by time. Second, not always the same contagion propagates. Hence, the state-of-the-art text mining approaches including topic-modeling cannot effectively compute the edge weights. Third, since the propagation is affected by time, the word-word co-occurrence patterns may differ in various temporal dimensions, that can decrease the effectiveness of word embedding approaches. We argue that multi-aspect temporal dimensions (hour, day, etc) should be considered to better calculate the correlation weights between the nodes. In this work, we devise a novel framework that on the one hand, integrates a neural network based time-aware word embedding component to construct the word vectors through multiple temporal facets, and on the other hand, uses a temporal generative model to compute the weights. Subsequently, we propose a Max-Heap Graph cutting algorithm to generate subgraphs. We validate our model through comprehensive experiments on real-world datasets. The results show that our model can retrieve the subgraphs more effective than other rivals and the temporal dynamics should be noticed both in word embedding and propagation processes.