 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive-aware Short-text Understanding for Inferring Professions
Paper and Code
Jun 04, 2021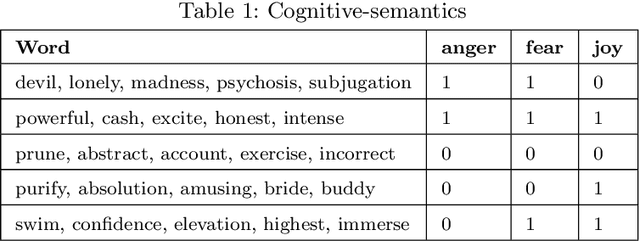
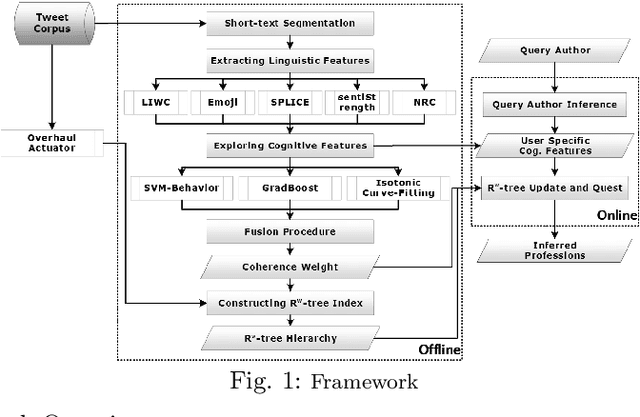
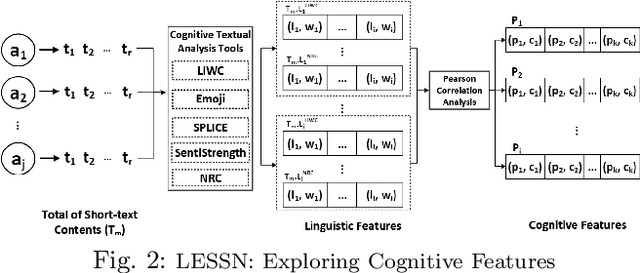
Leveraging short-text contents to estimate the occupation of microblog authors has significant gains in many applications. Yet challenges abound. Firstly brief textual contents come with excessive lexical noise that makes the inference problem challenging. Secondly, cognitive-semantics are not evident, and important linguistic features are latent in short-text contents. Thirdly, it is hard to measure the correlation between the cognitive short-text semantics and the features pertaining various occupations. We argue that the multi-aspect cognitive features are needed to correctly associate short-text contents to a particular job and discover suitable people for the careers. To this end, we devise a novel framework that on the one hand, can infer short-text contents and exploit cognitive features, and on the other hand, fuses various adopted novel algorithms, such as curve fitting, support vector, and boosting modules to better predict the occupation of the authors. The final estimation module manufactures the $R^w$-tree via coherence weight to tune the best outcome in the inferring process. We conduct comprehensive experiments on real-life Twitter data. The experimental results show that compared to other rivals, our cognitive multi-aspect model can achieve a higher performance in the career estimation procedure, where it is inevitable to neglect the contextual semantics of users.