 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulMate: Short-text author linking through Multi-aspect temporal-textual embedding
Oct 27, 2019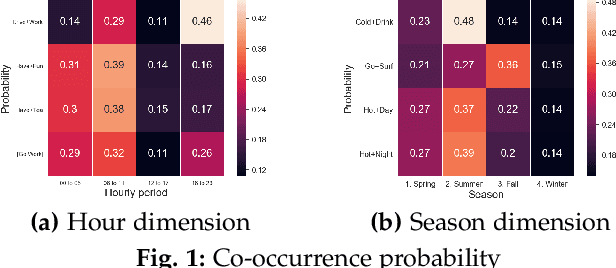

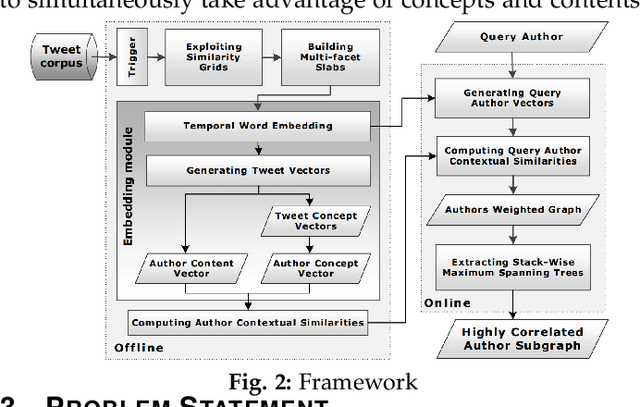
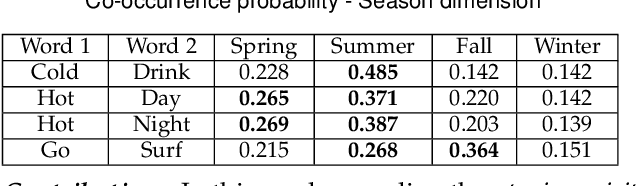
Linking authors of short-text contents has important usages in many applications, including Named Entity Recognition (NER) and human community detection. However, certain challenges lie ahead. Firstly, the input short-text contents are noisy, ambiguous, and do not follow the grammatical rules. Secondly, traditional text mining methods fail to effectively extract concepts through words and phrases. Thirdly, the textual contents are temporally skewed, which can affect the semantic understanding by multiple time facets. Finally, using the complementary knowledge-bases makes the results biased to the content of the external database and deviates the understanding and interpretation away from the real nature of the given short text corpus. To overcome these challenges, we devise a neural network-based temporal-textual framework that generates the tightly connected author subgraphs from microblog short-text contents. Our approach, on the one hand, computes the relevance score (edge weight) between the authors through considering a portmanteau of contents and concepts, and on the other hand, employs a stack-wise graph cutting algorithm to extract the communities of the related authors. Experimental results show that compared to other knowledge-centered competitors, our multi-aspect vector space model can achieve a higher performance in linking short-text authors. Additionally, given the author linking task, the more comprehensive the dataset is, the higher the significance of the extracted concepts will be.
TEAGS: Time-aware Text Embedding Approach to Generate Subgraphs
Aug 21, 2019
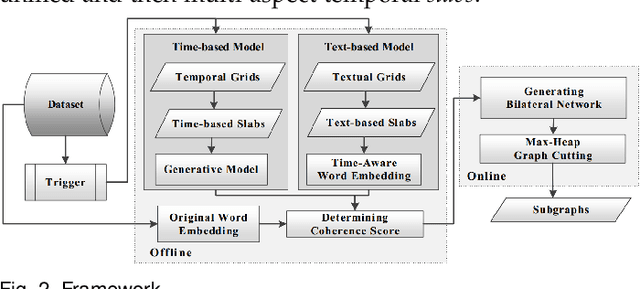

Contagions (e.g. virus, gossip) spread over the nodes in propagation graphs. We can use the temporal and textual data of the nodes to compute the edge weights and then generate subgraphs with highly relevant nodes. This is beneficial to many applications. Yet, challenges abound. First, the propagation pattern between each pair of nodes may change by time. Second, not always the same contagion propagates. Hence, the state-of-the-art text mining approaches including topic-modeling cannot effectively compute the edge weights. Third, since the propagation is affected by time, the word-word co-occurrence patterns may differ in various temporal dimensions, that can decrease the effectiveness of word embedding approaches. We argue that multi-aspect temporal dimensions (hour, day, etc) should be considered to better calculate the correlation weights between the nodes. In this work, we devise a novel framework that on the one hand, integrates a neural network based time-aware word embedding component to construct the word vectors through multiple temporal facets, and on the other hand, uses a temporal generative model to compute the weights. Subsequently, we propose a Max-Heap Graph cutting algorithm to generate subgraphs. We validate our model through comprehensive experiments on real-world datasets. The results show that our model can retrieve the subgraphs more effective than other rivals and the temporal dynamics should be noticed both in word embedding and propagation processes.