 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIZE: Regularized Imitation Learning via Distributional Reinforcement Learning
Feb 27, 2025We introduce a novel Inverse Reinforcement Learning (IRL) approach that overcomes limitations of fixed reward assignments and constrained flexibility in implicit reward regularization. By extending the Maximum Entropy IRL framework with a squared temporal-difference (TD) regularizer and adaptive targets, dynamically adjusted during training, our method indirectly optimizes a reward function while incorporating reinforcement learning principles. Furthermore, we integrate distributional RL to capture richer return information. Our approach achieves state-of-the-art performance on challenging MuJoCo tasks, demonstrating expert-level results on the Humanoid task with only 3 demonstrations. Extensive experiments and ablation studies validate the effectiveness of our method, providing insights into adaptive targets and reward dynamics in imitation learning.
Multi-step-ahead Stock Price Prediction Using Recurrent Fuzzy Neural Network and Variational Mode Decomposition
Dec 24, 2022Financial time series prediction, a growing research topic, has attracted considerable interest from scholars, and several approaches have been developed. Among them, decomposition-based methods have achieved promising results. Most decomposition-based methods approximate a single function, which is insufficient for obtaining accurate results. Moreover, most existing researches have concentrated on one-step-ahead forecasting that prevents stock market investors from arriving at the best decisions for the future. This study proposes two novel methods for multi-step-ahead stock price prediction based on the issues outlined. DCT-MFRFNN, a method based on discrete cosine transform (DCT) and multi-functional recurrent fuzzy neural network (MFRFNN), uses DCT to reduce fluctuations in the time series and simplify its structure and MFRFNN to predict the stock price. VMD-MFRFNN, an approach based on variational mode decomposition (VMD) and MFRFNN, brings together their advantages. VMD-MFRFNN consists of two phases. The input signal is decomposed to several IMFs using VMD in the decomposition phase. In the prediction and reconstruction phase, each of the IMFs is given to a separate MFRFNN for prediction, and predicted signals are summed to reconstruct the output. Three financial time series, including Hang Seng Index (HSI), Shanghai Stock Exchange (SSE), and Standard & Poor's 500 Index (SPX), are used for the evaluation of the proposed methods. Experimental results indicate that VMD-MFRFNN surpasses other state-of-the-art methods. VMD-MFRFNN, on average, shows 35.93%, 24.88%, and 34.59% decreases in RMSE from the second-best model for HSI, SSE, and SPX, respectively. Also, DCT-MFRFNN outperforms MFRFNN in all experiments.
EnTRPO: Trust Region Policy Optimization Method with Entropy Regularization
Oct 26, 2021
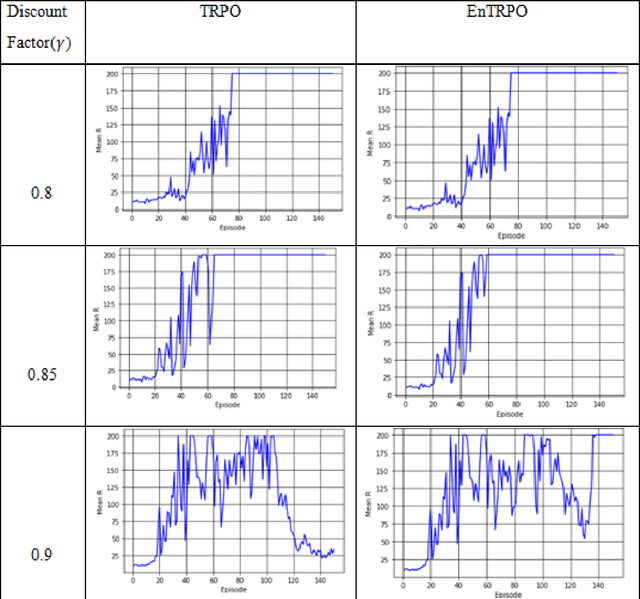
Trust Region Policy Optimization (TRPO) is a popular and empirically successful policy search algorithm in reinforcement learning (RL). It iteratively solved the surrogate problem which restricts consecutive policies to be close to each other. TRPO is an on-policy algorithm. On-policy methods bring many benefits, like the ability to gauge each resulting policy. However, they typically discard all the knowledge about the policies which existed before. In this work, we use a replay buffer to borrow from the off-policy learning setting to TRPO. Entropy regularization is usually used to improve policy optimization in reinforcement learning. It is thought to aid exploration and generalization by encouraging more random policy choices. We add an Entropy regularization term to advantage over {\pi}, accumulated over time steps, in TRPO. We call this update EnTRPO. Our experiments demonstrate EnTRPO achieves better performance for controlling a Cart-Pole system compared with the original TRPO
Modified Double DQN: addressing stability
Aug 09, 2021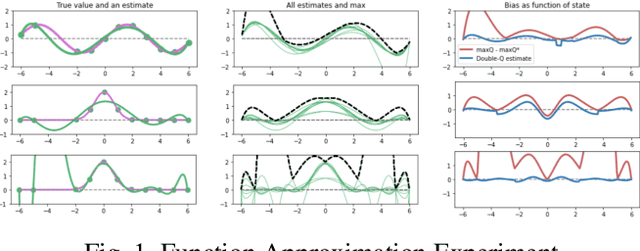
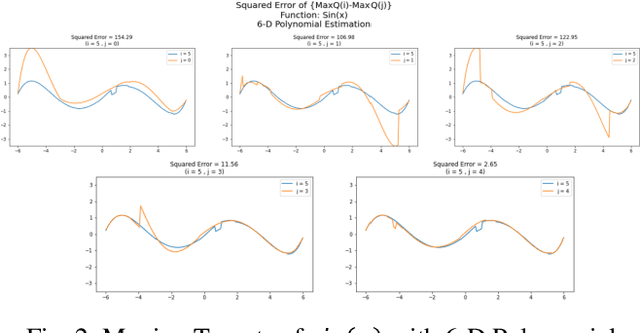
Inspired by double q learning algorithm, the double DQN algorithm was originally proposed in order to address the overestimation issue in the original DQN algorithm. The double DQN has successfully shown both theoretically and empirically the importance of decoupling in terms of action evaluation and selection in computation of targets values; although, all the benefits were acquired with only a simple adaption to DQN algorithm, minimal possible change as it was mentioned by the authors. Nevertheless, there seems a roll-back in the proposed algorithm of Double-DQN since the parameters of policy network are emerged again in the target value function which were initially withdrawn by DQN with the hope of tackling the serious issue of moving targets and the instability caused by it (i.e., by moving targets) in the process of learning. Therefore, in this paper three modifications to the Double-DQN algorithm are proposed with the hope of maintaining the performance in the terms of both stability and overestimation. These modifications are focused on the logic of decoupling the best action selection and evaluation in the target value function and the logic of tackling the moving targets issue. Each of these modifications have their own pros and cons compared to the others. The mentioned pros and cons mainly refer to the execution time required for the corresponding algorithm and the stability provided by the corresponding algorithm. Also, in terms of overestimation, none of the modifications seem to underperform compared to the original Double-DQN if not outperform it. With the intention of evaluating the efficacy of the proposed modifications, multiple empirical experiments along with theoretical experiments were conducted. The results obtained are represented and discussed in this article.
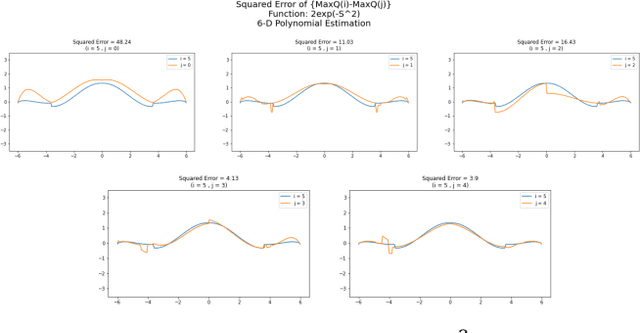
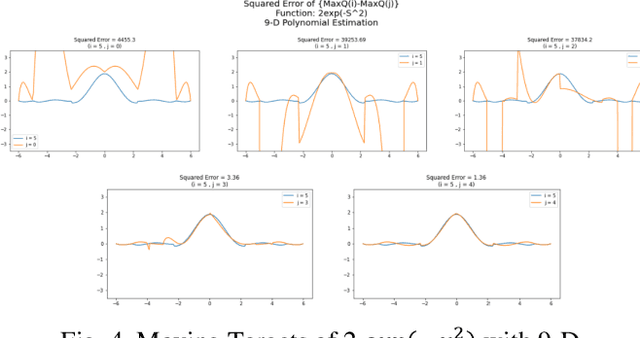
Maximum Entropy Dueling Network Architecture
Jul 30, 2021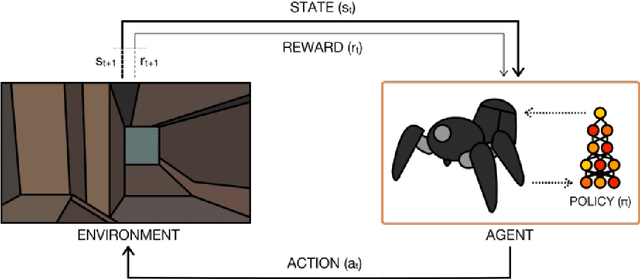



In recent years, there have been many deep structures for Reinforcement Learning, mainly for value function estimation and representations. These methods achieved great success in Atari 2600 domain. In this paper, we propose an improved architecture based upon Dueling Networks, in this architecture, there are two separate estimators, one approximate the state value function and the other, state advantage function. This improvement based on Maximum Entropy, shows better policy evaluation compared to the original network and other value-based architectures in Atari domain.
Adaptive Explicit Kernel Minkowski Weighted K-means
Dec 04, 2020
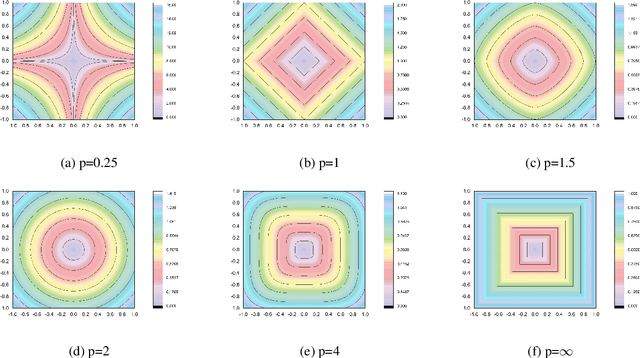
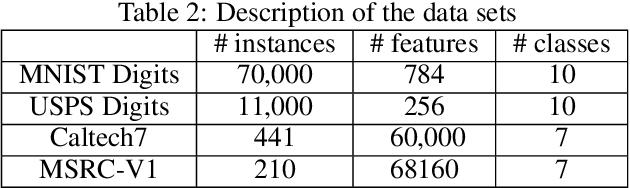
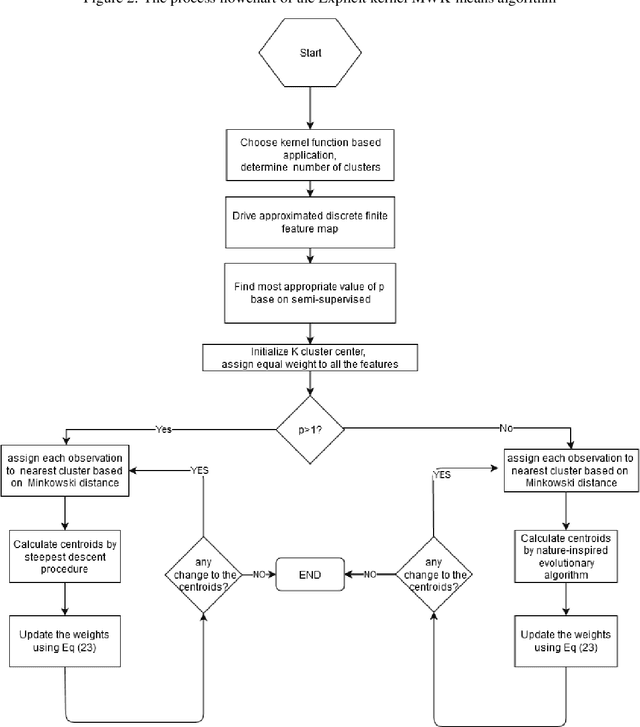
The K-means algorithm is among the most commonly used data clustering methods. However, the regular K-means can only be applied in the input space and it is applicable when clusters are linearly separable. The kernel K-means, which extends K-means into the kernel space, is able to capture nonlinear structures and identify arbitrarily shaped clusters. However, kernel methods often operate on the kernel matrix of the data, which scale poorly with the size of the matrix or suffer from the high clustering cost due to the repetitive calculations of kernel values. Another issue is that algorithms access the data only through evaluations of $K(x_i, x_j)$, which limits many processes that can be done on data through the clustering task. This paper proposes a method to combine the advantages of the linear and nonlinear approaches by using driven corresponding approximate finite-dimensional feature maps based on spectral analysis. Applying approximate finite-dimensional feature maps were only discussed in the Support Vector Machines (SVM) problems before. We suggest using this method in kernel K-means era as alleviates storing huge kernel matrix in memory, further calculating cluster centers more efficiently and access the data explicitly in feature space. These explicit feature maps enable us to access the data in the feature space explicitly and take advantage of K-means extensions in that space. We demonstrate our Explicit Kernel Minkowski Weighted K-mean (Explicit KMWK-mean) method is able to be more adopted and find best-fitting values in new space by applying additional Minkowski exponent and feature weights parameter. Moreover, it can reduce the impact of concentration on nearest neighbour search by suggesting investigate among other norms instead of Euclidean norm, includes Minkowski norms and fractional norms (as an extension of the Minkowski norms with p<1).
Backpropagation-Free Learning Method for Correlated Fuzzy Neural Networks
Nov 25, 2020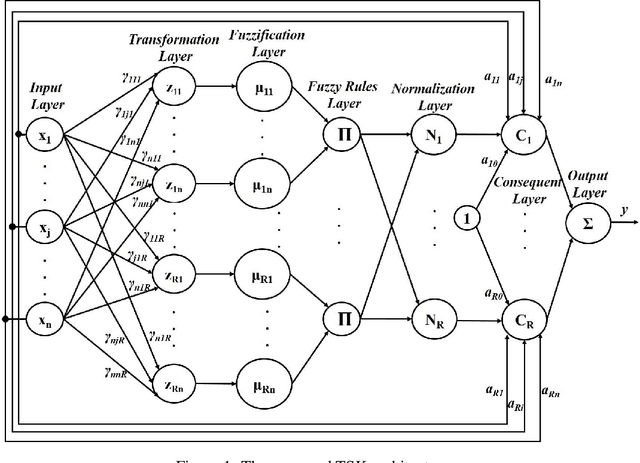

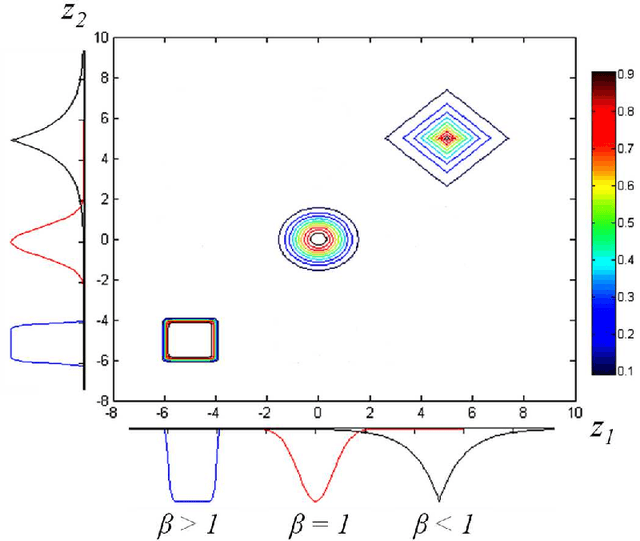
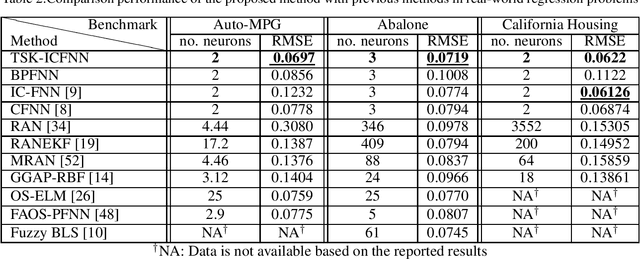
In this paper, a novel stepwise learning approach based on estimating desired premise parts' outputs by solving a constrained optimization problem is proposed. This learning approach does not require backpropagating the output error to learn the premise parts' parameters. Instead, the near best output values of the rules premise parts are estimated and their parameters are changed to reduce the error between current premise parts' outputs and the estimated desired ones. Therefore, the proposed learning method avoids error backpropagation, which lead to vanishing gradient and consequently getting stuck in a local optimum. The proposed method does not need any initialization method. This learning method is utilized to train a new Takagi-Sugeno-Kang (TSK) Fuzzy Neural Network with correlated fuzzy rules including many parameters in both premise and consequent parts, avoiding getting stuck in a local optimum due to vanishing gradient. To learn the proposed network parameters, first, a constrained optimization problem is introduced and solved to estimate the desired values of premise parts' output values. Next, the error between these values and the current ones is utilized to adapt the premise parts' parameters based on the gradient-descent (GD) approach. Afterward, the error between the desired and network's outputs is used to learn consequent parts' parameters by the GD method. The proposed paradigm is successfully applied to real-world time-series prediction and regression problems. According to experimental results, its performance outperforms other methods with a more parsimonious structure.
A self-organizing fuzzy neural network for sequence learning
Aug 01, 2019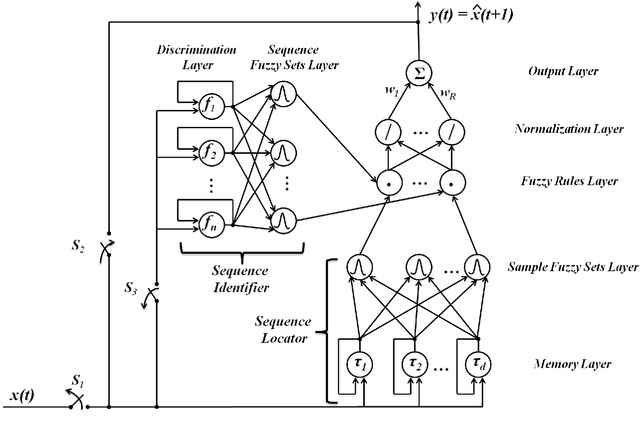
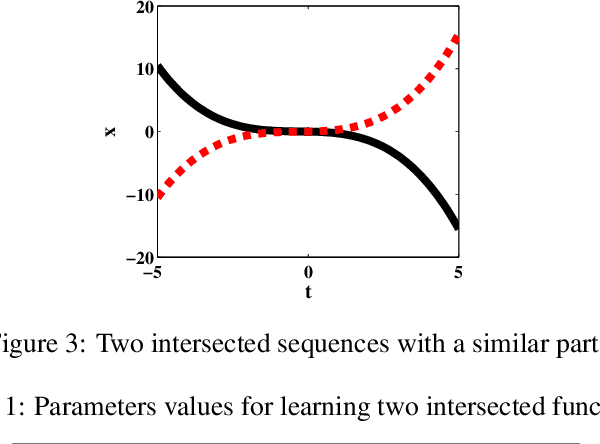
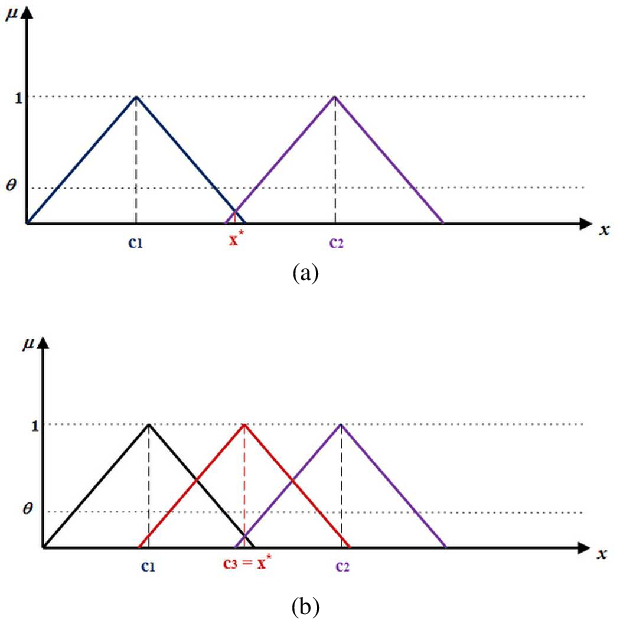
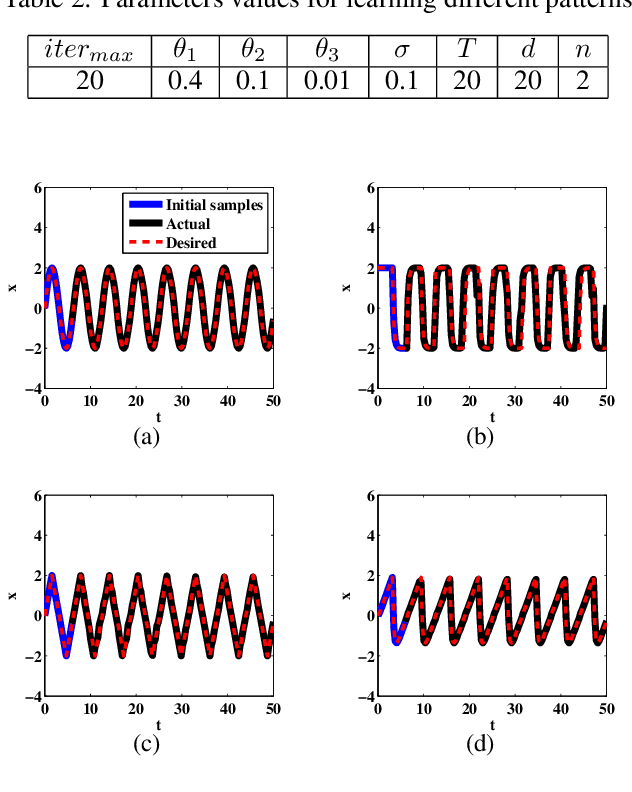
In this paper, a new self-organizing fuzzy neural network model is presented which is able to learn and reproduce different sequences accurately. Sequence learning is important in performing skillful tasks, such as writing and playing piano. The structure of the proposed network is composed of two parts: 1-sequence identifier which computes a novel sequence identity value based on initial samples of a sequence, and detects the sequence identity based on proper fuzzy rules, and 2-sequence locator, which locates the input sample in the sequence. Therefore, by integrating outputs of these two parts in fuzzy rules, the network is able to produce the proper output based on current state of the sequence. To learn the proposed structure, a gradual learning procedure is proposed. First, learning is performed by adding new fuzzy rules, based on coverage measure, using available correct data. Next, the initialized parameters are fine-tuned, by gradient descent algorithm, based on fed back approximated network output as the next input. The proposed method has a dynamic structure which is able to learn new sequences online. The proposed method is used to learn and reproduce different sequences simultaneously which is the novelty of this method.