 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA CNN-Transformer for Classification of Longitudinal 3D MRI Images -- A Case Study on Hepatocellular Carcinoma Prediction
Jan 18, 2025



Longitudinal MRI analysis is crucial for predicting disease outcomes, particularly in chronic conditions like hepatocellular carcinoma (HCC), where early detection can significantly influence treatment strategies and patient prognosis. Yet, due to challenges like limited data availability, subtle parenchymal changes, and the irregular timing of medical screenings, current approaches have so far focused on cross-sectional imaging data. To address this, we propose HCCNet, a novel model architecture that integrates a 3D adaptation of the ConvNeXt CNN architecture with a Transformer encoder, capturing both the intricate spatial features of 3D MRIs and the complex temporal dependencies across different time points. HCCNet utilizes a two-stage pre-training process tailored for longitudinal MRI data. The CNN backbone is pre-trained using a self-supervised learning framework adapted for 3D MRIs, while the Transformer encoder is pre-trained with a sequence-order-prediction task to enhance its understanding of disease progression over time. We demonstrate the effectiveness of HCCNet by applying it to a cohort of liver cirrhosis patients undergoing regular MRI screenings for HCC surveillance. Our results show that HCCNet significantly improves predictive accuracy and reliability over baseline models, providing a robust tool for personalized HCC surveillance. The methodological approach presented in this paper is versatile and can be adapted to various longitudinal MRI screening applications. Its ability to handle varying patient record lengths and irregular screening intervals establishes it as an invaluable framework for monitoring chronic diseases, where timely and accurate disease prognosis is critical for effective treatment planning.
Adaptive Explicit Kernel Minkowski Weighted K-means
Dec 04, 2020
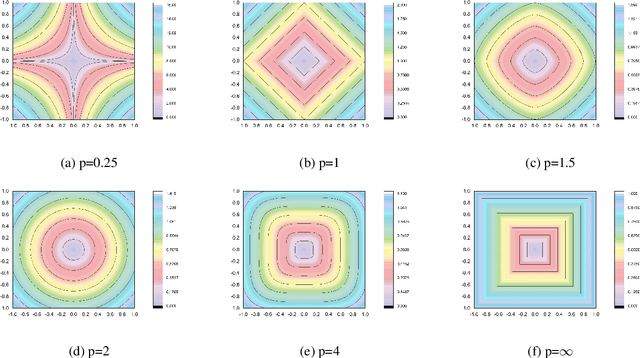
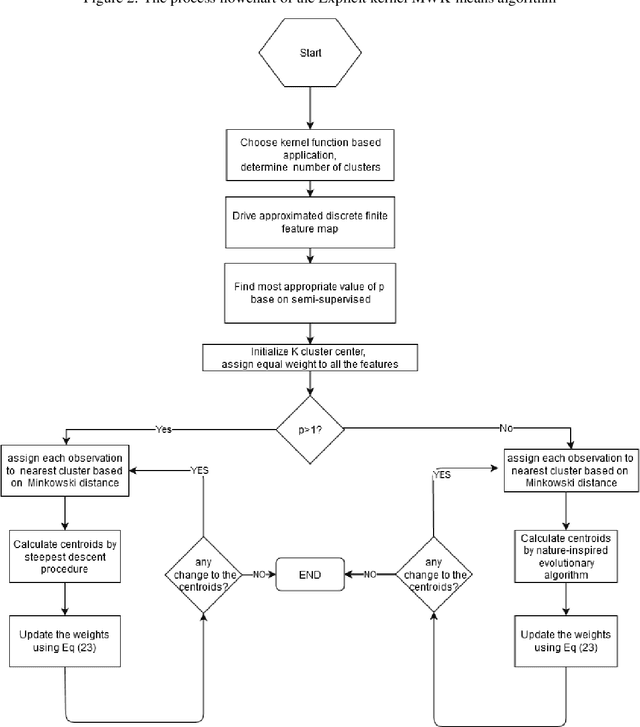
The K-means algorithm is among the most commonly used data clustering methods. However, the regular K-means can only be applied in the input space and it is applicable when clusters are linearly separable. The kernel K-means, which extends K-means into the kernel space, is able to capture nonlinear structures and identify arbitrarily shaped clusters. However, kernel methods often operate on the kernel matrix of the data, which scale poorly with the size of the matrix or suffer from the high clustering cost due to the repetitive calculations of kernel values. Another issue is that algorithms access the data only through evaluations of $K(x_i, x_j)$, which limits many processes that can be done on data through the clustering task. This paper proposes a method to combine the advantages of the linear and nonlinear approaches by using driven corresponding approximate finite-dimensional feature maps based on spectral analysis. Applying approximate finite-dimensional feature maps were only discussed in the Support Vector Machines (SVM) problems before. We suggest using this method in kernel K-means era as alleviates storing huge kernel matrix in memory, further calculating cluster centers more efficiently and access the data explicitly in feature space. These explicit feature maps enable us to access the data in the feature space explicitly and take advantage of K-means extensions in that space. We demonstrate our Explicit Kernel Minkowski Weighted K-mean (Explicit KMWK-mean) method is able to be more adopted and find best-fitting values in new space by applying additional Minkowski exponent and feature weights parameter. Moreover, it can reduce the impact of concentration on nearest neighbour search by suggesting investigate among other norms instead of Euclidean norm, includes Minkowski norms and fractional norms (as an extension of the Minkowski norms with p<1).
Multi-Label Classification Using Link Prediction
Nov 11, 2020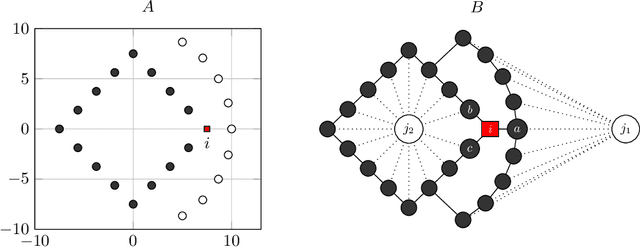
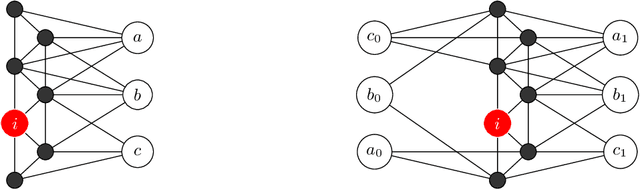

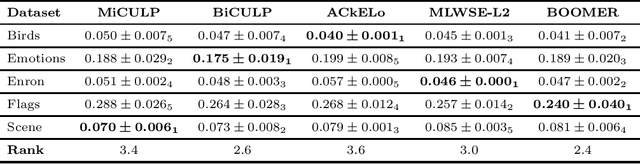
Solving classification with graph methods has gained huge popularity in recent years. This is due to the fact that the data can be intuitively modeled with graphs to utilize high level features to aid in solving the classification problem. CULP which is short for Classification Using Link Prediction is a graph-based classifier. This classifier utilizes the graph representation of the data and transforms the problem to that of link prediction where we try to find the link between an unlabeled node and the proper class node for it. CULP proved to be highly accurate classifier and it has the power to predict the labels in near constant time. A variant of the classification problem is multi-label classification which tackles this problem for multi-label data where an instance can have multiple labels associated to it. In this work, we extend the CULP algorithm to address this problem. Our proposed extensions conveys the powers of CULP and its intuitive representation of the data in to the multi-label domain and in comparison to some of the cutting edge multi-label classifiers, yield competitive results.
SDCOR: Scalable Density-based Clustering for Local Outlier Detection in Massive-Scale Datasets
Jun 27, 2020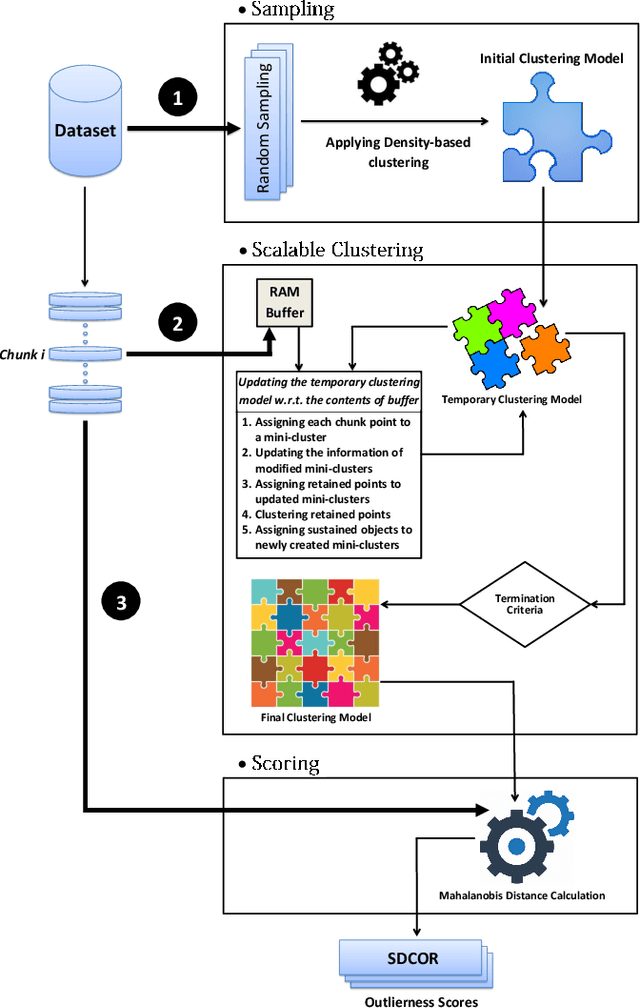

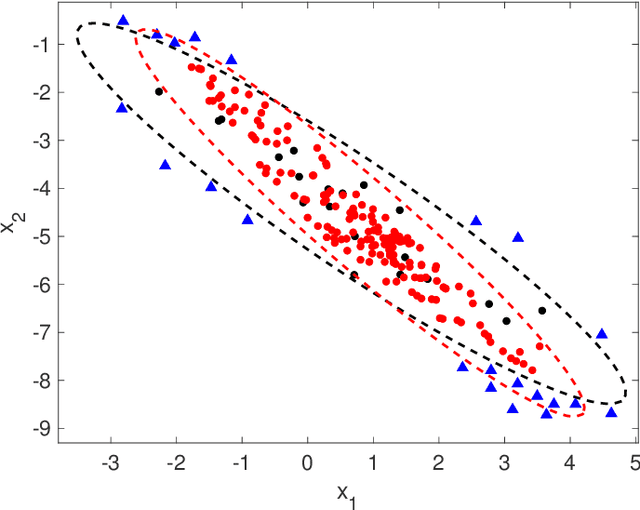
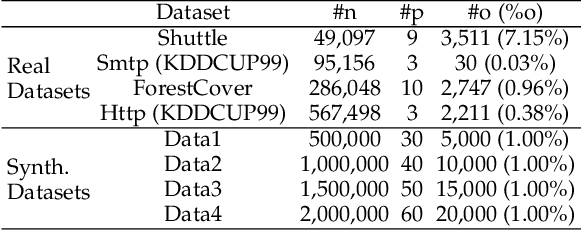
This paper presents a batch-wise density-based clustering approach for local outlier detection in massive-scale datasets. Differently from well-known traditional algorithms, which assume that all the data is memory-resident, our proposed method is scalable and processes the data chunk-by-chunk within the confines of a limited memory buffer. At first, a temporary clustering model is built, then it is incrementally updated by analyzing consecutive memory loads of points. Ultimately, the proposed algorithm will give an outlying score to each object, which is named SDCOR (Scalable Density-based Clustering Outlierness Ratio). Evaluations on real-life and synthetic datasets demonstrate that the proposed method has a low linear time complexity and is more effective and efficient compared to best-known conventional density-based methods, which need to load all the data into memory; and also to some fast distance-based methods which can perform on the data resident in the disk.
Hybrid Forest: A Concept Drift Aware Data Stream Mining Algorithm
Feb 10, 2019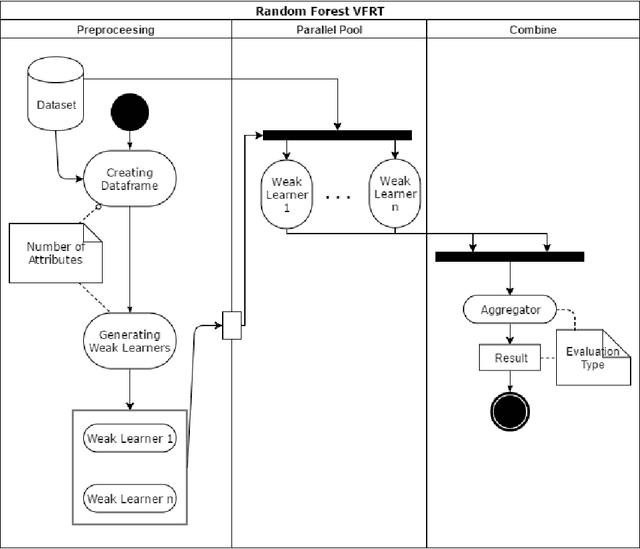
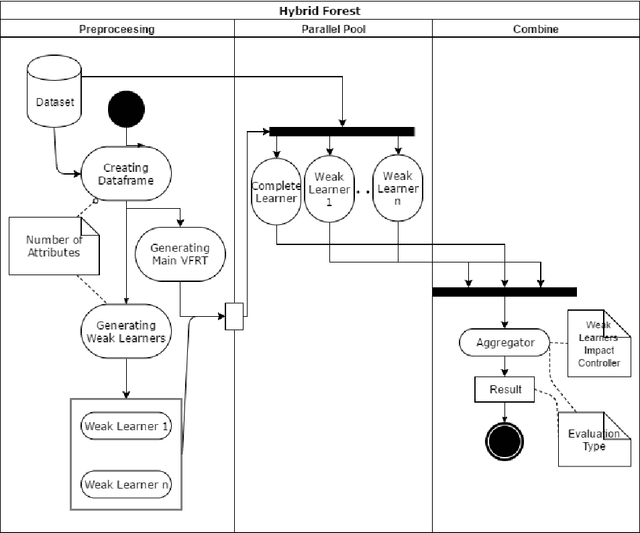

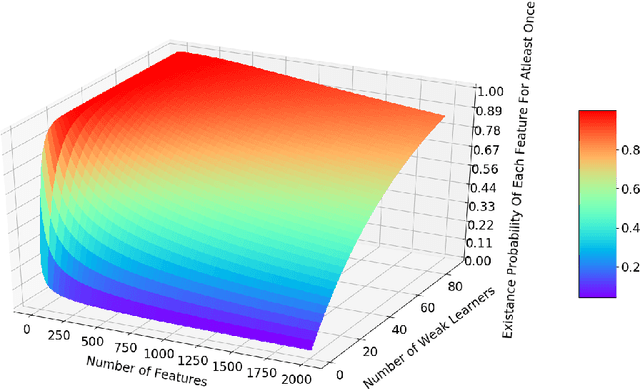
Nowadays with a growing number of online controlling systems in the organization and also a high demand of monitoring and stats facilities that uses data streams to log and control their subsystems, data stream mining becomes more and more vital. Hoeffding Trees (also called Very Fast Decision Trees a.k.a. VFDT) as a Big Data approach in dealing with the data stream for classification and regression problems showed good performance in handling facing challenges and making the possibility of any-time prediction. Although these methods outperform other methods e.g. Artificial Neural Networks (ANN) and Support Vector Regression (SVR), they suffer from high latency in adapting with new concepts when the statistical distribution of incoming data changes. In this article, we introduced a new algorithm that can detect and handle concept drift phenomenon properly. This algorithms also benefits from fast startup ability which helps systems to be able to predict faster than other algorithms at the beginning of data stream arrival. We also have shown that our approach will overperform other controversial approaches for classification and regression tasks.
A Fuzzy Community-Based Recommender System Using PageRank
Dec 18, 2018
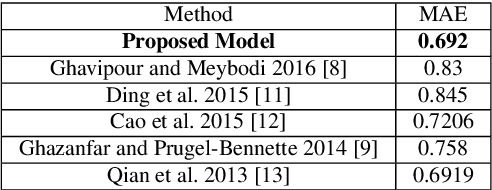
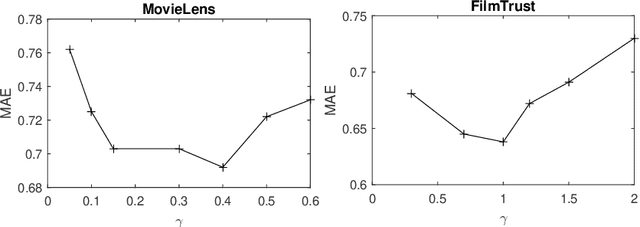

Recommendation systems are widely used by different user service providers specially those who have interactions with the large community of users. This paper introduces a recommender system based on community detection. The recommendation is provided using the local and global similarities between users. The local information is obtained from communities, and the global ones are based on the ratings. Here, a new fuzzy community detection using the personalized PageRank metaphor is introduced. The fuzzy membership values of the users to the communities are utilized to define a similarity measure. The method is evaluated by using two well-known datasets: MovieLens and FilmTrust. The results show that our method outperforms recent recommender systems.
Classification Using Link Prediction
Oct 01, 2018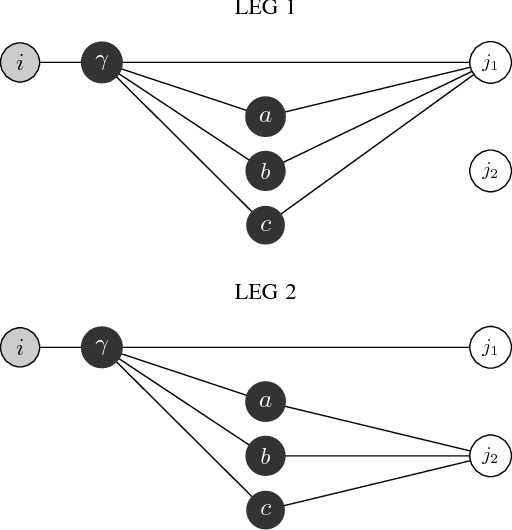

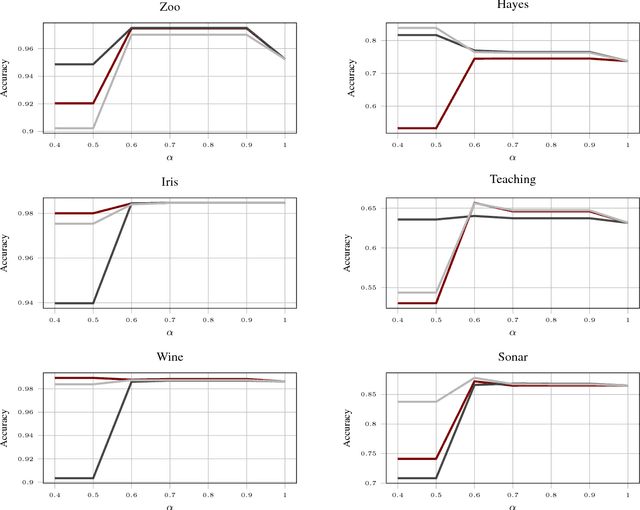
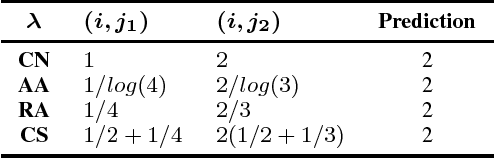
Link prediction in a graph is the problem of detecting the missing links that would be formed in the near future. Using a graph representation of the data, we can convert the problem of classification to the problem of link prediction which aims at finding the missing links between the unlabeled data (unlabeled nodes) and their classes. To our knowledge, despite the fact that numerous algorithms use the graph representation of the data for classification, none are using link prediction as the heart of their classifying procedure. In this work, we propose a novel algorithm called CULP (Classification Using Link Prediction) which uses a new structure namely Label Embedded Graph or LEG and a link predictor to find the class of the unlabeled data. Different link predictors along with Compatibility Score - a new link predictor we proposed that is designed specifically for our settings - has been used and showed promising results for classifying different datasets. This paper further improved CULP by designing an extension called CULM which uses a majority vote (hence the M in the acronym) procedure with weights proportional to the predictions' confidences to use the predictive power of multiple link predictors and also exploits the low level features of the data. Extensive experimental evaluations shows that both CULP and CULM are highly accurate and competitive with the cutting edge graph classifiers and general classifiers.