 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Classification Using Link Prediction
Nov 11, 2020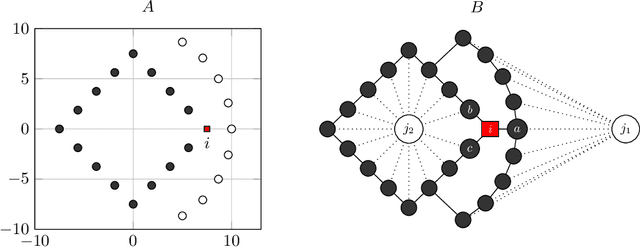

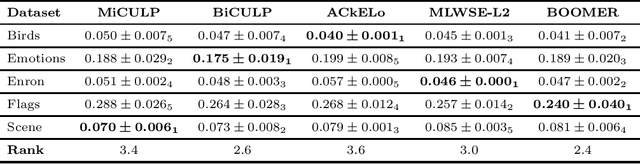
Solving classification with graph methods has gained huge popularity in recent years. This is due to the fact that the data can be intuitively modeled with graphs to utilize high level features to aid in solving the classification problem. CULP which is short for Classification Using Link Prediction is a graph-based classifier. This classifier utilizes the graph representation of the data and transforms the problem to that of link prediction where we try to find the link between an unlabeled node and the proper class node for it. CULP proved to be highly accurate classifier and it has the power to predict the labels in near constant time. A variant of the classification problem is multi-label classification which tackles this problem for multi-label data where an instance can have multiple labels associated to it. In this work, we extend the CULP algorithm to address this problem. Our proposed extensions conveys the powers of CULP and its intuitive representation of the data in to the multi-label domain and in comparison to some of the cutting edge multi-label classifiers, yield competitive results.
Classification Using Link Prediction
Oct 01, 2018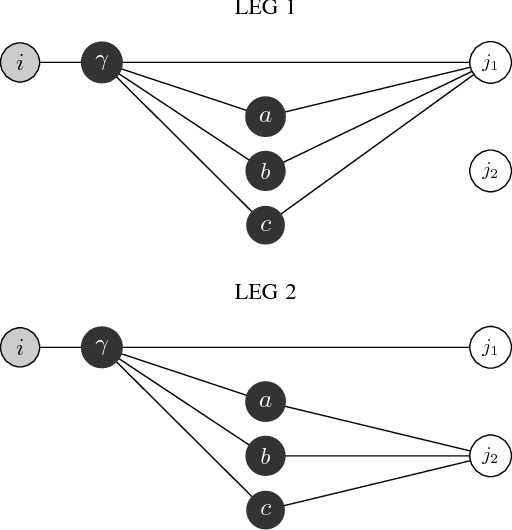

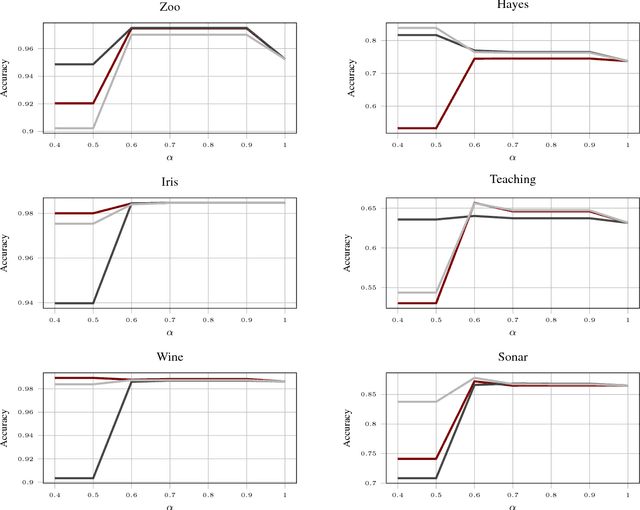
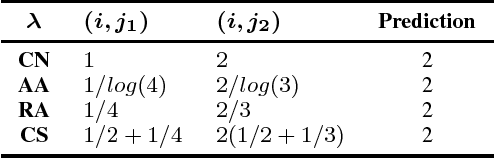
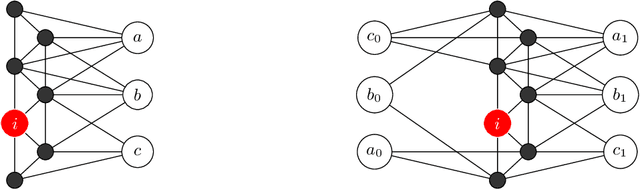
Link prediction in a graph is the problem of detecting the missing links that would be formed in the near future. Using a graph representation of the data, we can convert the problem of classification to the problem of link prediction which aims at finding the missing links between the unlabeled data (unlabeled nodes) and their classes. To our knowledge, despite the fact that numerous algorithms use the graph representation of the data for classification, none are using link prediction as the heart of their classifying procedure. In this work, we propose a novel algorithm called CULP (Classification Using Link Prediction) which uses a new structure namely Label Embedded Graph or LEG and a link predictor to find the class of the unlabeled data. Different link predictors along with Compatibility Score - a new link predictor we proposed that is designed specifically for our settings - has been used and showed promising results for classifying different datasets. This paper further improved CULP by designing an extension called CULM which uses a majority vote (hence the M in the acronym) procedure with weights proportional to the predictions' confidences to use the predictive power of multiple link predictors and also exploits the low level features of the data. Extensive experimental evaluations shows that both CULP and CULM are highly accurate and competitive with the cutting edge graph classifiers and general classifiers.