Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy Dueling Network Architecture
Paper and Code
Jul 30, 2021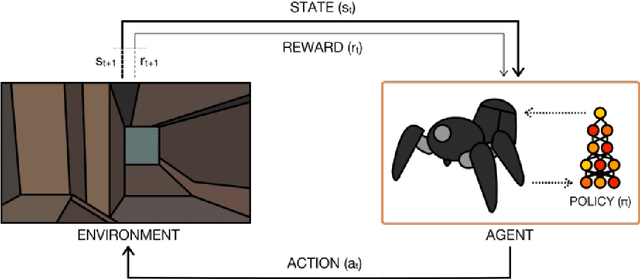



In recent years, there have been many deep structures for Reinforcement Learning, mainly for value function estimation and representations. These methods achieved great success in Atari 2600 domain. In this paper, we propose an improved architecture based upon Dueling Networks, in this architecture, there are two separate estimators, one approximate the state value function and the other, state advantage function. This improvement based on Maximum Entropy, shows better policy evaluation compared to the original network and other value-based architectures in Atari domain.
View paper on