 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistoFusionNet: Histogram-Guided Fusion and Frequency-Adaptive Refinement for Nighttime Image Dehazing
Apr 04, 2026Nighttime image dehazing remains a challenging low-level vision problem due to the joint presence of haze, glow, non-uniform illumination, color distortion, and sensor noise, which often invalidate assumptions commonly used in daytime dehazing. To address these challenges, we propose HistoFusionNet, a transformer-enhanced architecture tailored for nighttime image dehazing by combining histogram-guided representation learning with frequency-adaptive feature refinement. Built upon a multi-scale encoder-decoder backbone, our method introduces histogram transformer blocks that model long-range dependencies by grouping features according to their dynamic-range characteristics, enabling more effective aggregation of similarly degraded regions under complex nighttime lighting. To further improve restoration fidelity, we incorporate a frequency-aware refinement branch that adaptively exploits complementary low- and high-frequency cues, helping recover scene structures, suppress artifacts, and enhance local details. This design yields a unified framework that is particularly well suited to the heterogeneous degradations encountered in real nighttime hazy scenes. Extensive experiments and highly competitive performance of our method on the NTIRE 2026 Nighttime Image Dehazing Challenge benchmark demonstrate the effectiveness of the proposed method. Our team ranked 1st among 22 participating teams, highlighting the robustness and competitive performance of HistoFusionNet. The code is available at: https://github.com/heydarimo/Night-Time-Dehazing
Deep Learning-based Sentiment Analysis in Persian Language
Mar 17, 2024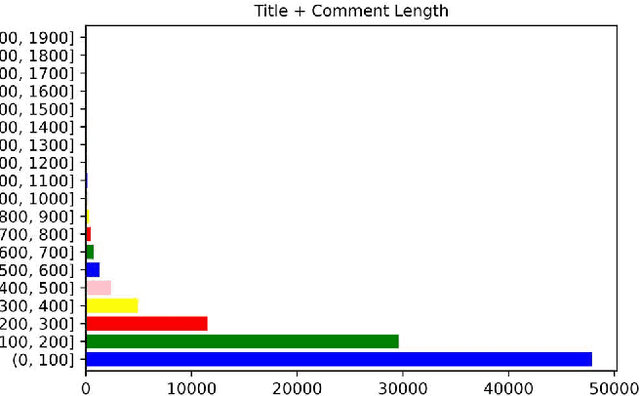


Recently, there has been a growing interest in the use of deep learning techniques for tasks in natural language processing (NLP), with sentiment analysis being one of the most challenging areas, particularly in the Persian language. The vast amounts of content generated by Persian users on thousands of websites, blogs, and social networks such as Telegram, Instagram, and Twitter present a rich resource of information. Deep learning techniques have become increasingly favored for extracting insights from this extensive pool of raw data, although they face several challenges. In this study, we introduced and implemented a hybrid deep learning-based model for sentiment analysis, using customer review data from the Digikala Online Retailer website. We employed a variety of deep learning networks and regularization techniques as classifiers. Ultimately, our hybrid approach yielded an impressive performance, achieving an F1 score of 78.3 across three sentiment categories: positive, negative, and neutral.
Persian Slang Text Conversion to Formal and Deep Learning of Persian Short Texts on Social Media for Sentiment Classification
Mar 09, 2024
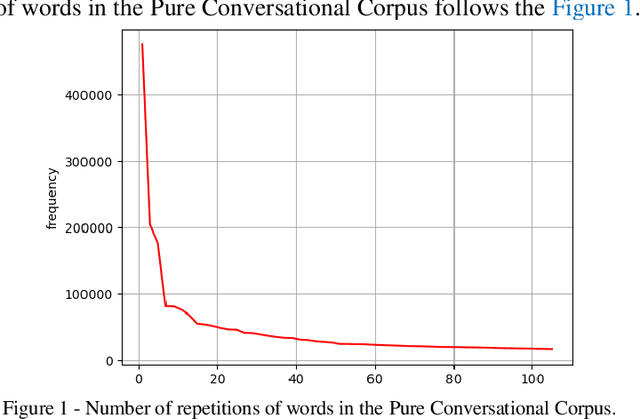

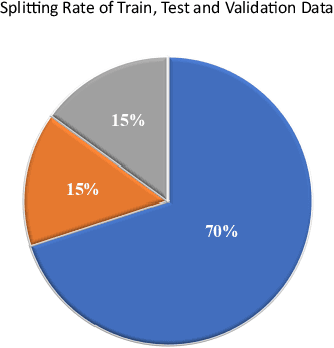
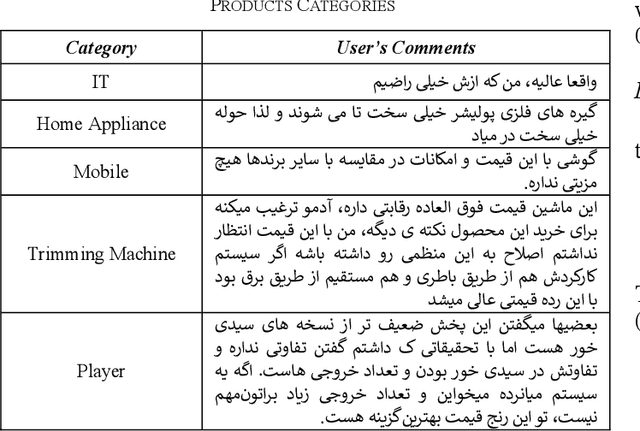
The lack of a suitable tool for the analysis of conversational texts in the Persian language has made various analyses of these texts, including Sentiment Analysis, difficult. In this research, we tried to make the understanding of these texts easier for the machine by providing PSC, Persian Slang Converter, a tool for converting conversational texts into formal ones, and by using the most up-to-date and best deep learning methods along with the PSC, the sentiment learning of short Persian language texts for the machine in a better way. be made More than 10 million unlabeled texts from various social networks and movie subtitles (as Conversational texts) and about 10 million news texts (as formal texts) have been used for training unsupervised models and formal implementation of the tool. 60,000 texts from the comments of Instagram social network users with positive, negative, and neutral labels are considered supervised data for training the emotion classification model of short texts. Using the formal tool, 57% of the words of the corpus of conversation were converted. Finally, by using the formalizer, FastText model, and deep LSTM network, an accuracy of 81.91 was obtained on the test data.
Analysis of Persian News Agencies on Instagram, A Words Co-occurrence Graph-based Approach
Feb 19, 2024

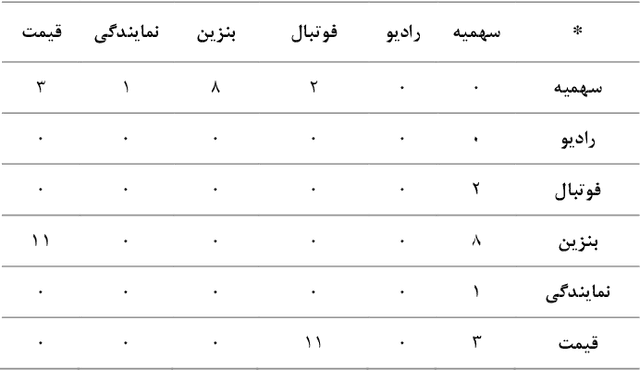
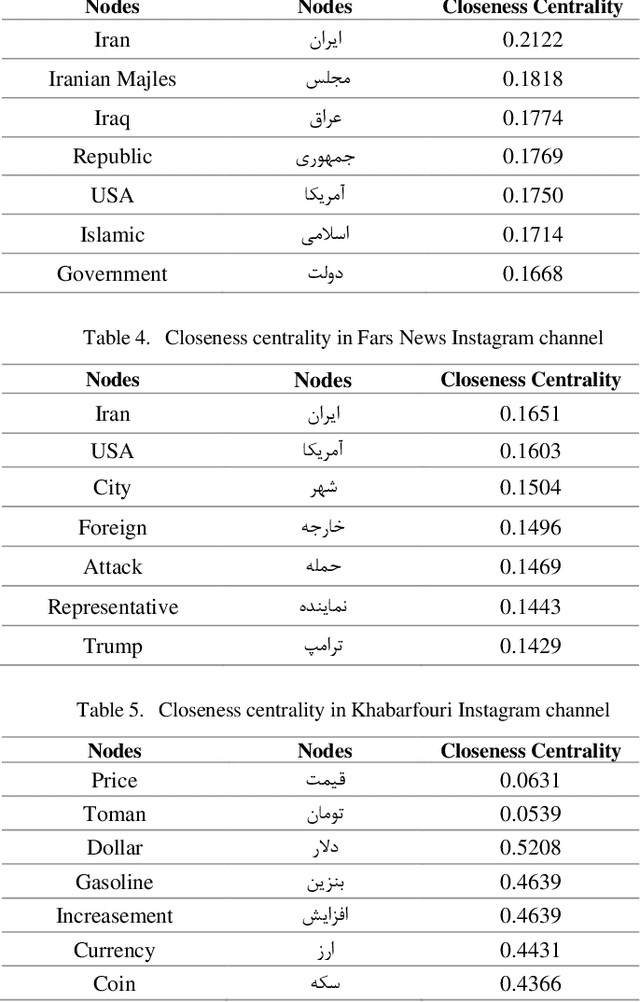
The rise of the Internet and the exponential increase in data have made manual data summarization and analysis a challenging task. Instagram social network is a prominent social network widely utilized in Iran for information sharing and communication across various age groups. The inherent structure of Instagram, characterized by its text-rich content and graph-like data representation, enables the utilization of text and graph processing techniques for data analysis purposes. The degree distributions of these networks exhibit scale-free characteristics, indicating non-random growth patterns. Recently, word co-occurrence has gained attention from researchers across multiple disciplines due to its simplicity and practicality. Keyword extraction is a crucial task in natural language processing. In this study, we demonstrated that high-precision extraction of keywords from Instagram posts in the Persian language can be achieved using unsupervised word co-occurrence methods without resorting to conventional techniques such as clustering or pre-trained models. After graph visualization and community detection, it was observed that the top topics covered by news agencies are represented by these graphs. This approach is generalizable to new and diverse datasets and can provide acceptable outputs for new data. To the author's knowledge, this method has not been employed in the Persian language before on Instagram social network. The new crawled data has been publicly released on GitHub for exploration by other researchers. By employing this method, it is possible to use other graph-based algorithms, such as community detections. The results help us to identify the key role of different news agencies in information diffusion among the public, identify hidden communities, and discover latent patterns among a massive amount of data.
Convolutional Neural Networks Towards Facial Skin Lesions Detection
Feb 13, 2024



Facial analysis has emerged as a prominent area of research with diverse applications, including cosmetic surgery programs, the beauty industry, photography, and entertainment. Manipulating patient images often necessitates professional image processing software. This study contributes by providing a model that facilitates the detection of blemishes and skin lesions on facial images through a convolutional neural network and machine learning approach. The proposed method offers advantages such as simple architecture, speed and suitability for image processing while avoiding the complexities associated with traditional methods. The model comprises four main steps: area selection, scanning the chosen region, lesion diagnosis, and marking the identified lesion. Raw data for this research were collected from a reputable clinic in Tehran specializing in skincare and beauty services. The dataset includes administrative information, clinical data, and facial and profile images. A total of 2300 patient images were extracted from this raw data. A software tool was developed to crop and label lesions, with input from two treatment experts. In the lesion preparation phase, the selected area was standardized to 50 * 50 pixels. Subsequently, a convolutional neural network model was employed for lesion labeling. The classification model demonstrated high accuracy, with a measure of 0.98 for healthy skin and 0.97 for lesioned skin specificity. Internal validation involved performance indicators and cross-validation, while external validation compared the model's performance indicators with those of the transfer learning method using the Vgg16 deep network model. Compared to existing studies, the results of this research showcase the efficacy and desirability of the proposed model and methodology.
Graph Representation Learning Towards Patents Network Analysis
Sep 25, 2023Patent analysis has recently been recognized as a powerful technique for large companies worldwide to lend them insight into the age of competition among various industries. This technique is considered a shortcut for developing countries since it can significantly accelerate their technology development. Therefore, as an inevitable process, patent analysis can be utilized to monitor rival companies and diverse industries. This research employed a graph representation learning approach to create, analyze, and find similarities in the patent data registered in the Iranian Official Gazette. The patent records were scrapped and wrangled through the Iranian Official Gazette portal. Afterward, the key entities were extracted from the scrapped patents dataset to create the Iranian patents graph from scratch based on novel natural language processing and entity resolution techniques. Finally, thanks to the utilization of novel graph algorithms and text mining methods, we identified new areas of industry and research from Iranian patent data, which can be used extensively to prevent duplicate patents, familiarity with similar and connected inventions, Awareness of legal entities supporting patents and knowledge of researchers and linked stakeholders in a particular research field.
Sentiment Analysis Challenges in Persian Language
Jul 09, 2019
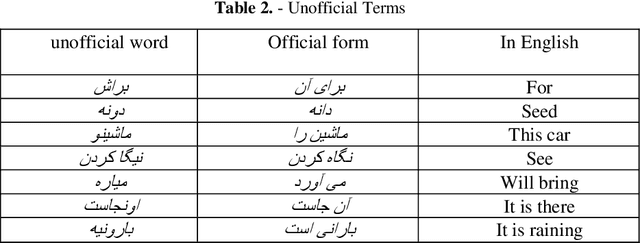
The rapid growth in data on the internet requires a data mining process to reach a decision to support insight. The Persian language has strong potential for deep research in any aspect of natural language processing, especially sentimental analysis approach. Thousands of websites and blogs updates and modifies by Persian users around the world that contains millions of Persian context. This range of application requires a comprehensive structured framework to extract beneficial information for helping enterprises to enhance their business and initiate a customer-centric management process by producing effective recommender systems. Sentimental analysis is an intelligent approach for extracting useful information from huge amounts of data to help an enterprise for smart management process. In this road, machine learning and deep learning techniques will become very helpful but there is the number of challenges which are face to them. This paper tried to present and assert the most important challenges of sentimental analysis in the Persian language. This language is an Indo-European language which spoken by over 110 million people around the world and is an official language in Iran, Tajikistan, and Afghanistan. Its also widely used in Uzbekistan, Pakistan and Turkish by order.