 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-based Sentiment Analysis in Persian Language
Mar 17, 2024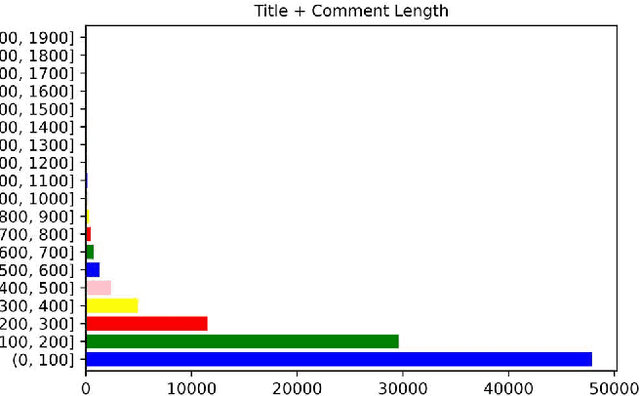


Recently, there has been a growing interest in the use of deep learning techniques for tasks in natural language processing (NLP), with sentiment analysis being one of the most challenging areas, particularly in the Persian language. The vast amounts of content generated by Persian users on thousands of websites, blogs, and social networks such as Telegram, Instagram, and Twitter present a rich resource of information. Deep learning techniques have become increasingly favored for extracting insights from this extensive pool of raw data, although they face several challenges. In this study, we introduced and implemented a hybrid deep learning-based model for sentiment analysis, using customer review data from the Digikala Online Retailer website. We employed a variety of deep learning networks and regularization techniques as classifiers. Ultimately, our hybrid approach yielded an impressive performance, achieving an F1 score of 78.3 across three sentiment categories: positive, negative, and neutral.
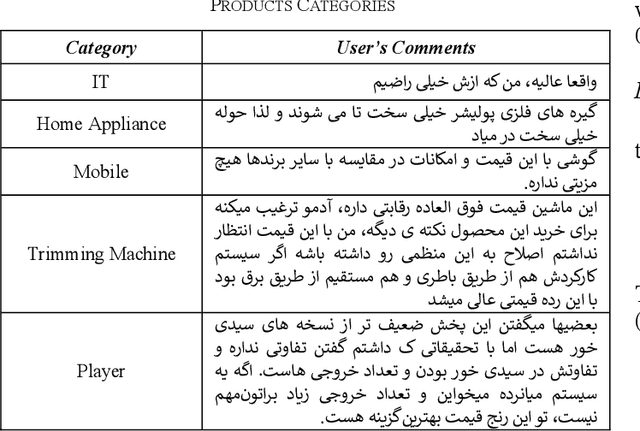
Persian Slang Text Conversion to Formal and Deep Learning of Persian Short Texts on Social Media for Sentiment Classification
Mar 09, 2024
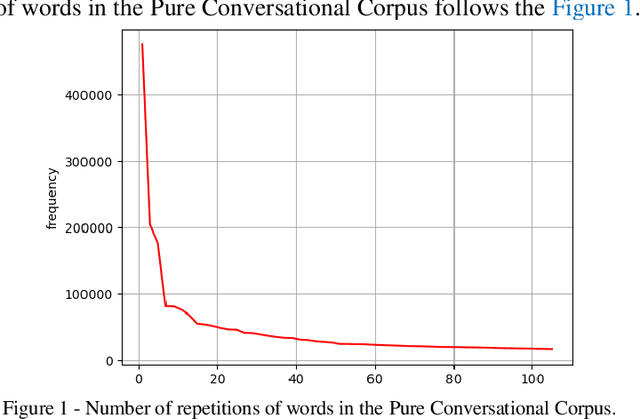

The lack of a suitable tool for the analysis of conversational texts in the Persian language has made various analyses of these texts, including Sentiment Analysis, difficult. In this research, we tried to make the understanding of these texts easier for the machine by providing PSC, Persian Slang Converter, a tool for converting conversational texts into formal ones, and by using the most up-to-date and best deep learning methods along with the PSC, the sentiment learning of short Persian language texts for the machine in a better way. be made More than 10 million unlabeled texts from various social networks and movie subtitles (as Conversational texts) and about 10 million news texts (as formal texts) have been used for training unsupervised models and formal implementation of the tool. 60,000 texts from the comments of Instagram social network users with positive, negative, and neutral labels are considered supervised data for training the emotion classification model of short texts. Using the formal tool, 57% of the words of the corpus of conversation were converted. Finally, by using the formalizer, FastText model, and deep LSTM network, an accuracy of 81.91 was obtained on the test data.