 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Multimodal Deep Learning Framework for Intelligent Fashion Recommendation
Nov 18, 2025


The rapid expansion of online fashion platforms has created an increasing demand for intelligent recommender systems capable of understanding both visual and textual cues. This paper proposes a hybrid multimodal deep learning framework for fashion recommendation that jointly addresses two key tasks: outfit compatibility prediction and complementary item retrieval. The model leverages the visual and textual encoders of the CLIP architecture to obtain joint latent representations of fashion items, which are then integrated into a unified feature vector and processed by a transformer encoder. For compatibility prediction, an "outfit token" is introduced to model the holistic relationships among items, achieving an AUC of 0.95 on the Polyvore dataset. For complementary item retrieval, a "target item token" representing the desired item description is used to retrieve compatible items, reaching an accuracy of 69.24% under the Fill-in-the-Blank (FITB) metric. The proposed approach demonstrates strong performance across both tasks, highlighting the effectiveness of multimodal learning for fashion recommendation.
Enhanced Sentiment Analysis of Iranian Restaurant Reviews Utilizing Sentiment Intensity Analyzer & Fuzzy Logic
Mar 15, 2025



This research presents an advanced sentiment analysis framework studied on Iranian restaurant reviews, combining fuzzy logic with conventional sentiment analysis techniques to assess both sentiment polarity and intensity. A dataset of 1266 reviews, alongside corresponding star ratings, was compiled and preprocessed for analysis. Initial sentiment analysis was conducted using the Sentiment Intensity Analyzer (VADER), a rule-based tool that assigns sentiment scores across positive, negative, and neutral categories. However, a noticeable bias toward neutrality often led to an inaccurate representation of sentiment intensity. To mitigate this issue, based on a fuzzy perspective, two refinement techniques were introduced, applying square-root and fourth-root transformations to amplify positive and negative sentiment scores while maintaining neutrality. This led to three distinct methodologies: Approach 1, utilizing unaltered VADER scores; Approach 2, modifying sentiment values using the square root; and Approach 3, applying the fourth root for further refinement. A Fuzzy Inference System incorporating comprehensive fuzzy rules was then developed to process these refined scores and generate a single, continuous sentiment value for each review based on each approach. Comparative analysis, including human supervision and alignment with customer star ratings, revealed that the refined approaches significantly improved sentiment analysis by reducing neutrality bias and better capturing sentiment intensity. Despite these advancements, minor over-amplification and persistent neutrality in domain-specific cases were identified, leading us to propose several future studies to tackle these occasional barriers. The study's methodology and outcomes offer valuable insights for businesses seeking a more precise understanding of consumer sentiment, enhancing sentiment analysis across various industries.
Sentiment-Driven Community Detection in a Network of Perfume Preferences
Oct 24, 2024



Network analysis is increasingly important across various fields, including the fragrance industry, where perfumes are represented as nodes and shared user preferences as edges in perfume networks. Community detection can uncover clusters of similar perfumes, providing insights into consumer preferences, enhancing recommendation systems, and informing targeted marketing strategies. This study aims to apply community detection techniques to group perfumes favored by users into relevant clusters for better recommendations. We constructed a bipartite network from user reviews on the Persian retail platform "Atrafshan," with nodes representing users and perfumes, and edges formed by positive comments. This network was transformed into a Perfume Co-Preference Network, connecting perfumes liked by the same users. By applying community detection algorithms, we identified clusters based on shared preferences, enhancing our understanding of user sentiment in the fragrance market. To improve sentiment analysis, we integrated emojis and a user voting system for greater accuracy. Emojis, aligned with their Persian counterparts, captured the emotional tone of reviews, while user ratings for scent, longevity, and sillage refined sentiment classification. Edge weights were adjusted by combining adjacency values with user ratings in a 60:40 ratio, reflecting both connection strength and user preferences. These enhancements led to improved modularity of detected communities, resulting in more accurate perfume groupings. This research pioneers the use of community detection in perfume networks, offering new insights into consumer preferences. Our advancements in sentiment analysis and edge weight refinement provide actionable insights for optimizing product recommendations and marketing strategies in the fragrance industry.
A Novel Method for Accurate & Real-time Food Classification: The Synergistic Integration of EfficientNetB7, CBAM, Transfer Learning, and Data Augmentation
Oct 03, 2024Integrating artificial intelligence into modern society is profoundly transformative, significantly enhancing productivity by streamlining various daily tasks. AI-driven recognition systems provide notable advantages in the food sector, including improved nutrient tracking, tackling food waste, and boosting food production and consumption efficiency. Accurate food classification is a crucial initial step in utilizing advanced AI models, as the effectiveness of this process directly influences the success of subsequent operations; therefore, achieving high accuracy at a reasonable speed is essential. Despite existing research efforts, a gap persists in improving performance while ensuring rapid processing times, prompting researchers to pursue cost-effective and precise models. This study addresses this gap by employing the state-of-the-art EfficientNetB7 architecture, enhanced through transfer learning, data augmentation, and the CBAM attention module. This methodology results in a robust model that surpasses previous studies in accuracy while maintaining rapid processing suitable for real-world applications. The Food11 dataset from Kaggle was utilized, comprising 16643 imbalanced images across 11 diverse classes with significant intra-category diversities and inter-category similarities. Furthermore, the proposed methodology, bolstered by various deep learning techniques, consistently achieves an impressive average accuracy of 96.40%. Notably, it can classify over 60 images within one second during inference on unseen data, demonstrating its ability to deliver high accuracy promptly. This underscores its potential for practical applications in accurate food classification and enhancing efficiency in subsequent processes.
Computer Vision in the Food Industry: Accurate, Real-time, and Automatic Food Recognition with Pretrained MobileNetV2
May 19, 2024


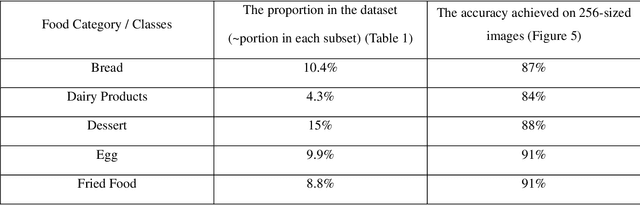
In contemporary society, the application of artificial intelligence for automatic food recognition offers substantial potential for nutrition tracking, reducing food waste, and enhancing productivity in food production and consumption scenarios. Modern technologies such as Computer Vision and Deep Learning are highly beneficial, enabling machines to learn automatically, thereby facilitating automatic visual recognition. Despite some research in this field, the challenge of achieving accurate automatic food recognition quickly remains a significant research gap. Some models have been developed and implemented, but maintaining high performance swiftly, with low computational cost and low access to expensive hardware accelerators, still needs further exploration and research. This study employs the pretrained MobileNetV2 model, which is efficient and fast, for food recognition on the public Food11 dataset, comprising 16643 images. It also utilizes various techniques such as dataset understanding, transfer learning, data augmentation, regularization, dynamic learning rate, hyperparameter tuning, and consideration of images in different sizes to enhance performance and robustness. These techniques aid in choosing appropriate metrics, achieving better performance, avoiding overfitting and accuracy fluctuations, speeding up the model, and increasing the generalization of findings, making the study and its results applicable to practical applications. Despite employing a light model with a simpler structure and fewer trainable parameters compared to some deep and dense models in the deep learning area, it achieved commendable accuracy in a short time. This underscores the potential for practical implementation, which is the main intention of this study.
Analysis of Persian News Agencies on Instagram, A Words Co-occurrence Graph-based Approach
Feb 19, 2024

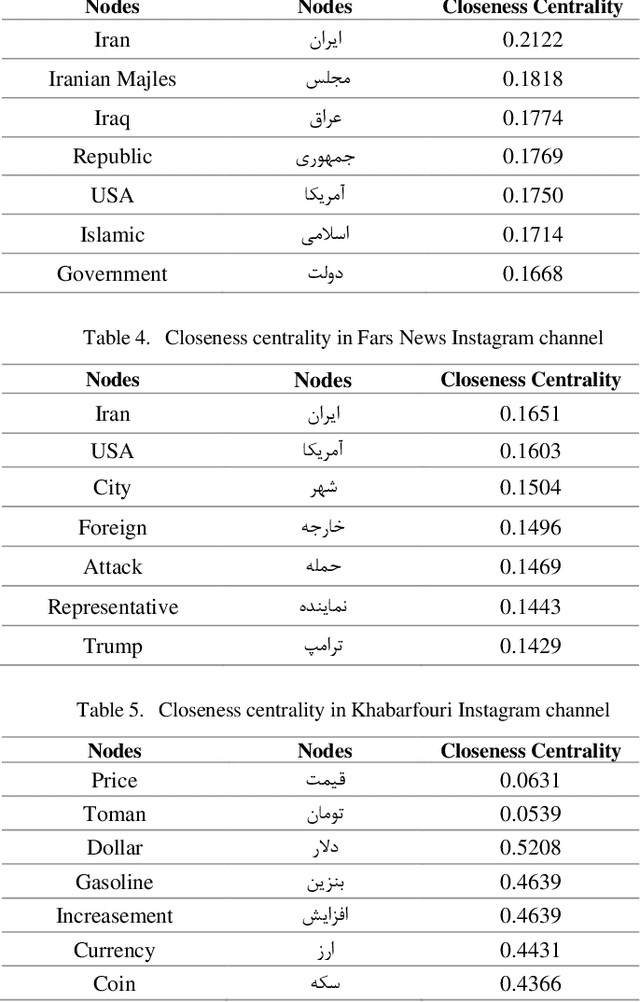
The rise of the Internet and the exponential increase in data have made manual data summarization and analysis a challenging task. Instagram social network is a prominent social network widely utilized in Iran for information sharing and communication across various age groups. The inherent structure of Instagram, characterized by its text-rich content and graph-like data representation, enables the utilization of text and graph processing techniques for data analysis purposes. The degree distributions of these networks exhibit scale-free characteristics, indicating non-random growth patterns. Recently, word co-occurrence has gained attention from researchers across multiple disciplines due to its simplicity and practicality. Keyword extraction is a crucial task in natural language processing. In this study, we demonstrated that high-precision extraction of keywords from Instagram posts in the Persian language can be achieved using unsupervised word co-occurrence methods without resorting to conventional techniques such as clustering or pre-trained models. After graph visualization and community detection, it was observed that the top topics covered by news agencies are represented by these graphs. This approach is generalizable to new and diverse datasets and can provide acceptable outputs for new data. To the author's knowledge, this method has not been employed in the Persian language before on Instagram social network. The new crawled data has been publicly released on GitHub for exploration by other researchers. By employing this method, it is possible to use other graph-based algorithms, such as community detections. The results help us to identify the key role of different news agencies in information diffusion among the public, identify hidden communities, and discover latent patterns among a massive amount of data.
Graph Representation Learning Towards Patents Network Analysis
Sep 25, 2023Patent analysis has recently been recognized as a powerful technique for large companies worldwide to lend them insight into the age of competition among various industries. This technique is considered a shortcut for developing countries since it can significantly accelerate their technology development. Therefore, as an inevitable process, patent analysis can be utilized to monitor rival companies and diverse industries. This research employed a graph representation learning approach to create, analyze, and find similarities in the patent data registered in the Iranian Official Gazette. The patent records were scrapped and wrangled through the Iranian Official Gazette portal. Afterward, the key entities were extracted from the scrapped patents dataset to create the Iranian patents graph from scratch based on novel natural language processing and entity resolution techniques. Finally, thanks to the utilization of novel graph algorithms and text mining methods, we identified new areas of industry and research from Iranian patent data, which can be used extensively to prevent duplicate patents, familiarity with similar and connected inventions, Awareness of legal entities supporting patents and knowledge of researchers and linked stakeholders in a particular research field.
A Food Recommender System in Academic Environments Based on Machine Learning Models
Jun 26, 2023Background: People's health depends on the use of proper diet as an important factor. Today, with the increasing mechanization of people's lives, proper eating habits and behaviors are neglected. On the other hand, food recommendations in the field of health have also tried to deal with this issue. But with the introduction of the Western nutrition style and the advancement of Western chemical medicine, many issues have emerged in the field of disease treatment and nutrition. Recent advances in technology and the use of artificial intelligence methods in information systems have led to the creation of recommender systems in order to improve people's health. Methods: A hybrid recommender system including, collaborative filtering, content-based, and knowledge-based models was used. Machine learning models such as Decision Tree, k-Nearest Neighbors (kNN), AdaBoost, and Bagging were investigated in the field of food recommender systems on 2519 students in the nutrition management system of a university. Student information including profile information for basal metabolic rate, student reservation records, and selected diet type is received online. Among the 15 features collected and after consulting nutrition experts, the most effective features are selected through feature engineering. Using machine learning models based on energy indicators and food selection history by students, food from the university menu is recommended to students. Results: The AdaBoost model has the highest performance in terms of accuracy with a rate of 73.70 percent. Conclusion: Considering the importance of diet in people's health, recommender systems are effective in obtaining useful information from a huge amount of data. Keywords: Recommender system, Food behavior and habits, Machine learning, Classification