 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive learning-based video quality assessment-jointed video vision transformer for video recognition
Mar 11, 2026Video quality significantly affects video classification. We found this problem when we classified Mild Cognitive Impairment well from clear videos, but worse from blurred ones. From then, we realized that referring to Video Quality Assessment (VQA) may improve video classification. This paper proposed Self-Supervised Learning-based Video Vision Transformer combined with No-reference VQA for video classification (SSL-V3) to fulfill the goal. SSL-V3 leverages Combined-SSL mechanism to join VQA into video classification and address the label shortage of VQA, which commonly occurs in video datasets, making it impossible to provide an accurate Video Quality Score. In brief, Combined-SSL takes video quality score as a factor to directly tune the feature map of the video classification. Then, the score, as an intersected point, links VQA and classification, using the supervised classification task to tune the parameters of VQA. SSL-V3 achieved robust experimental results on two datasets. For example, it reached an accuracy of 94.87% on some interview videos in the I-CONECT (a facial video-involved healthcare dataset), verifying SSL-V3's effectiveness.
* 9 figures, 10 tables,
AffectNet+: A Database for Enhancing Facial Expression Recognition with Soft-Labels
Oct 29, 2024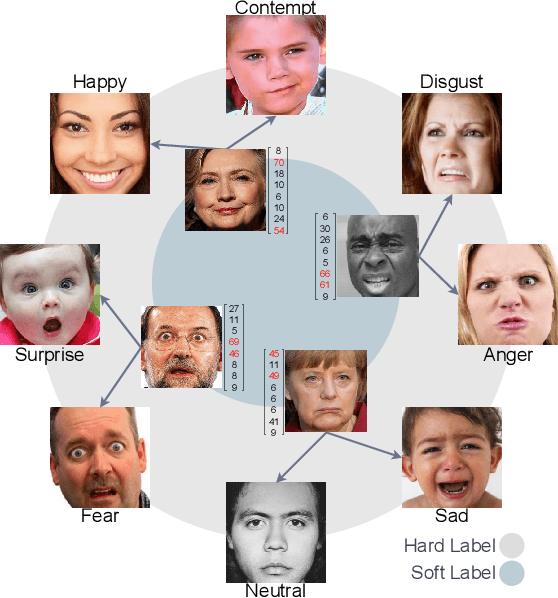
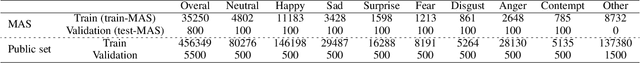
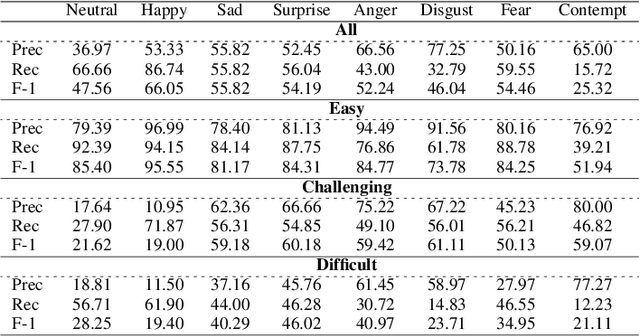
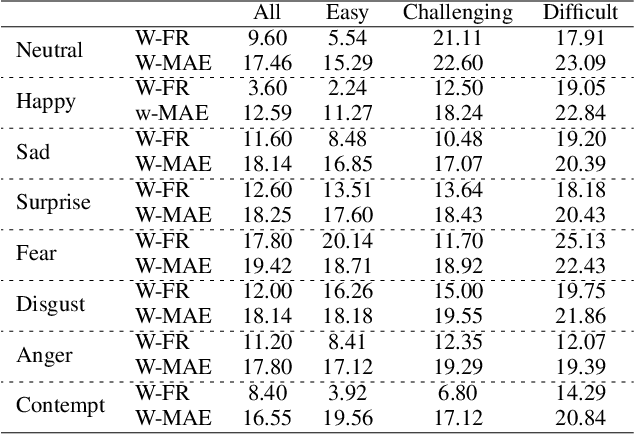
Automated Facial Expression Recognition (FER) is challenging due to intra-class variations and inter-class similarities. FER can be especially difficult when facial expressions reflect a mixture of various emotions (aka compound expressions). Existing FER datasets, such as AffectNet, provide discrete emotion labels (hard-labels), where a single category of emotion is assigned to an expression. To alleviate inter- and intra-class challenges, as well as provide a better facial expression descriptor, we propose a new approach to create FER datasets through a labeling method in which an image is labeled with more than one emotion (called soft-labels), each with different confidences. Specifically, we introduce the notion of soft-labels for facial expression datasets, a new approach to affective computing for more realistic recognition of facial expressions. To achieve this goal, we propose a novel methodology to accurately calculate soft-labels: a vector representing the extent to which multiple categories of emotion are simultaneously present within a single facial expression. Finding smoother decision boundaries, enabling multi-labeling, and mitigating bias and imbalanced data are some of the advantages of our proposed method. Building upon AffectNet, we introduce AffectNet+, the next-generation facial expression dataset. This dataset contains soft-labels, three categories of data complexity subsets, and additional metadata such as age, gender, ethnicity, head pose, facial landmarks, valence, and arousal. AffectNet+ will be made publicly accessible to researchers.
A Review of Deep Learning Approaches for Non-Invasive Cognitive Impairment Detection
Oct 25, 2024



This review paper explores recent advances in deep learning approaches for non-invasive cognitive impairment detection. We examine various non-invasive indicators of cognitive decline, including speech and language, facial, and motoric mobility. The paper provides an overview of relevant datasets, feature-extracting techniques, and deep-learning architectures applied to this domain. We have analyzed the performance of different methods across modalities and observed that speech and language-based methods generally achieved the highest detection performance. Studies combining acoustic and linguistic features tended to outperform those using a single modality. Facial analysis methods showed promise for visual modalities but were less extensively studied. Most papers focused on binary classification (impaired vs. non-impaired), with fewer addressing multi-class or regression tasks. Transfer learning and pre-trained language models emerged as popular and effective techniques, especially for linguistic analysis. Despite significant progress, several challenges remain, including data standardization and accessibility, model explainability, longitudinal analysis limitations, and clinical adaptation. Lastly, we propose future research directions, such as investigating language-agnostic speech analysis methods, developing multi-modal diagnostic systems, and addressing ethical considerations in AI-assisted healthcare. By synthesizing current trends and identifying key obstacles, this review aims to guide further development of deep learning-based cognitive impairment detection systems to improve early diagnosis and ultimately patient outcomes.
Data Quality Matters: Suicide Intention Detection on Social Media Posts Using a RoBERTa-CNN Model
Feb 03, 2024



Suicide remains a global health concern for the field of health, which urgently needs innovative approaches for early detection and intervention. In this paper, we focus on identifying suicidal intentions in SuicideWatch Reddit posts and present a novel approach to suicide detection using the cutting-edge RoBERTa-CNN model, a variant of RoBERTa (Robustly optimized BERT approach). RoBERTa is used for various Natural Language Processing (NLP) tasks, including text classification and sentiment analysis. The effectiveness of the RoBERTa lies in its ability to capture textual information and form semantic relationships within texts. By adding the Convolution Neural Network (CNN) layer to the original model, the RoBERTa enhances its ability to capture important patterns from heavy datasets. To evaluate the RoBERTa-CNN, we experimented on the Suicide and Depression Detection dataset and obtained solid results. For example, RoBERTa-CNN achieves 98% mean accuracy with the standard deviation (STD) of 0.0009. It also reaches over 97.5% mean AUC value with an STD of 0.0013. In the meanwhile, RoBERTa-CNN outperforms competitive methods, demonstrating the robustness and ability to capture nuanced linguistic patterns for suicidal intentions. Therefore, RoBERTa-CNN can detect suicide intention on text data very well.
Linguistic-Based Mild Cognitive Impairment Detection Using Informative Loss
Jan 23, 2024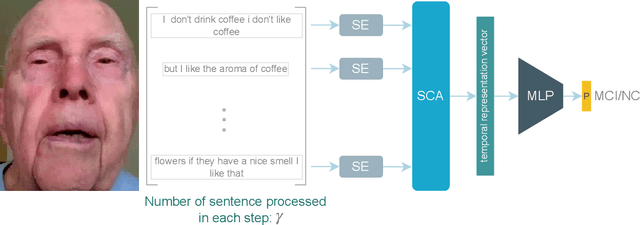

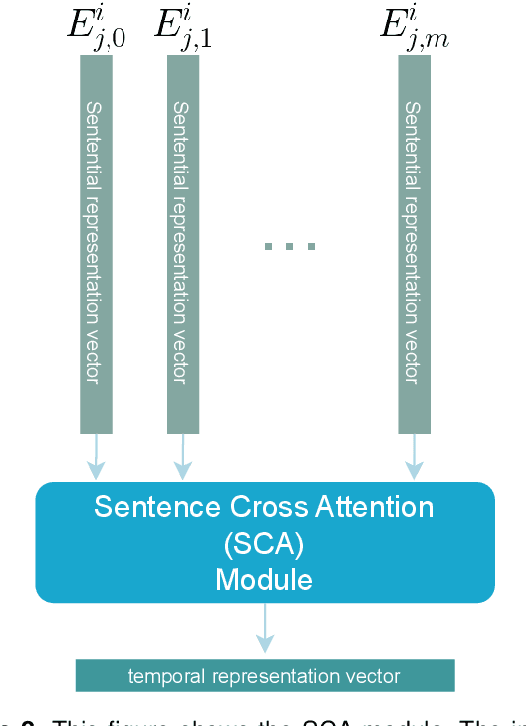
This paper presents a deep learning method using Natural Language Processing (NLP) techniques, to distinguish between Mild Cognitive Impairment (MCI) and Normal Cognitive (NC) conditions in older adults. We propose a framework that analyzes transcripts generated from video interviews collected within the I-CONECT study project, a randomized controlled trial aimed at improving cognitive functions through video chats. Our proposed NLP framework consists of two Transformer-based modules, namely Sentence Embedding (SE) and Sentence Cross Attention (SCA). First, the SE module captures contextual relationships between words within each sentence. Subsequently, the SCA module extracts temporal features from a sequence of sentences. This feature is then used by a Multi-Layer Perceptron (MLP) for the classification of subjects into MCI or NC. To build a robust model, we propose a novel loss function, called InfoLoss, that considers the reduction in entropy by observing each sequence of sentences to ultimately enhance the classification accuracy. The results of our comprehensive model evaluation using the I-CONECT dataset show that our framework can distinguish between MCI and NC with an average area under the curve of 84.75%.
Detection of Mild Cognitive Impairment Using Facial Features in Video Conversations
Aug 29, 2023



Early detection of Mild Cognitive Impairment (MCI) leads to early interventions to slow the progression from MCI into dementia. Deep Learning (DL) algorithms could help achieve early non-invasive, low-cost detection of MCI. This paper presents the detection of MCI in older adults using DL models based only on facial features extracted from video-recorded conversations at home. We used the data collected from the I-CONECT behavioral intervention study (NCT02871921), where several sessions of semi-structured interviews between socially isolated older individuals and interviewers were video recorded. We develop a framework that extracts spatial holistic facial features using a convolutional autoencoder and temporal information using transformers. Our proposed DL model was able to detect the I-CONECT study participants' cognitive conditions (MCI vs. those with normal cognition (NC)) using facial features. The segments and sequence information of the facial features improved the prediction performance compared with the non-temporal features. The detection accuracy using this combined method reached 88% whereas 84% is the accuracy without applying the segments and sequences information of the facial features within a video on a certain theme.
MC-ViViT: Multi-branch Classifier-ViViT to Detect Mild Cognitive Impairment in Older Adults using Facial Videos
Apr 11, 2023Deep machine learning models including Convolutional Neural Networks (CNN) have been successful in the detection of Mild Cognitive Impairment (MCI) using medical images, questionnaires, and videos. This paper proposes a novel Multi-branch Classifier-Video Vision Transformer (MC-ViViT) model to distinguish MCI from those with normal cognition by analyzing facial features. The data comes from the I-CONECT, a behavioral intervention trial aimed at improving cognitive function by providing frequent video chats. MC-ViViT extracts spatiotemporal features of videos in one branch and augments representations by the MC module. The I-CONECT dataset is challenging as the dataset is imbalanced containing Hard-Easy and Positive-Negative samples, which impedes the performance of MC-ViViT. We propose a loss function for Hard-Easy and Positive-Negative Samples (HP Loss) by combining Focal loss and AD-CORRE loss to address the imbalanced problem. Our experimental results on the I-CONECT dataset show the great potential of MC-ViViT in predicting MCI with a high accuracy of 90.63\% accuracy on some of the interview videos.
GANalyzer: Analysis and Manipulation of GANs Latent Space for Controllable Face Synthesis
Feb 02, 2023Generative Adversarial Networks (GANs) are capable of synthesizing high-quality facial images. Despite their success, GANs do not provide any information about the relationship between the input vectors and the generated images. Currently, facial GANs are trained on imbalanced datasets, which generate less diverse images. For example, more than 77% of 100K images that we randomly synthesized using the StyleGAN3 are classified as Happy, and only around 3% are Angry. The problem even becomes worse when a mixture of facial attributes is desired: less than 1% of the generated samples are Angry Woman, and only around 2% are Happy Black. To address these problems, this paper proposes a framework, called GANalyzer, for the analysis, and manipulation of the latent space of well-trained GANs. GANalyzer consists of a set of transformation functions designed to manipulate latent vectors for a specific facial attribute such as facial Expression, Age, Gender, and Race. We analyze facial attribute entanglement in the latent space of GANs and apply the proposed transformation for editing the disentangled facial attributes. Our experimental results demonstrate the strength of GANalyzer in editing facial attributes and generating any desired faces. We also create and release a balanced photo-realistic human face dataset. Our code is publicly available on GitHub.
Deep Learning Methods for Fingerprint-Based Indoor Positioning: A Review
May 30, 2022Outdoor positioning systems based on the Global Navigation Satellite System have several shortcomings that have deemed their use for indoor positioning impractical. Location fingerprinting, which utilizes machine learning, has emerged as a viable method and solution for indoor positioning due to its simple concept and accurate performance. In the past, shallow learning algorithms were traditionally used in location fingerprinting. Recently, the research community started utilizing deep learning methods for fingerprinting after witnessing the great success and superiority these methods have over traditional/shallow machine learning algorithms. This paper provides a comprehensive review of deep learning methods in indoor positioning. First, the advantages and disadvantages of various fingerprint types for indoor positioning are discussed. The solutions proposed in the literature are then analyzed, categorized, and compared against various performance evaluation metrics. Since data is key in fingerprinting, a detailed review of publicly available indoor positioning datasets is presented. While incorporating deep learning into fingerprinting has resulted in significant improvements, doing so, has also introduced new challenges. These challenges along with the common implementation pitfalls are discussed. Finally, the paper is concluded with some remarks as well as future research trends.
OutFin, a multi-device and multi-modal dataset for outdoor localization based on the fingerprinting approach
May 30, 2022In recent years, fingerprint-based positioning has gained researchers attention since it is a promising alternative to the Global Navigation Satellite System and cellular network-based localization in urban areas. Despite this, the lack of publicly available datasets that researchers can use to develop, evaluate, and compare fingerprint-based positioning solutions constitutes a high entry barrier for studies. As an effort to overcome this barrier and foster new research efforts, this paper presents OutFin, a novel dataset of outdoor location fingerprints that were collected using two different smartphones. OutFin is comprised of diverse data types such as WiFi, Bluetooth, and cellular signal strengths, in addition to measurements from various sensors including the magnetometer, accelerometer, gyroscope, barometer, and ambient light sensor. The collection area spanned four dispersed sites with a total of 122 reference points. Each site is different in terms of its visibility to the Global Navigation Satellite System and reference points number, arrangement, and spacing. Before OutFin was made available to the public, several experiments were conducted to validate its technical quality.