 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Deep Learning Approaches for Non-Invasive Cognitive Impairment Detection
Oct 25, 2024



This review paper explores recent advances in deep learning approaches for non-invasive cognitive impairment detection. We examine various non-invasive indicators of cognitive decline, including speech and language, facial, and motoric mobility. The paper provides an overview of relevant datasets, feature-extracting techniques, and deep-learning architectures applied to this domain. We have analyzed the performance of different methods across modalities and observed that speech and language-based methods generally achieved the highest detection performance. Studies combining acoustic and linguistic features tended to outperform those using a single modality. Facial analysis methods showed promise for visual modalities but were less extensively studied. Most papers focused on binary classification (impaired vs. non-impaired), with fewer addressing multi-class or regression tasks. Transfer learning and pre-trained language models emerged as popular and effective techniques, especially for linguistic analysis. Despite significant progress, several challenges remain, including data standardization and accessibility, model explainability, longitudinal analysis limitations, and clinical adaptation. Lastly, we propose future research directions, such as investigating language-agnostic speech analysis methods, developing multi-modal diagnostic systems, and addressing ethical considerations in AI-assisted healthcare. By synthesizing current trends and identifying key obstacles, this review aims to guide further development of deep learning-based cognitive impairment detection systems to improve early diagnosis and ultimately patient outcomes.
Linguistic-Based Mild Cognitive Impairment Detection Using Informative Loss
Jan 23, 2024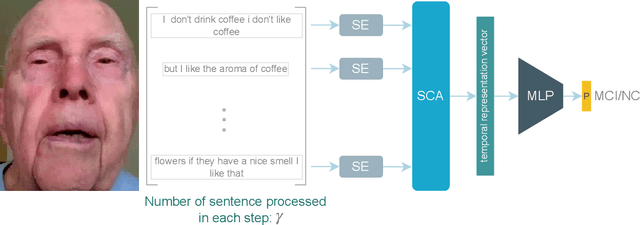

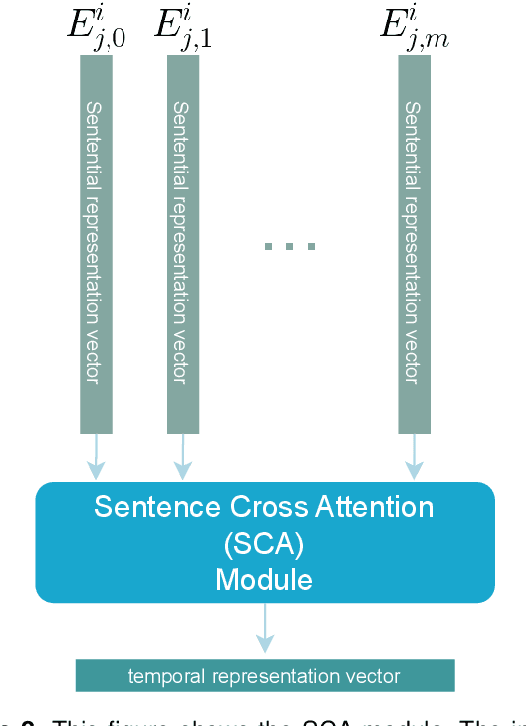
This paper presents a deep learning method using Natural Language Processing (NLP) techniques, to distinguish between Mild Cognitive Impairment (MCI) and Normal Cognitive (NC) conditions in older adults. We propose a framework that analyzes transcripts generated from video interviews collected within the I-CONECT study project, a randomized controlled trial aimed at improving cognitive functions through video chats. Our proposed NLP framework consists of two Transformer-based modules, namely Sentence Embedding (SE) and Sentence Cross Attention (SCA). First, the SE module captures contextual relationships between words within each sentence. Subsequently, the SCA module extracts temporal features from a sequence of sentences. This feature is then used by a Multi-Layer Perceptron (MLP) for the classification of subjects into MCI or NC. To build a robust model, we propose a novel loss function, called InfoLoss, that considers the reduction in entropy by observing each sequence of sentences to ultimately enhance the classification accuracy. The results of our comprehensive model evaluation using the I-CONECT dataset show that our framework can distinguish between MCI and NC with an average area under the curve of 84.75%.
Detection of Mild Cognitive Impairment Using Facial Features in Video Conversations
Aug 29, 2023



Early detection of Mild Cognitive Impairment (MCI) leads to early interventions to slow the progression from MCI into dementia. Deep Learning (DL) algorithms could help achieve early non-invasive, low-cost detection of MCI. This paper presents the detection of MCI in older adults using DL models based only on facial features extracted from video-recorded conversations at home. We used the data collected from the I-CONECT behavioral intervention study (NCT02871921), where several sessions of semi-structured interviews between socially isolated older individuals and interviewers were video recorded. We develop a framework that extracts spatial holistic facial features using a convolutional autoencoder and temporal information using transformers. Our proposed DL model was able to detect the I-CONECT study participants' cognitive conditions (MCI vs. those with normal cognition (NC)) using facial features. The segments and sequence information of the facial features improved the prediction performance compared with the non-temporal features. The detection accuracy using this combined method reached 88% whereas 84% is the accuracy without applying the segments and sequences information of the facial features within a video on a certain theme.