 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffectNet+: A Database for Enhancing Facial Expression Recognition with Soft-Labels
Oct 29, 2024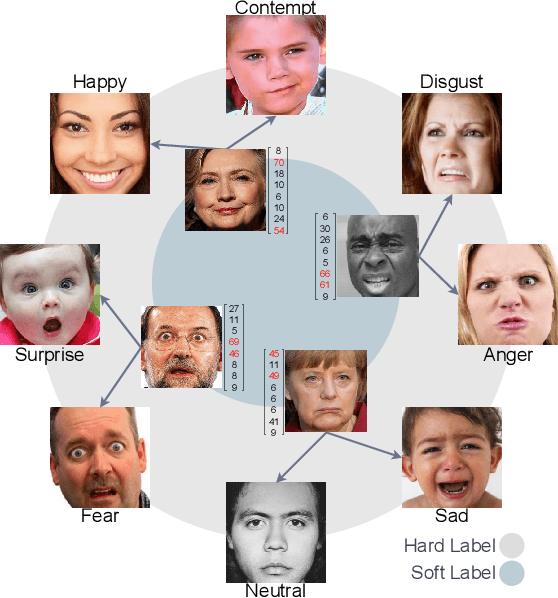
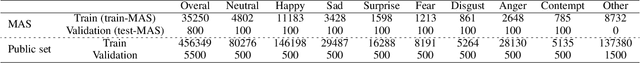
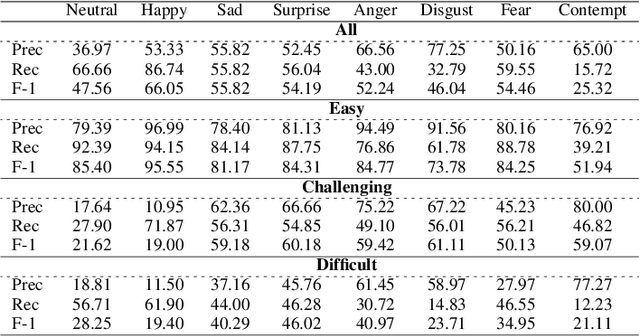
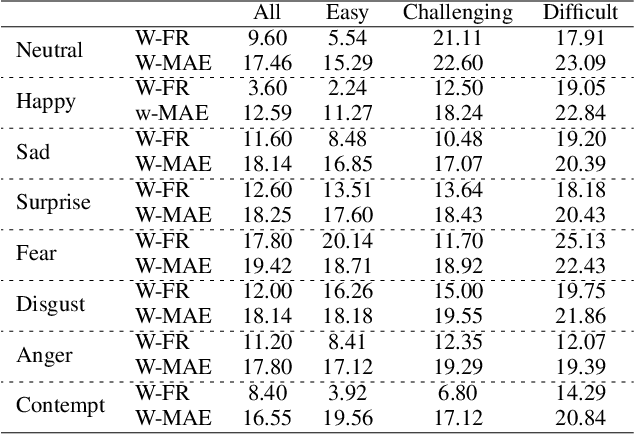
Automated Facial Expression Recognition (FER) is challenging due to intra-class variations and inter-class similarities. FER can be especially difficult when facial expressions reflect a mixture of various emotions (aka compound expressions). Existing FER datasets, such as AffectNet, provide discrete emotion labels (hard-labels), where a single category of emotion is assigned to an expression. To alleviate inter- and intra-class challenges, as well as provide a better facial expression descriptor, we propose a new approach to create FER datasets through a labeling method in which an image is labeled with more than one emotion (called soft-labels), each with different confidences. Specifically, we introduce the notion of soft-labels for facial expression datasets, a new approach to affective computing for more realistic recognition of facial expressions. To achieve this goal, we propose a novel methodology to accurately calculate soft-labels: a vector representing the extent to which multiple categories of emotion are simultaneously present within a single facial expression. Finding smoother decision boundaries, enabling multi-labeling, and mitigating bias and imbalanced data are some of the advantages of our proposed method. Building upon AffectNet, we introduce AffectNet+, the next-generation facial expression dataset. This dataset contains soft-labels, three categories of data complexity subsets, and additional metadata such as age, gender, ethnicity, head pose, facial landmarks, valence, and arousal. AffectNet+ will be made publicly accessible to researchers.
Toward Real-Time Image Annotation Using Marginalized Coupled Dictionary Learning
Apr 17, 2023In most image retrieval systems, images include various high-level semantics, called tags or annotations. Virtually all the state-of-the-art image annotation methods that handle imbalanced labeling are search-based techniques which are time-consuming. In this paper, a novel coupled dictionary learning approach is proposed to learn a limited number of visual prototypes and their corresponding semantics simultaneously. This approach leads to a real-time image annotation procedure. Another contribution of this paper is that utilizes a marginalized loss function instead of the squared loss function that is inappropriate for image annotation with imbalanced labels. We have employed a marginalized loss function in our method to leverage a simple and effective method of prototype updating. Meanwhile, we have introduced ${\ell}_1$ regularization on semantic prototypes to preserve the sparse and imbalanced nature of labels in learned semantic prototypes. Finally, comprehensive experimental results on various datasets demonstrate the efficiency of the proposed method for image annotation tasks in terms of accuracy and time. The reference implementation is publicly available on https://github.com/hamid-amiri/MCDL-Image-Annotation.
* @article{roostaiyan2022toward, title={Toward real-time image annotation using marginalized coupled dictionary learning}, author={Roostaiyan, Seyed Mahdi and Hosseini, Mohammad Mehdi and Kashani, Mahya Mohammadi and Amiri, S Hamid}, journal={Journal of Real-Time Image Processing}, volume={19}, number={3}, pages={623--638}, year={2022}, publisher={Springer} }