 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Guided Symbolic Regression with Semantic Prior
Jan 23, 2019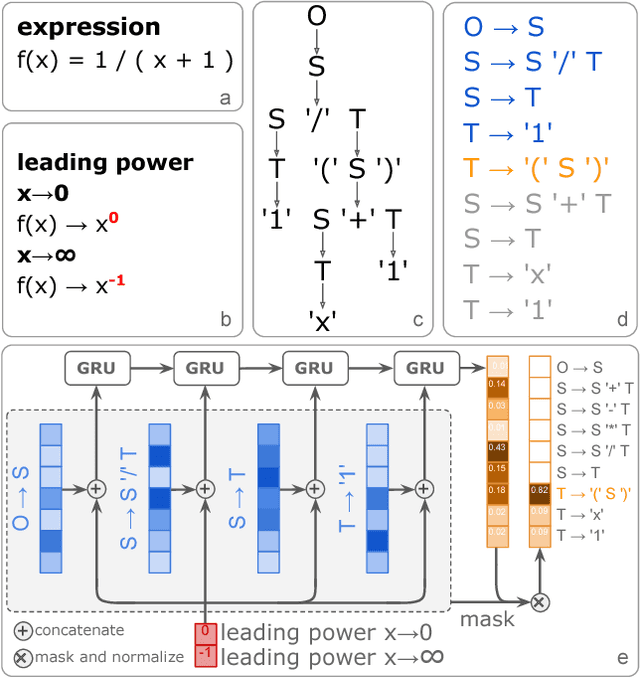
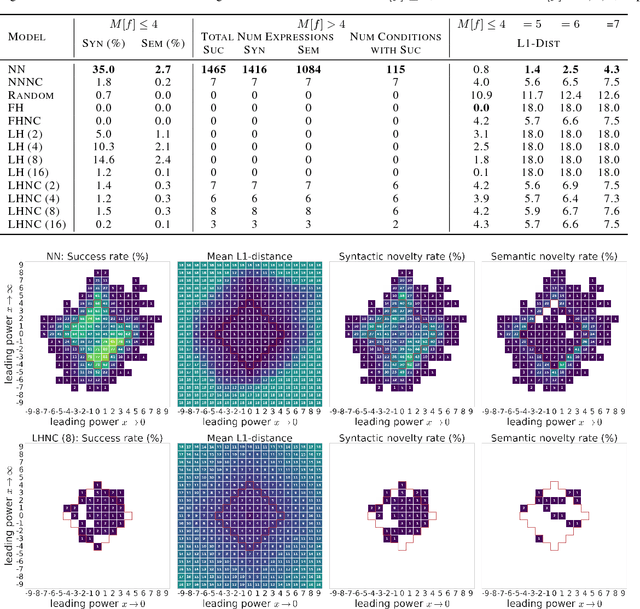

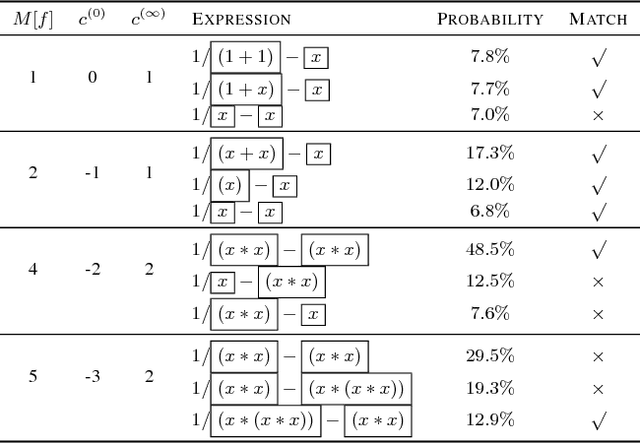
Symbolic regression has been shown to be quite useful in many domains from discovering scientific laws to industrial empirical modeling. Existing methods focus on numerically fitting the given data. However, in many domains, symbolically derivable properties of the desired expressions are known. We illustrate these "semantic priors" with leading powers (the polynomial behavior as the input approaches 0 and $\infty$). We introduce an expression generating neural network that significantly favors the generation of expressions with desired leading powers, even generalizing to powers not in the training set. We then describe our Neural-Guided Monte Carlo Tree Search (NG-MCTS) algorithm for symbolic regression. We extensively evaluate our method on thousands of symbolic regression tasks and desired expressions to show that it significantly outperforms baseline algorithms and exhibits discovery of novel expressions outside of the training set.
Correcting Nuisance Variation using Wasserstein Distance
Nov 02, 2017
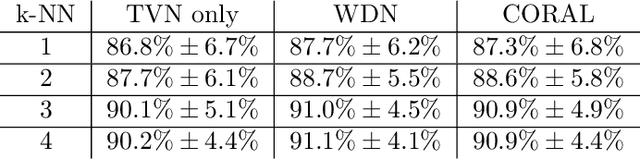
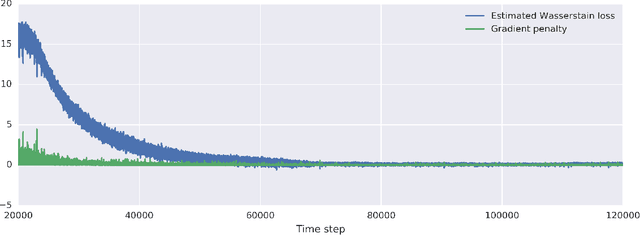
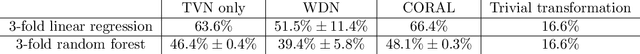
Profiling cellular phenotypes from microscopic imaging can provide meaningful biological information resulting from various factors affecting the cells. One motivating application is drug development: morphological cell features can be captured from images, from which similarities between different drugs applied at different dosages can be quantified. The general approach is to find a function mapping the images to an embedding space of manageable dimensionality whose geometry captures relevant features of the input images. An important known issue for such methods is separating relevant biological signal from nuisance variation. For example, the embedding vectors tend to be more correlated for cells that were cultured and imaged during the same week than for cells from a different week, despite having identical drug compounds applied in both cases. In this case, the particular batch a set of experiments were conducted in constitutes the domain of the data; an ideal set of image embeddings should contain only the relevant biological information (e.g. drug effects). We develop a method for adjusting the image embeddings in order to `forget' domain-specific information while preserving relevant biological information. To do this, we minimize a loss function based on the Wasserstein distance. We find for our transformed embeddings (1) the underlying geometric structure is preserved and (2) less domain-specific information is present.