 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLagrangian Relaxation Score-based Generation for Mixed Integer linear Programming
Mar 25, 2026Predict-and-search (PaS) methods have shown promise for accelerating mixed-integer linear programming (MILP) solving. However, existing approaches typically assume variable independence and rely on deterministic single-point predictions, which limits solution diversityand often necessitates extensive downstream search for high-quality solutions. In this paper, we propose \textbf{SRG}, a generative framework based on Lagrangian relaxation-guided stochastic differential equations (SDEs), with theoretical guarantees on solution quality. SRG leverages convolutional kernels to capture inter-variable dependencies while integrating Lagrangian relaxation to guide the sampling process toward feasible and near-optimal regions. Rather than producing a single estimate, SRG generates diverse, high-quality solution candidates that collectively define compact and effective trust-region subproblems for standard MILP solvers. Across multiple public benchmarks, SRG consistently outperforms existing machine learning baselines in solution quality. Moreover, SRG demonstrates strong zero-shot transferability: on unseen cross-scale/problem instances, it achieves competitive optimality with state-of-the-art exact solvers while significantly reducing computational overhead through faster search and superior solution quality.
Offline Meta-Reinforcement Learning with Flow-Based Task Inference and Adaptive Correction of Feature Overgeneralization
Jan 12, 2026Offline meta-reinforcement learning (OMRL) combines the strengths of learning from diverse datasets in offline RL with the adaptability to new tasks of meta-RL, promising safe and efficient knowledge acquisition by RL agents. However, OMRL still suffers extrapolation errors due to out-of-distribution (OOD) actions, compromised by broad task distributions and Markov Decision Process (MDP) ambiguity in meta-RL setups. Existing research indicates that the generalization of the $Q$ network affects the extrapolation error in offline RL. This paper investigates this relationship by decomposing the $Q$ value into feature and weight components, observing that while decomposition enhances adaptability and convergence in the case of high-quality data, it often leads to policy degeneration or collapse in complex tasks. We observe that decomposed $Q$ values introduce a large estimation bias when the feature encounters OOD samples, a phenomenon we term ''feature overgeneralization''. To address this issue, we propose FLORA, which identifies OOD samples by modeling feature distributions and estimating their uncertainties. FLORA integrates a return feedback mechanism to adaptively adjust feature components. Furthermore, to learn precise task representations, FLORA explicitly models the complex task distribution using a chain of invertible transformations. We theoretically and empirically demonstrate that FLORA achieves rapid adaptation and meta-policy improvement compared to baselines across various environments.
Wavelet Predictive Representations for Non-Stationary Reinforcement Learning
Oct 06, 2025The real world is inherently non-stationary, with ever-changing factors, such as weather conditions and traffic flows, making it challenging for agents to adapt to varying environmental dynamics. Non-Stationary Reinforcement Learning (NSRL) addresses this challenge by training agents to adapt rapidly to sequences of distinct Markov Decision Processes (MDPs). However, existing NSRL approaches often focus on tasks with regularly evolving patterns, leading to limited adaptability in highly dynamic settings. Inspired by the success of Wavelet analysis in time series modeling, specifically its ability to capture signal trends at multiple scales, we propose WISDOM to leverage wavelet-domain predictive task representations to enhance NSRL. WISDOM captures these multi-scale features in evolving MDP sequences by transforming task representation sequences into the wavelet domain, where wavelet coefficients represent both global trends and fine-grained variations of non-stationary changes. In addition to the auto-regressive modeling commonly employed in time series forecasting, we devise a wavelet temporal difference (TD) update operator to enhance tracking and prediction of MDP evolution. We theoretically prove the convergence of this operator and demonstrate policy improvement with wavelet task representations. Experiments on diverse benchmarks show that WISDOM significantly outperforms existing baselines in both sample efficiency and asymptotic performance, demonstrating its remarkable adaptability in complex environments characterized by non-stationary and stochastically evolving tasks.
Towards Control-Centric Representations in Reinforcement Learning from Images
Oct 27, 2023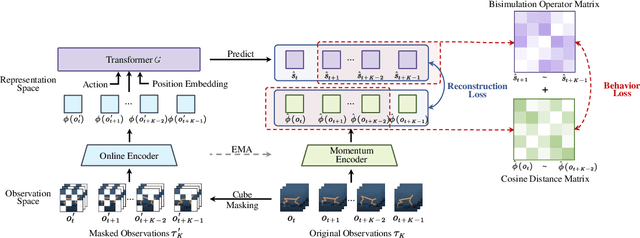



Image-based Reinforcement Learning is a practical yet challenging task. A major hurdle lies in extracting control-centric representations while disregarding irrelevant information. While approaches that follow the bisimulation principle exhibit the potential in learning state representations to address this issue, they still grapple with the limited expressive capacity of latent dynamics and the inadaptability to sparse reward environments. To address these limitations, we introduce ReBis, which aims to capture control-centric information by integrating reward-free control information alongside reward-specific knowledge. ReBis utilizes a transformer architecture to implicitly model the dynamics and incorporates block-wise masking to eliminate spatiotemporal redundancy. Moreover, ReBis combines bisimulation-based loss with asymmetric reconstruction loss to prevent feature collapse in environments with sparse rewards. Empirical studies on two large benchmarks, including Atari games and DeepMind Control Suit, demonstrate that ReBis has superior performance compared to existing methods, proving its effectiveness.
SimSR: Simple Distance-based State Representation for Deep Reinforcement Learning
Dec 31, 2021
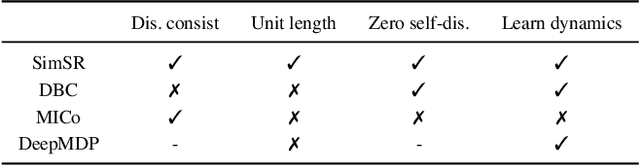


This work explores how to learn robust and generalizable state representation from image-based observations with deep reinforcement learning methods. Addressing the computational complexity, stringent assumptions, and representation collapse challenges in the existing work of bisimulation metric, we devise Simple State Representation (SimSR) operator, which achieves equivalent functionality while reducing the complexity by an order in comparison with bisimulation metric. SimSR enables us to design a stochastic-approximation-based method that can practically learn the mapping functions (encoders) from observations to latent representation space. Besides the theoretical analysis, we experimented and compared our work with recent state-of-the-art solutions in visual MuJoCo tasks. The results show that our model generally achieves better performance and has better robustness and good generalization.
GANE: A Generative Adversarial Network Embedding
May 21, 2018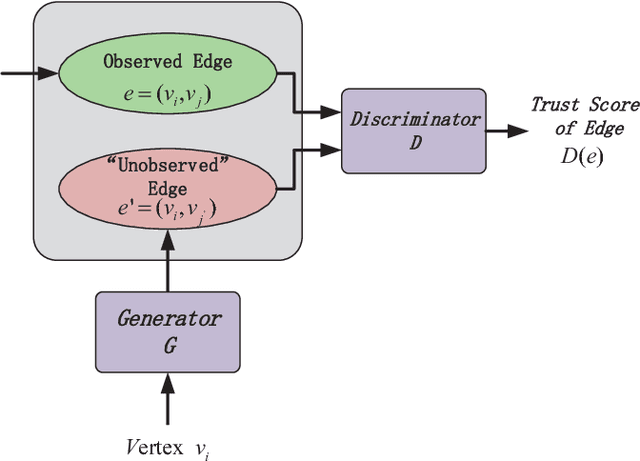


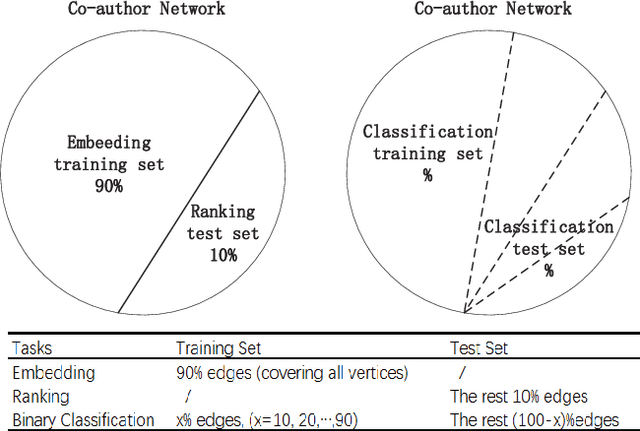
Network embedding has become a hot research topic recently which can provide low-dimensional feature representations for many machine learning applications. Current work focuses on either (1) whether the embedding is designed as an unsupervised learning task by explicitly preserving the structural connectivity in the network, or (2) whether the embedding is a by-product during the supervised learning of a specific discriminative task in a deep neural network. In this paper, we focus on bridging the gap of the two lines of the research. We propose to adapt the Generative Adversarial model to perform network embedding, in which the generator is trying to generate vertex pairs, while the discriminator tries to distinguish the generated vertex pairs from real connections (edges) in the network. Wasserstein-1 distance is adopted to train the generator to gain better stability. We develop three variations of models, including GANE which applies cosine similarity, GANE-O1 which preserves the first-order proximity, and GANE-O2 which tries to preserves the second-order proximity of the network in the low-dimensional embedded vector space. We later prove that GANE-O2 has the same objective function as GANE-O1 when negative sampling is applied to simplify the training process in GANE-O2. Experiments with real-world network datasets demonstrate that our models constantly outperform state-of-the-art solutions with significant improvements on precision in link prediction, as well as on visualizations and accuracy in clustering tasks.