 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Control-Centric Representations in Reinforcement Learning from Images
Oct 27, 2023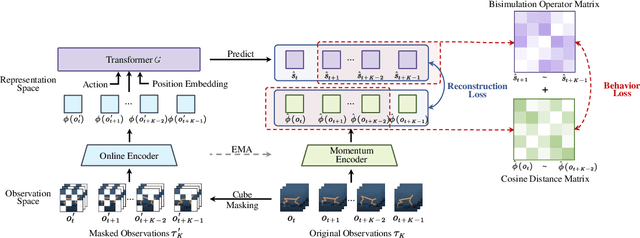



Image-based Reinforcement Learning is a practical yet challenging task. A major hurdle lies in extracting control-centric representations while disregarding irrelevant information. While approaches that follow the bisimulation principle exhibit the potential in learning state representations to address this issue, they still grapple with the limited expressive capacity of latent dynamics and the inadaptability to sparse reward environments. To address these limitations, we introduce ReBis, which aims to capture control-centric information by integrating reward-free control information alongside reward-specific knowledge. ReBis utilizes a transformer architecture to implicitly model the dynamics and incorporates block-wise masking to eliminate spatiotemporal redundancy. Moreover, ReBis combines bisimulation-based loss with asymmetric reconstruction loss to prevent feature collapse in environments with sparse rewards. Empirical studies on two large benchmarks, including Atari games and DeepMind Control Suit, demonstrate that ReBis has superior performance compared to existing methods, proving its effectiveness.
Good Better Best: Self-Motivated Imitation Learning for noisy Demonstrations
Oct 24, 2023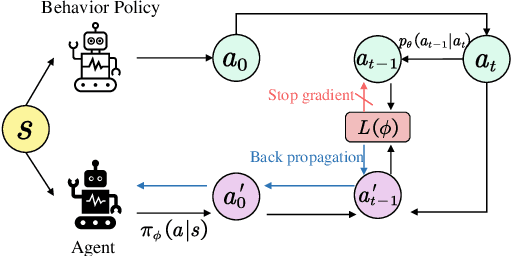

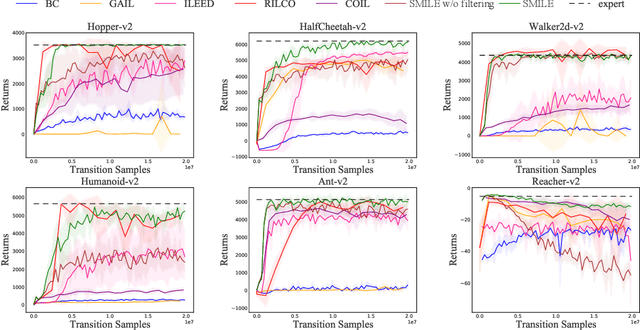

Imitation Learning (IL) aims to discover a policy by minimizing the discrepancy between the agent's behavior and expert demonstrations. However, IL is susceptible to limitations imposed by noisy demonstrations from non-expert behaviors, presenting a significant challenge due to the lack of supplementary information to assess their expertise. In this paper, we introduce Self-Motivated Imitation LEarning (SMILE), a method capable of progressively filtering out demonstrations collected by policies deemed inferior to the current policy, eliminating the need for additional information. We utilize the forward and reverse processes of Diffusion Models to emulate the shift in demonstration expertise from low to high and vice versa, thereby extracting the noise information that diffuses expertise. Then, the noise information is leveraged to predict the diffusion steps between the current policy and demonstrators, which we theoretically demonstrate its equivalence to their expertise gap. We further explain in detail how the predicted diffusion steps are applied to filter out noisy demonstrations in a self-motivated manner and provide its theoretical grounds. Through empirical evaluations on MuJoCo tasks, we demonstrate that our method is proficient in learning the expert policy amidst noisy demonstrations, and effectively filters out demonstrations with expertise inferior to the current policy.