 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Addressing the Pitfalls of Bisimulation-based Representations in Offline Reinforcement Learning
Oct 26, 2023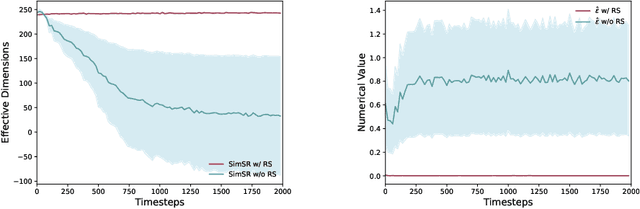
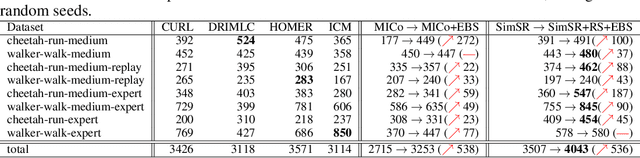
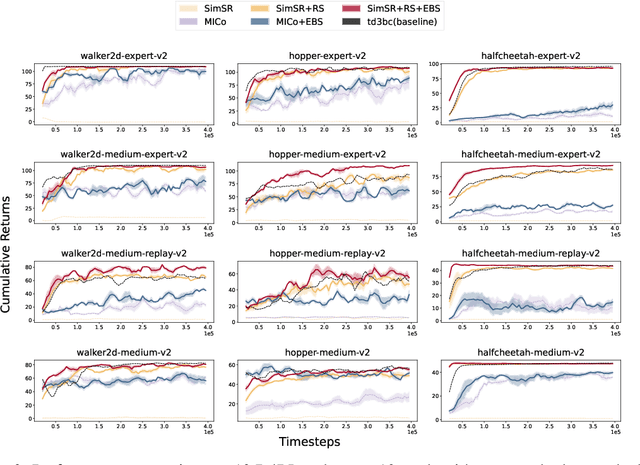
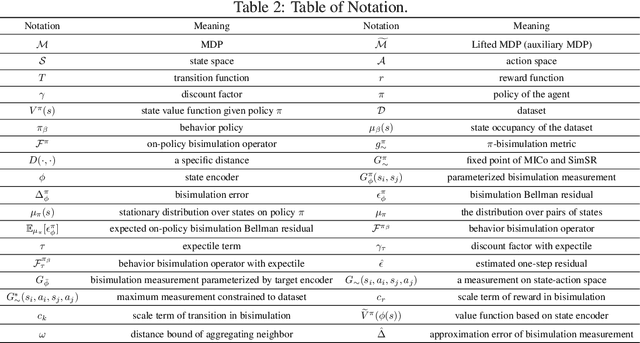
While bisimulation-based approaches hold promise for learning robust state representations for Reinforcement Learning (RL) tasks, their efficacy in offline RL tasks has not been up to par. In some instances, their performance has even significantly underperformed alternative methods. We aim to understand why bisimulation methods succeed in online settings, but falter in offline tasks. Our analysis reveals that missing transitions in the dataset are particularly harmful to the bisimulation principle, leading to ineffective estimation. We also shed light on the critical role of reward scaling in bounding the scale of bisimulation measurements and of the value error they induce. Based on these findings, we propose to apply the expectile operator for representation learning to our offline RL setting, which helps to prevent overfitting to incomplete data. Meanwhile, by introducing an appropriate reward scaling strategy, we avoid the risk of feature collapse in representation space. We implement these recommendations on two state-of-the-art bisimulation-based algorithms, MICo and SimSR, and demonstrate performance gains on two benchmark suites: D4RL and Visual D4RL. Codes are provided at \url{https://github.com/zanghyu/Offline_Bisimulation}.
Good Better Best: Self-Motivated Imitation Learning for noisy Demonstrations
Oct 24, 2023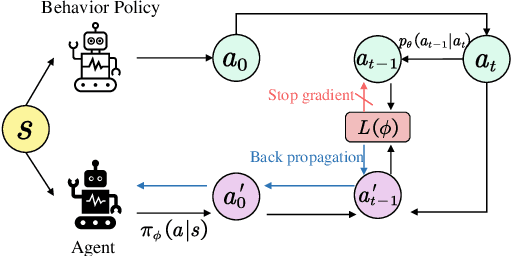

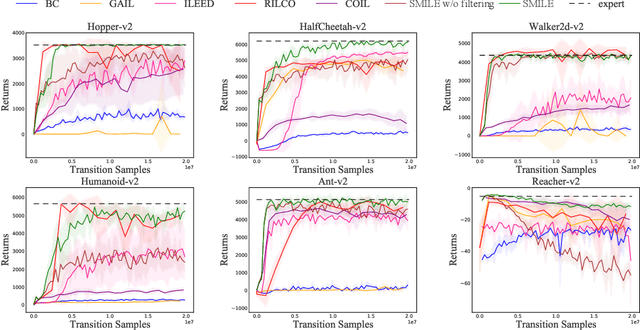

Imitation Learning (IL) aims to discover a policy by minimizing the discrepancy between the agent's behavior and expert demonstrations. However, IL is susceptible to limitations imposed by noisy demonstrations from non-expert behaviors, presenting a significant challenge due to the lack of supplementary information to assess their expertise. In this paper, we introduce Self-Motivated Imitation LEarning (SMILE), a method capable of progressively filtering out demonstrations collected by policies deemed inferior to the current policy, eliminating the need for additional information. We utilize the forward and reverse processes of Diffusion Models to emulate the shift in demonstration expertise from low to high and vice versa, thereby extracting the noise information that diffuses expertise. Then, the noise information is leveraged to predict the diffusion steps between the current policy and demonstrators, which we theoretically demonstrate its equivalence to their expertise gap. We further explain in detail how the predicted diffusion steps are applied to filter out noisy demonstrations in a self-motivated manner and provide its theoretical grounds. Through empirical evaluations on MuJoCo tasks, we demonstrate that our method is proficient in learning the expert policy amidst noisy demonstrations, and effectively filters out demonstrations with expertise inferior to the current policy.