 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Addressing the Pitfalls of Bisimulation-based Representations in Offline Reinforcement Learning
Paper and Code
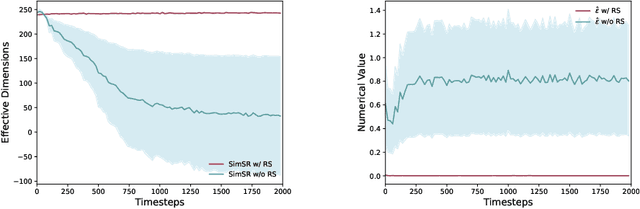
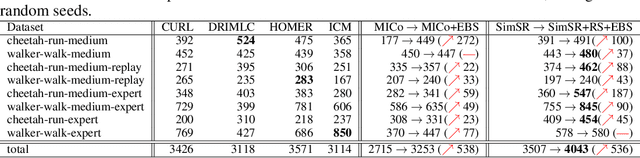
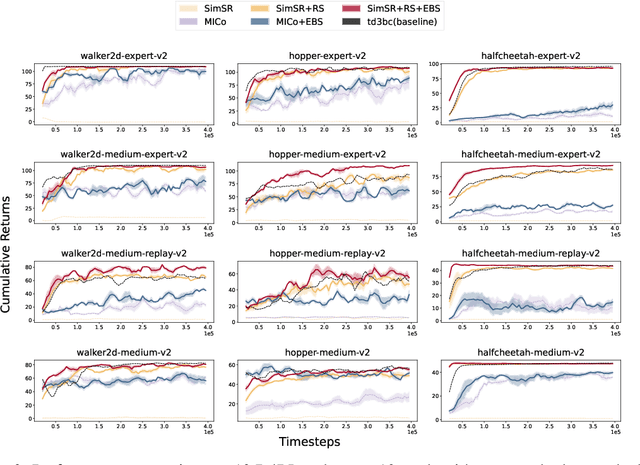
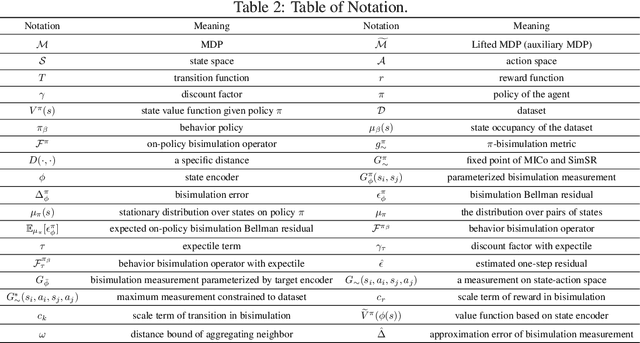
While bisimulation-based approaches hold promise for learning robust state representations for Reinforcement Learning (RL) tasks, their efficacy in offline RL tasks has not been up to par. In some instances, their performance has even significantly underperformed alternative methods. We aim to understand why bisimulation methods succeed in online settings, but falter in offline tasks. Our analysis reveals that missing transitions in the dataset are particularly harmful to the bisimulation principle, leading to ineffective estimation. We also shed light on the critical role of reward scaling in bounding the scale of bisimulation measurements and of the value error they induce. Based on these findings, we propose to apply the expectile operator for representation learning to our offline RL setting, which helps to prevent overfitting to incomplete data. Meanwhile, by introducing an appropriate reward scaling strategy, we avoid the risk of feature collapse in representation space. We implement these recommendations on two state-of-the-art bisimulation-based algorithms, MICo and SimSR, and demonstrate performance gains on two benchmark suites: D4RL and Visual D4RL. Codes are provided at \url{https://github.com/zanghyu/Offline_Bisimulation}.