 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of assembly tasks combining multiple primitive actions using Transformers and xLSTMs
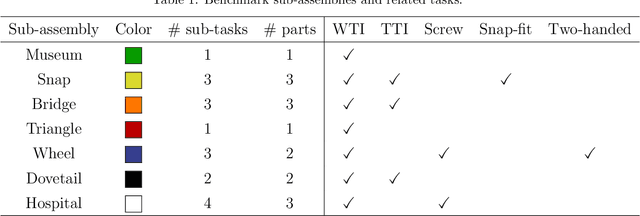
May 23, 2025The classification of human-performed assembly tasks is essential in collaborative robotics to ensure safety, anticipate robot actions, and facilitate robot learning. However, achieving reliable classification is challenging when segmenting tasks into smaller primitive actions is unfeasible, requiring us to classify long assembly tasks that encompass multiple primitive actions. In this study, we propose classifying long assembly sequential tasks based on hand landmark coordinates and compare the performance of two well-established classifiers, LSTM and Transformer, as well as a recent model, xLSTM. We used the HRC scenario proposed in the CT benchmark, which includes long assembly tasks that combine actions such as insertions, screw fastenings, and snap fittings. Testing was conducted using sequences gathered from both the human operator who performed the training sequences and three new operators. The testing results of real-padded sequences for the LSTM, Transformer, and xLSTM models was 72.9%, 95.0% and 93.2% for the training operator, and 43.5%, 54.3% and 60.8% for the new operators, respectively. The LSTM model clearly underperformed compared to the other two approaches. As expected, both the Transformer and xLSTM achieved satisfactory results for the operator they were trained on, though the xLSTM model demonstrated better generalization capabilities to new operators. The results clearly show that for this type of classification, the xLSTM model offers a slight edge over Transformers.
A Collaborative Robot-Assisted Manufacturing Assembly Process
Mar 08, 2024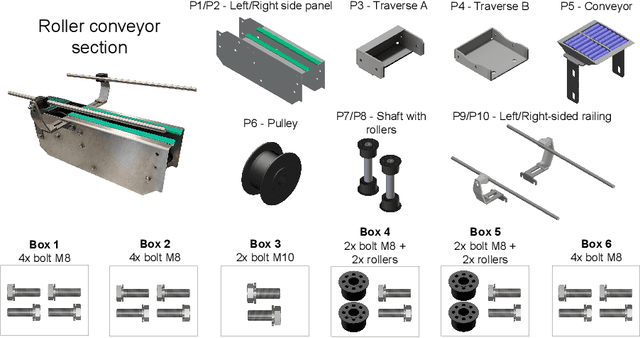
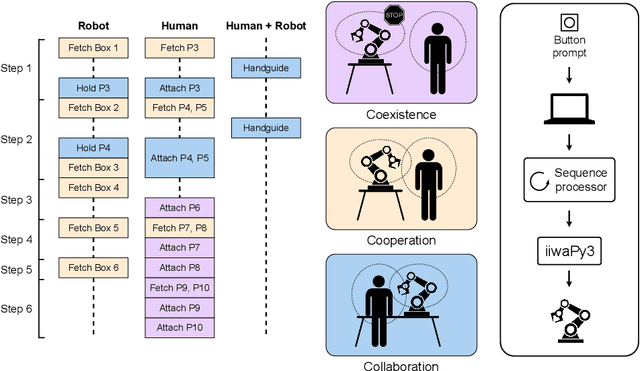
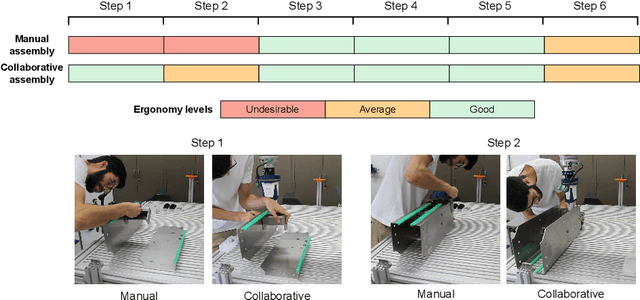
An effective human-robot collaborative process results in the reduction of the operator's workload, promoting a more efficient, productive, safer and less error-prone working environment. However, the implementation of collaborative robots in industry is still challenging. In this work, we compare manual and robot-assisted assembly processes to evaluate the effectiveness of collaborative robots while featuring different modes of operation (coexistence, cooperation and collaboration). Results indicate an improvement in ergonomic conditions and ease of execution without substantially compromising assembly time. Furthermore, the robot is intuitive to use and guides the user on the proper sequencing of the process.
Benchmarking human-robot collaborative assembly tasks
Feb 01, 2024
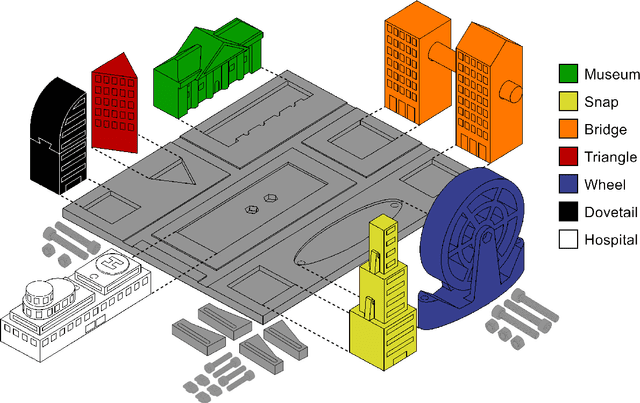
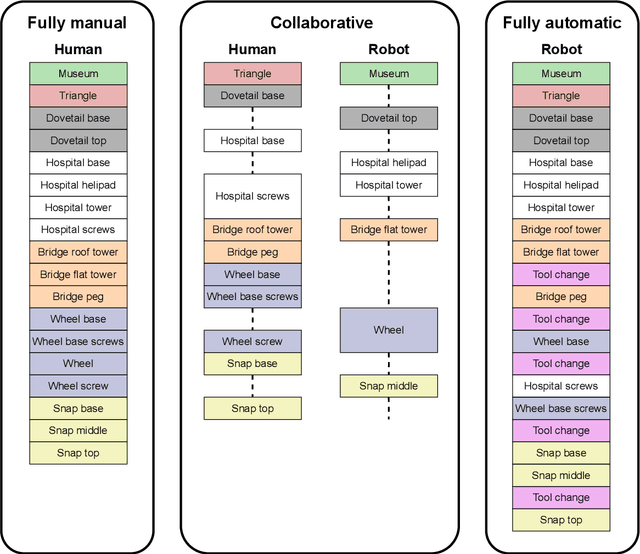
Manufacturing assembly tasks can vary in complexity and level of automation. Yet, achieving full automation can be challenging and inefficient, particularly due to the complexity of certain assembly operations. Human-robot collaborative work, leveraging the strengths of human labor alongside the capabilities of robots, can be a solution for enhancing efficiency. This paper introduces the CT benchmark, a benchmark and model set designed to facilitate the testing and evaluation of human-robot collaborative assembly scenarios. It was designed to compare manual and automatic processes using metrics such as the assembly time and human workload. The components of the model set can be assembled through the most common assembly tasks, each with varying levels of difficulty. The CT benchmark was designed with a focus on its applicability in human-robot collaborative environments, with the aim of ensuring the reproducibility and replicability of experiments. Experiments were carried out to assess assembly performance in three different setups (manual, automatic and collaborative), measuring metrics related to the assembly time and the workload on human operators. The results suggest that the collaborative approach takes longer than the fully manual assembly, with an increase of 70.8%. However, users reported a lower overall workload, as well as reduced mental demand, physical demand, and effort according to the NASA-TLX questionnaire.
A study on a Q-Learning algorithm application to a manufacturing assembly problem
Apr 17, 2023



The development of machine learning algorithms has been gathering relevance to address the increasing modelling complexity of manufacturing decision-making problems. Reinforcement learning is a methodology with great potential due to the reduced need for previous training data, i.e., the system learns along time with actual operation. This study focuses on the implementation of a reinforcement learning algorithm in an assembly problem of a given object, aiming to identify the effectiveness of the proposed approach in the optimisation of the assembly process time. A model-free Q-Learning algorithm is applied, considering the learning of a matrix of Q-values (Q-table) from the successive interactions with the environment to suggest an assembly sequence solution. This implementation explores three scenarios with increasing complexity so that the impact of the Q-Learning\textsc's parameters and rewards is assessed to improve the reinforcement learning agent performance. The optimisation approach achieved very promising results by learning the optimal assembly sequence 98.3% of the times.
Deep reinforcement learning applied to an assembly sequence planning problem with user preferences
Apr 13, 2023Deep reinforcement learning (DRL) has demonstrated its potential in solving complex manufacturing decision-making problems, especially in a context where the system learns over time with actual operation in the absence of training data. One interesting and challenging application for such methods is the assembly sequence planning (ASP) problem. In this paper, we propose an approach to the implementation of DRL methods in ASP. The proposed approach introduces in the RL environment parametric actions to improve training time and sample efficiency and uses two different reward signals: (1) user's preferences and (2) total assembly time duration. The user's preferences signal addresses the difficulties and non-ergonomic properties of the assembly faced by the human and the total assembly time signal enforces the optimization of the assembly. Three of the most powerful deep RL methods were studied, Advantage Actor-Critic (A2C), Deep Q-Learning (DQN), and Rainbow, in two different scenarios: a stochastic and a deterministic one. Finally, the performance of the DRL algorithms was compared to tabular Q-Learnings performance. After 10,000 episodes, the system achieved near optimal behaviour for the algorithms tabular Q-Learning, A2C, and Rainbow. Though, for more complex scenarios, the algorithm tabular Q-Learning is expected to underperform in comparison to the other 2 algorithms. The results support the potential for the application of deep reinforcement learning in assembly sequence planning problems with human interaction.
DistMS: A Non-Portfolio Distributed Solver for Maximum Satisfiability
May 10, 2015
The most successful parallel SAT and MaxSAT solvers follow a portfolio approach, where each thread applies a different algorithm (or the same algorithm configured differently) to solve a given problem instance. The main goal of building a portfolio is to diversify the search process being carried out by each thread. As soon as one thread finishes, the instance can be deemed solved. In this paper we present a new open source distributed solver for MaxSAT solving that addresses two issues commonly found in multicore parallel solvers, namely memory contention and scalability. Preliminary results show that our non-portfolio distributed MaxSAT solver outperforms its sequential version and is able to solve more instances as the number of processes increases.
Exploiting Resolution-based Representations for MaxSAT Solving
May 10, 2015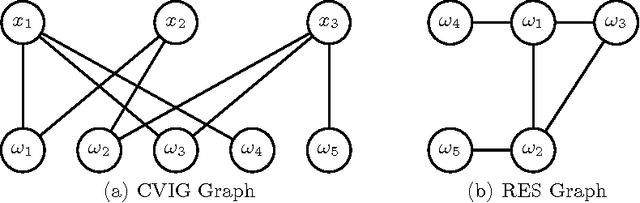
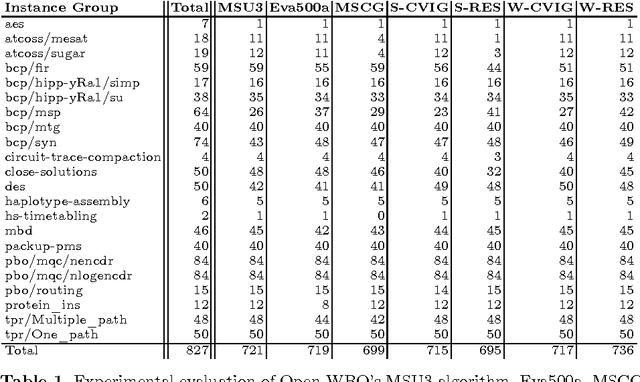
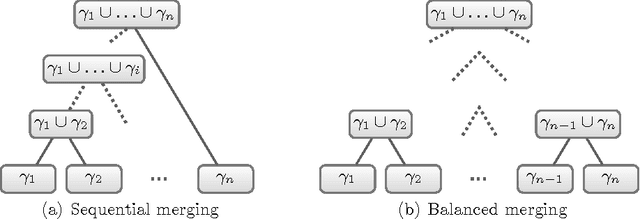
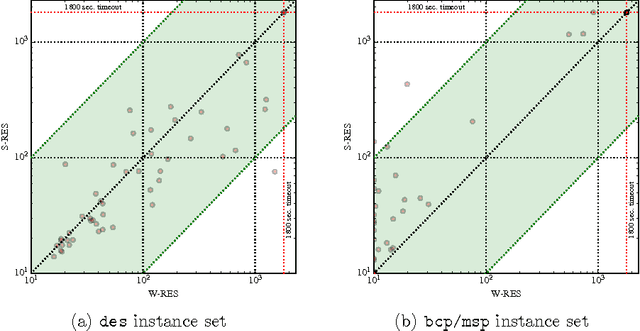
Most recent MaxSAT algorithms rely on a succession of calls to a SAT solver in order to find an optimal solution. In particular, several algorithms take advantage of the ability of SAT solvers to identify unsatisfiable subformulas. Usually, these MaxSAT algorithms perform better when small unsatisfiable subformulas are found early. However, this is not the case in many problem instances, since the whole formula is given to the SAT solver in each call. In this paper, we propose to partition the MaxSAT formula using a resolution-based graph representation. Partitions are then iteratively joined by using a proximity measure extracted from the graph representation of the formula. The algorithm ends when only one partition remains and the optimal solution is found. Experimental results show that this new approach further enhances a state of the art MaxSAT solver to optimally solve a larger set of industrial problem instances.