 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAU-Net: An Attention U-Net Extension with Feature Pyramid Attention for Prostate Cancer Segmentation
Sep 04, 2023

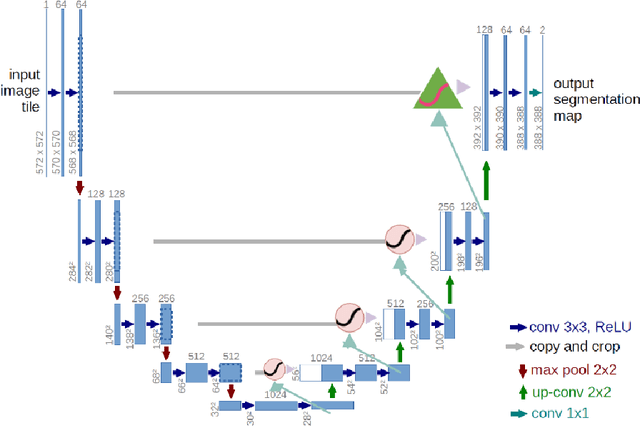

This contribution presents a deep learning method for the segmentation of prostate zones in MRI images based on U-Net using additive and feature pyramid attention modules, which can improve the workflow of prostate cancer detection and diagnosis. The proposed model is compared to seven different U-Net-based architectures. The automatic segmentation performance of each model of the central zone (CZ), peripheral zone (PZ), transition zone (TZ) and Tumor were evaluated using Dice Score (DSC), and the Intersection over Union (IoU) metrics. The proposed alternative achieved a mean DSC of 84.15% and IoU of 76.9% in the test set, outperforming most of the studied models in this work except from R2U-Net and attention R2U-Net architectures.
Assessing the performance of deep learning-based models for prostate cancer segmentation using uncertainty scores
Aug 09, 2023



This study focuses on comparing deep learning methods for the segmentation and quantification of uncertainty in prostate segmentation from MRI images. The aim is to improve the workflow of prostate cancer detection and diagnosis. Seven different U-Net-based architectures, augmented with Monte-Carlo dropout, are evaluated for automatic segmentation of the central zone, peripheral zone, transition zone, and tumor, with uncertainty estimation. The top-performing model in this study is the Attention R2U-Net, achieving a mean Intersection over Union (IoU) of 76.3% and Dice Similarity Coefficient (DSC) of 85% for segmenting all zones. Additionally, Attention R2U-Net exhibits the lowest uncertainty values, particularly in the boundaries of the transition zone and tumor, when compared to the other models.
Isolated Sign Language Recognition based on Tree Structure Skeleton Images
Apr 10, 2023



Sign Language Recognition (SLR) systems aim to be embedded in video stream platforms to recognize the sign performed in front of a camera. SLR research has taken advantage of recent advances in pose estimation models to use skeleton sequences estimated from videos instead of RGB information to predict signs. This approach can make HAR-related tasks less complex and more robust to diverse backgrounds, lightning conditions, and physical appearances. In this work, we explore the use of a spatio-temporal skeleton representation such as Tree Structure Skeleton Image (TSSI) as an alternative input to improve the accuracy of skeleton-based models for SLR. TSSI converts a skeleton sequence into an RGB image where the columns represent the joints of the skeleton in a depth-first tree traversal order, the rows represent the temporal evolution of the joints, and the three channels represent the (x, y, z) coordinates of the joints. We trained a DenseNet-121 using this type of input and compared it with other skeleton-based deep learning methods using a large-scale American Sign Language (ASL) dataset, WLASL. Our model (SL-TSSI-DenseNet) overcomes the state-of-the-art of other skeleton-based models. Moreover, when including data augmentation our proposal achieves better results than both skeleton-based and RGB-based models. We evaluated the effectiveness of our model on the Ankara University Turkish Sign Language (TSL) dataset, AUTSL, and a Mexican Sign Language (LSM) dataset. On the AUTSL dataset, the model achieves similar results to the state-of-the-art of other skeleton-based models. On the LSM dataset, the model achieves higher results than the baseline. Code has been made available at: https://github.com/davidlainesv/SL-TSSI-DenseNet.
Deep Prototypical-Parts Ease Morphological Kidney Stone Identification and are Competitively Robust to Photometric Perturbations
Apr 08, 2023Identifying the type of kidney stones can allow urologists to determine their cause of formation, improving the prescription of appropriate treatments to diminish future relapses. Currently, the associated ex-vivo diagnosis (known as Morpho-constitutional Analysis, MCA) is time-consuming, expensive and requires a great deal of experience, as it requires a visual analysis component that is highly operator dependant. Recently, machine learning methods have been developed for in-vivo endoscopic stone recognition. Deep Learning (DL) based methods outperform non-DL methods in terms of accuracy but lack explainability. Despite this trade-off, when it comes to making high-stakes decisions, it's important to prioritize understandable Computer-Aided Diagnosis (CADx) that suggests a course of action based on reasonable evidence, rather than a model prescribing a course of action. In this proposal, we learn Prototypical Parts (PPs) per kidney stone subtype, which are used by the DL model to generate an output classification. Using PPs in the classification task enables case-based reasoning explanations for such output, thus making the model interpretable. In addition, we modify global visual characteristics to describe their relevance to the PPs and the sensitivity of our model's performance. With this, we provide explanations with additional information at the sample, class and model levels in contrast to previous works. Although our implementation's average accuracy is lower than state-of-the-art (SOTA) non-interpretable DL models by 1.5 %, our models perform 2.8% better on perturbed images with a lower standard deviation, without adversarial training. Thus, Learning PPs has the potential to create more robust DL models.
Improved Kidney Stone Recognition Through Attention and Multi-View Feature Fusion Strategies
Nov 05, 2022This contribution presents a deep learning method for the extraction and fusion of information relating to kidney stone fragments acquired from different viewpoints of the endoscope. Surface and section fragment images are jointly used during the training of the classifier to improve the discrimination power of the features by adding attention layers at the end of each convolutional block. This approach is specifically designed to mimic the morpho-constitutional analysis performed in ex-vivo by biologists to visually identify kidney stones by inspecting both views. The addition of attention mechanisms to the backbone improved the results of single view extraction backbones by 4% on average. Moreover, in comparison to the state-of-the-art, the fusion of the deep features improved the overall results up to 11% in terms of kidney stone classification accuracy.
Comparison of automatic prostate zones segmentation models in MRI images using U-net-like architectures
Jul 19, 2022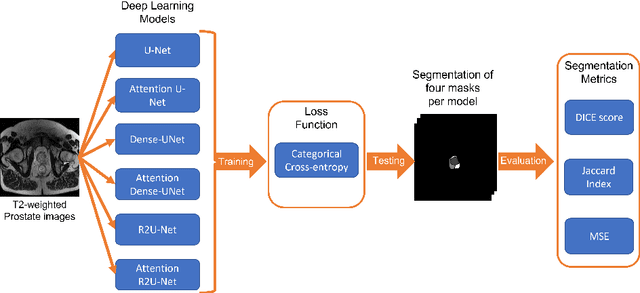
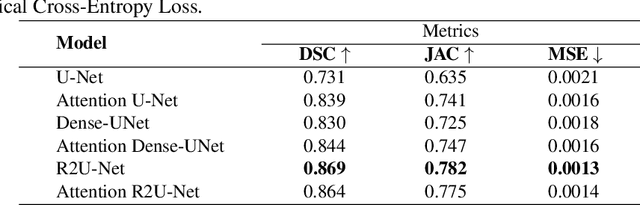
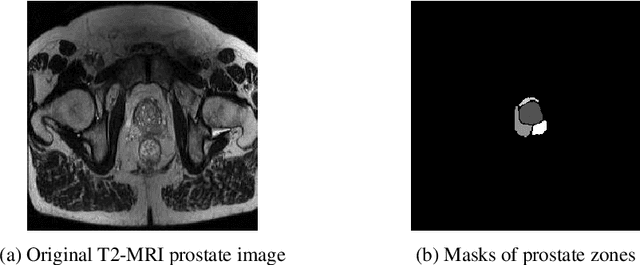
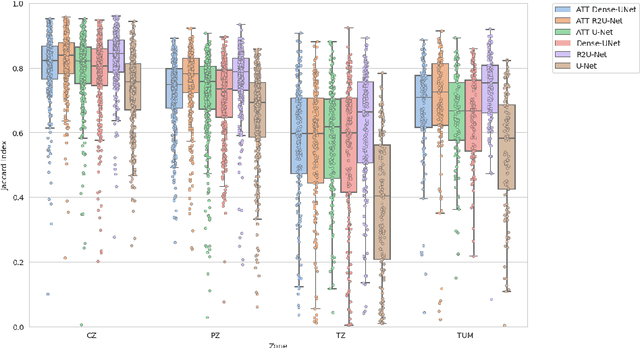
Prostate cancer is the second-most frequently diagnosed cancer and the sixth leading cause of cancer death in males worldwide. The main problem that specialists face during the diagnosis of prostate cancer is the localization of Regions of Interest (ROI) containing a tumor tissue. Currently, the segmentation of this ROI in most cases is carried out manually by expert doctors, but the procedure is plagued with low detection rates (of about 27-44%) or overdiagnosis in some patients. Therefore, several research works have tackled the challenge of automatically segmenting and extracting features of the ROI from magnetic resonance images, as this process can greatly facilitate many diagnostic and therapeutic applications. However, the lack of clear prostate boundaries, the heterogeneity inherent to the prostate tissue, and the variety of prostate shapes makes this process very difficult to automate.In this work, six deep learning models were trained and analyzed with a dataset of MRI images obtained from the Centre Hospitalaire de Dijon and Universitat Politecnica de Catalunya. We carried out a comparison of multiple deep learning models (i.e. U-Net, Attention U-Net, Dense-UNet, Attention Dense-UNet, R2U-Net, and Attention R2U-Net) using categorical cross-entropy loss function. The analysis was performed using three metrics commonly used for image segmentation: Dice score, Jaccard index, and mean squared error. The model that give us the best result segmenting all the zones was R2U-Net, which achieved 0.869, 0.782, and 0.00013 for Dice, Jaccard and mean squared error, respectively.
Computer Vision-based Characterization of Large-scale Jet Flames using a Synthetic Infrared Image Generation Approach
Jun 05, 2022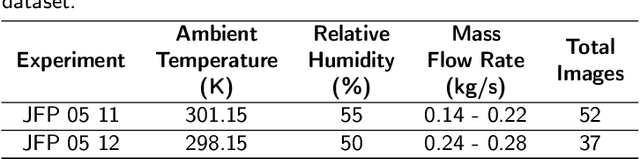


Among the different kinds of fire accidents that can occur during industrial activities that involve hazardous materials, jet fires are one of the lesser-known types. This is because they are often involved in a process that generates a sequence of other accidents of greater magnitude, known as domino effect. Flame impingement usually causes domino effects, and jet fires present specific features that can significantly increase the probability of this happening. These features become relevant from a risk analysis perspective, making their proper characterization a crucial task. Deep Learning approaches have become extensively used for tasks such as jet fire characterization; however, these methods are heavily dependent on the amount of data and the quality of the labels. Data acquisition of jet fires involve expensive experiments, especially so if infrared imagery is used. Therefore, this paper proposes the use of Generative Adversarial Networks to produce plausible infrared images from visible ones, making experiments less expensive and allowing for other potential applications. The results suggest that it is possible to realistically replicate the results for experiments carried out using both visible and infrared cameras. The obtained results are compared with some previous experiments, and it is shown that similar results were obtained.
Impact of loss function in Deep Learning methods for accurate retinal vessel segmentation
Jun 01, 2022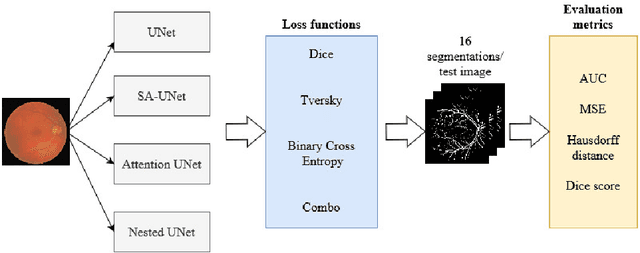


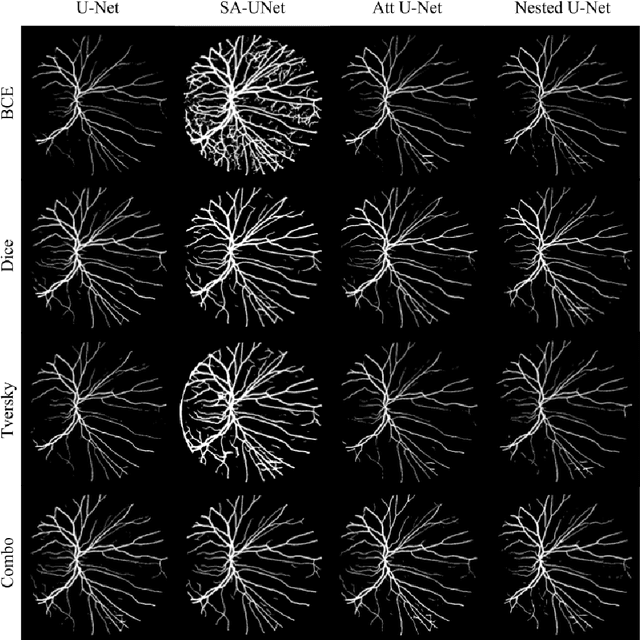
The retinal vessel network studied through fundus images contributes to the diagnosis of multiple diseases not only found in the eye. The segmentation of this system may help the specialized task of analyzing these images by assisting in the quantification of morphological characteristics. Due to its relevance, several Deep Learning-based architectures have been tested for tackling this problem automatically. However, the impact of loss function selection on the segmentation of the intricate retinal blood vessel system hasn't been systematically evaluated. In this work, we present the comparison of the loss functions Binary Cross Entropy, Dice, Tversky, and Combo loss using the deep learning architectures (i.e. U-Net, Attention U-Net, and Nested UNet) with the DRIVE dataset. Their performance is assessed using four metrics: the AUC, the mean squared error, the dice score, and the Hausdorff distance. The models were trained with the same number of parameters and epochs. Using dice score and AUC, the best combination was SA-UNet with Combo loss, which had an average of 0.9442 and 0.809 respectively. The best average of Hausdorff distance and mean square error were obtained using the Nested U-Net with the Dice loss function, which had an average of 6.32 and 0.0241 respectively. The results showed that there is a significant difference in the selection of loss function
On the in vivo recognition of kidney stones using machine learning
Jan 21, 2022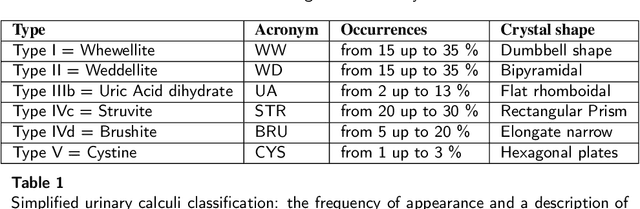
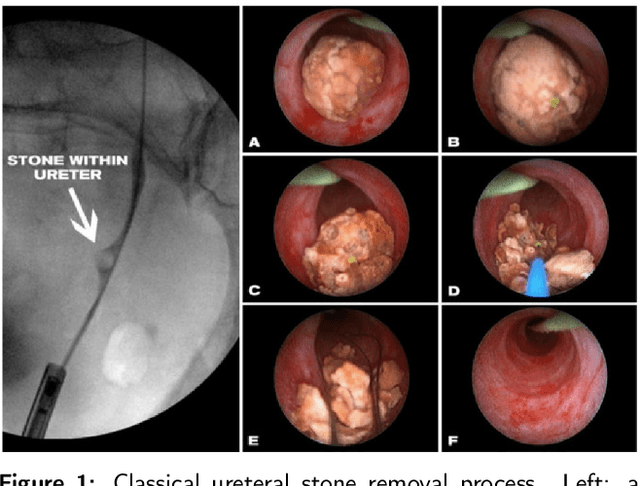
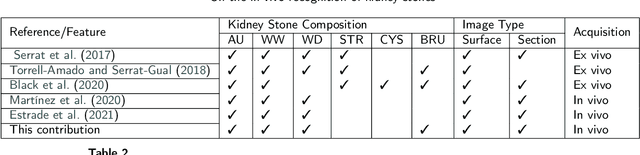
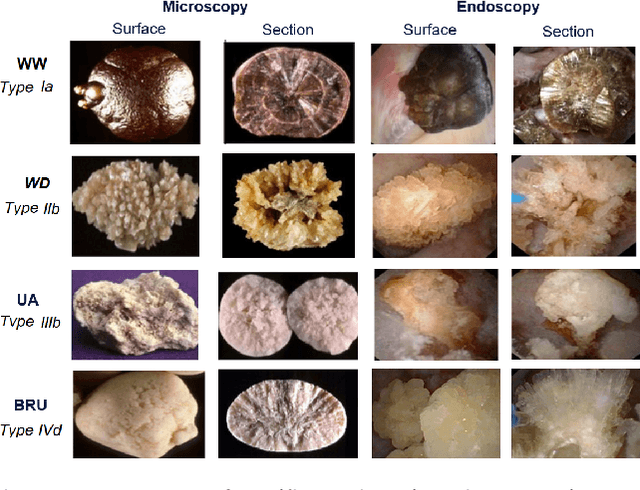
Determining the type of kidney stones allows urologists to prescribe a treatment to avoid recurrence of renal lithiasis. An automated in-vivo image-based classification method would be an important step towards an immediate identification of the kidney stone type required as a first phase of the diagnosis. In the literature it was shown on ex-vivo data (i.e., in very controlled scene and image acquisition conditions) that an automated kidney stone classification is indeed feasible. This pilot study compares the kidney stone recognition performances of six shallow machine learning methods and three deep-learning architectures which were tested with in-vivo images of the four most frequent urinary calculi types acquired with an endoscope during standard ureteroscopies. This contribution details the database construction and the design of the tested kidney stones classifiers. Even if the best results were obtained by the Inception v3 architecture (weighted precision, recall and F1-score of 0.97, 0.98 and 0.97, respectively), it is also shown that choosing an appropriate colour space and texture features allows a shallow machine learning method to approach closely the performances of the most promising deep-learning methods (the XGBoost classifier led to weighted precision, recall and F1-score values of 0.96). This paper is the first one that explores the most discriminant features to be extracted from images acquired during ureteroscopies.
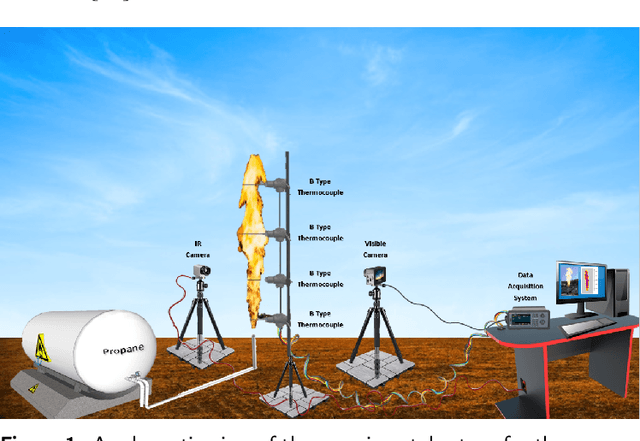
Experimental Large-Scale Jet Flames' Geometrical Features Extraction for Risk Management Using Infrared Images and Deep Learning Segmentation Methods
Jan 20, 2022



Jet fires are relatively small and have the least severe effects among the diverse fire accidents that can occur in industrial plants; however, they are usually involved in a process known as the domino effect, that leads to more severe events, such as explosions or the initiation of another fire, making the analysis of such fires an important part of risk analysis. This research work explores the application of deep learning models in an alternative approach that uses the semantic segmentation of jet fires flames to extract main geometrical attributes, relevant for fire risk assessments. A comparison is made between traditional image processing methods and some state-of-the-art deep learning models. It is found that the best approach is a deep learning architecture known as UNet, along with its two improvements, Attention UNet and UNet++. The models are then used to segment a group of vertical jet flames of varying pipe outlet diameters to extract their main geometrical characteristics. Attention UNet obtained the best general performance in the approximation of both height and area of the flames, while also showing a statistically significant difference between it and UNet++. UNet obtained the best overall performance for the approximation of the lift-off distances; however, there is not enough data to prove a statistically significant difference between Attention UNet and UNet++. The only instance where UNet++ outperformed the other models, was while obtaining the lift-off distances of the jet flames with 0.01275 m pipe outlet diameter. In general, the explored models show good agreement between the experimental and predicted values for relatively large turbulent propane jet flames, released in sonic and subsonic regimes; thus, making these radiation zones segmentation models, a suitable approach for different jet flame risk management scenarios.