 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNPEFF: Non-Negative Per-Example Fisher Factorization
Oct 07, 2023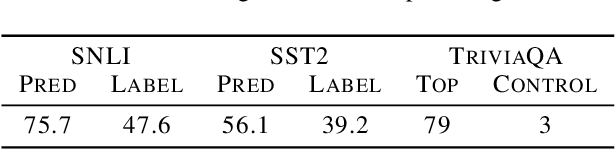

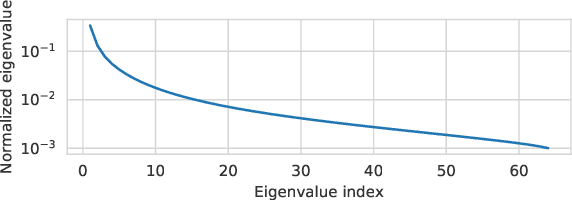
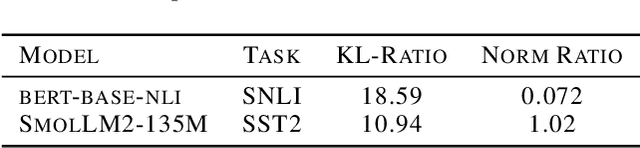
As deep learning models are deployed in more and more settings, it becomes increasingly important to be able to understand why they produce a given prediction, but interpretation of these models remains a challenge. In this paper, we introduce a novel interpretability method called NPEFF that is readily applicable to any end-to-end differentiable model. It operates on the principle that processing of a characteristic shared across different examples involves a specific subset of model parameters. We perform NPEFF by decomposing each example's Fisher information matrix as a non-negative sum of components. These components take the form of either non-negative vectors or rank-1 positive semi-definite matrices depending on whether we are using diagonal or low-rank Fisher representations, respectively. For the latter form, we introduce a novel and highly scalable algorithm. We demonstrate that components recovered by NPEFF have interpretable tunings through experiments on language and vision models. Using unique properties of NPEFF's parameter-space representations, we ran extensive experiments to verify that the connections between directions in parameters space and examples recovered by NPEFF actually reflect the model's processing. We further demonstrate NPEFF's ability to uncover the actual processing strategies used by a TRACR-compiled model. We further explore a potential application of NPEFF in uncovering and correcting flawed heuristics used by a model. We release our code to facilitate research using NPEFF.
A Combinatorial Perspective on the Optimization of Shallow ReLU Networks
Oct 01, 2022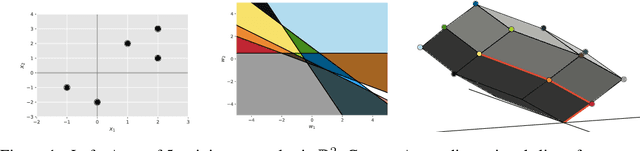

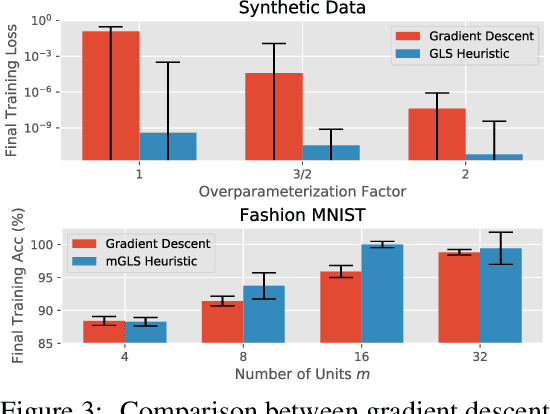
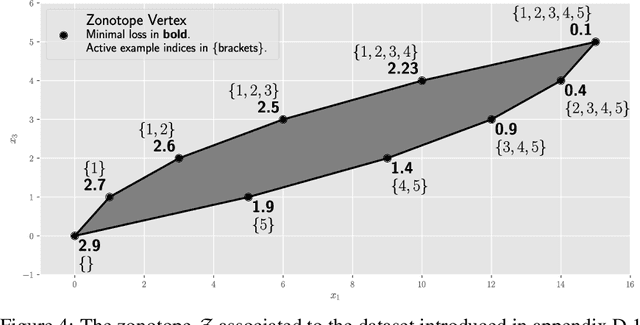
The NP-hard problem of optimizing a shallow ReLU network can be characterized as a combinatorial search over each training example's activation pattern followed by a constrained convex problem given a fixed set of activation patterns. We explore the implications of this combinatorial aspect of ReLU optimization in this work. We show that it can be naturally modeled via a geometric and combinatoric object known as a zonotope with its vertex set isomorphic to the set of feasible activation patterns. This assists in analysis and provides a foundation for further research. We demonstrate its usefulness when we explore the sensitivity of the optimal loss to perturbations of the training data. Later we discuss methods of zonotope vertex selection and its relevance to optimization. Overparameterization assists in training by making a randomly chosen vertex more likely to contain a good solution. We then introduce a novel polynomial-time vertex selection procedure that provably picks a vertex containing the global optimum using only double the minimum number of parameters required to fit the data. We further introduce a local greedy search heuristic over zonotope vertices and demonstrate that it outperforms gradient descent on underparameterized problems.
Merging Models with Fisher-Weighted Averaging
Nov 18, 2021

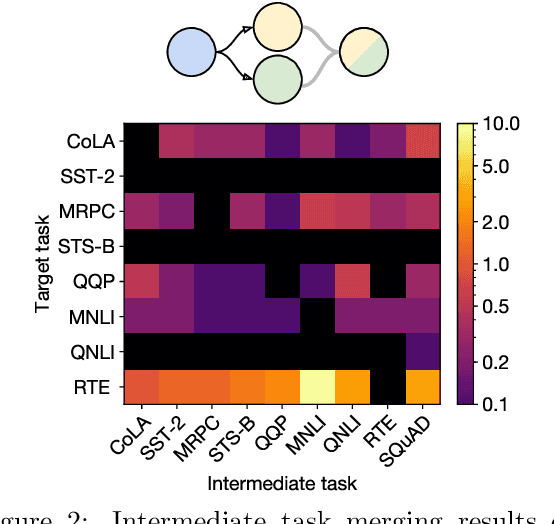
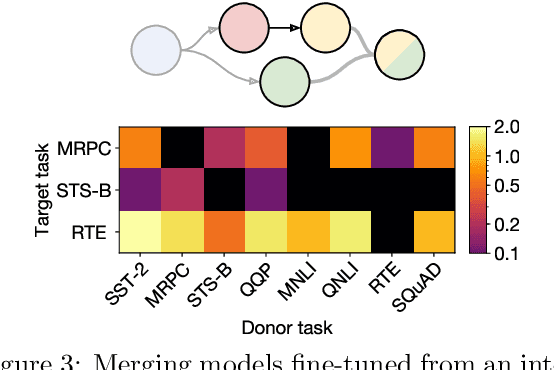
Transfer learning provides a way of leveraging knowledge from one task when learning another task. Performing transfer learning typically involves iteratively updating a model's parameters through gradient descent on a training dataset. In this paper, we introduce a fundamentally different method for transferring knowledge across models that amounts to "merging" multiple models into one. Our approach effectively involves computing a weighted average of the models' parameters. We show that this averaging is equivalent to approximately sampling from the posteriors of the model weights. While using an isotropic Gaussian approximation works well in some cases, we also demonstrate benefits by approximating the precision matrix via the Fisher information. In sum, our approach makes it possible to combine the "knowledge" in multiple models at an extremely low computational cost compared to standard gradient-based training. We demonstrate that model merging achieves comparable performance to gradient descent-based transfer learning on intermediate-task training and domain adaptation problems. We also show that our merging procedure makes it possible to combine models in previously unexplored ways. To measure the robustness of our approach, we perform an extensive ablation on the design of our algorithm.
Do Transformer Modifications Transfer Across Implementations and Applications?
Feb 23, 2021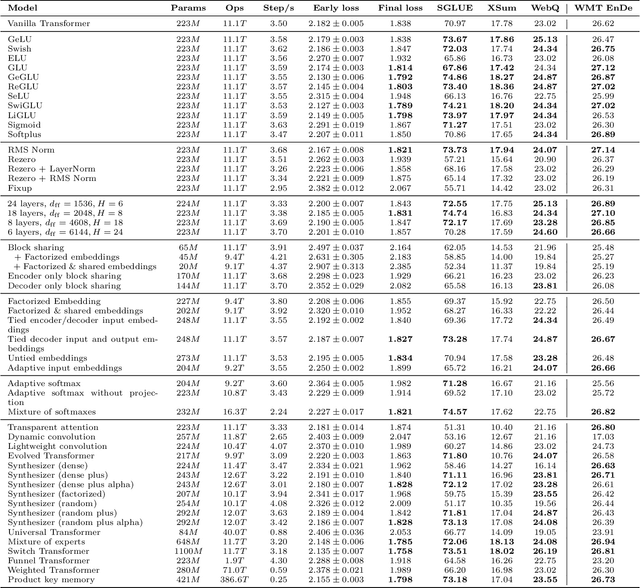
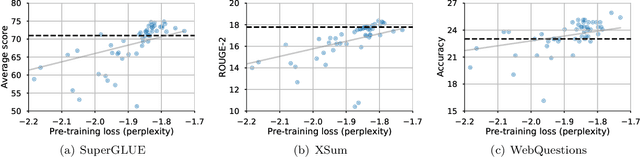
The research community has proposed copious modifications to the Transformer architecture since it was introduced over three years ago, relatively few of which have seen widespread adoption. In this paper, we comprehensively evaluate many of these modifications in a shared experimental setting that covers most of the common uses of the Transformer in natural language processing. Surprisingly, we find that most modifications do not meaningfully improve performance. Furthermore, most of the Transformer variants we found beneficial were either developed in the same codebase that we used or are relatively minor changes. We conjecture that performance improvements may strongly depend on implementation details and correspondingly make some recommendations for improving the generality of experimental results.
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Oct 24, 2019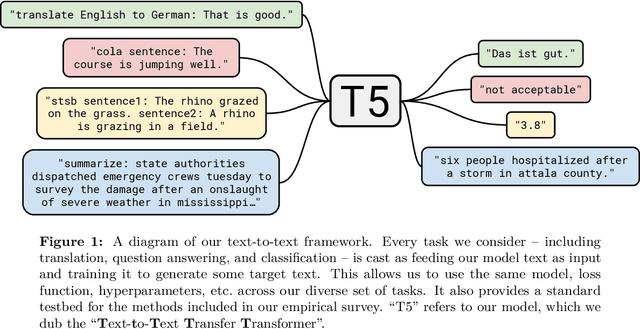
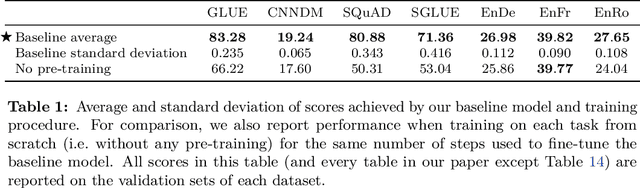

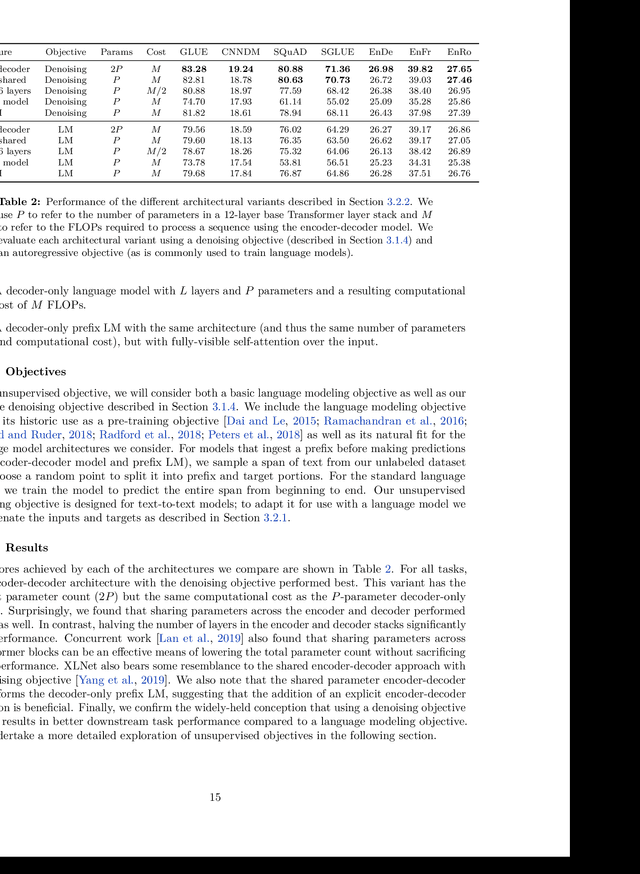
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.