 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNPEFF: Non-Negative Per-Example Fisher Factorization
Paper and Code
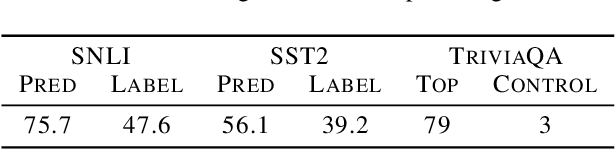

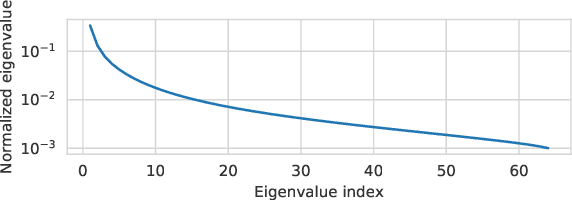
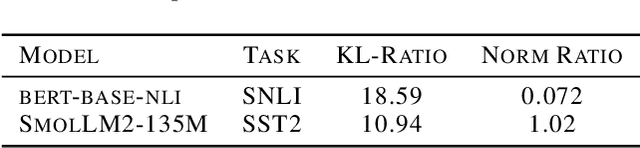
As deep learning models are deployed in more and more settings, it becomes increasingly important to be able to understand why they produce a given prediction, but interpretation of these models remains a challenge. In this paper, we introduce a novel interpretability method called NPEFF that is readily applicable to any end-to-end differentiable model. It operates on the principle that processing of a characteristic shared across different examples involves a specific subset of model parameters. We perform NPEFF by decomposing each example's Fisher information matrix as a non-negative sum of components. These components take the form of either non-negative vectors or rank-1 positive semi-definite matrices depending on whether we are using diagonal or low-rank Fisher representations, respectively. For the latter form, we introduce a novel and highly scalable algorithm. We demonstrate that components recovered by NPEFF have interpretable tunings through experiments on language and vision models. Using unique properties of NPEFF's parameter-space representations, we ran extensive experiments to verify that the connections between directions in parameters space and examples recovered by NPEFF actually reflect the model's processing. We further demonstrate NPEFF's ability to uncover the actual processing strategies used by a TRACR-compiled model. We further explore a potential application of NPEFF in uncovering and correcting flawed heuristics used by a model. We release our code to facilitate research using NPEFF.