 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Runtime-Adaptive Transformer Neural Network Accelerator on FPGAs
Nov 27, 2024



Transformer neural networks (TNN) excel in natural language processing (NLP), machine translation, and computer vision (CV) without relying on recurrent or convolutional layers. However, they have high computational and memory demands, particularly on resource-constrained devices like FPGAs. Moreover, transformer models vary in processing time across applications, requiring custom models with specific parameters. Designing custom accelerators for each model is complex and time-intensive. Some custom accelerators exist with no runtime adaptability, and they often rely on sparse matrices to reduce latency. However, hardware designs become more challenging due to the need for application-specific sparsity patterns. This paper introduces ADAPTOR, a runtime-adaptive accelerator for dense matrix computations in transformer encoders and decoders on FPGAs. ADAPTOR enhances the utilization of processing elements and on-chip memory, enhancing parallelism and reducing latency. It incorporates efficient matrix tiling to distribute resources across FPGA platforms and is fully quantized for computational efficiency and portability. Evaluations on Xilinx Alveo U55C data center cards and embedded platforms like VC707 and ZCU102 show that our design is 1.2$\times$ and 2.87$\times$ more power efficient than the NVIDIA K80 GPU and the i7-8700K CPU respectively. Additionally, it achieves a speedup of 1.7 to 2.25$\times$ compared to some state-of-the-art FPGA-based accelerators.
FAMOUS: Flexible Accelerator for the Attention Mechanism of Transformer on UltraScale+ FPGAs
Sep 21, 2024



Transformer neural networks (TNNs) are being applied across a widening range of application domains, including natural language processing (NLP), machine translation, and computer vision (CV). Their popularity is largely attributed to the exceptional performance of their multi-head self-attention blocks when analyzing sequential data and extracting features. To date, there are limited hardware accelerators tailored for this mechanism, which is the first step before designing an accelerator for a complete model. This paper proposes \textit{FAMOUS}, a flexible hardware accelerator for dense multi-head attention (MHA) computation of TNNs on field-programmable gate arrays (FPGAs). It is optimized for high utilization of processing elements and on-chip memories to improve parallelism and reduce latency. An efficient tiling of large matrices has been employed to distribute memory and computing resources across different modules on various FPGA platforms. The design is evaluated on Xilinx Alveo U55C and U200 data center cards containing Ultrascale+ FPGAs. Experimental results are presented that show that it can attain a maximum throughput, number of parallel attention heads, embedding dimension and tile size of 328 (giga operations/second (GOPS)), 8, 768 and 64 respectively on the U55C. Furthermore, it is 3.28$\times$ and 2.6$\times$ faster than the Intel Xeon Gold 5220R CPU and NVIDIA V100 GPU respectively. It is also 1.3$\times$ faster than the fastest state-of-the-art FPGA-based accelerator.
ProTEA: Programmable Transformer Encoder Acceleration on FPGA
Sep 21, 2024



Transformer neural networks (TNN) have been widely utilized on a diverse range of applications, including natural language processing (NLP), machine translation, and computer vision (CV). Their widespread adoption has been primarily driven by the exceptional performance of their multi-head self-attention block used to extract key features from sequential data. The multi-head self-attention block is followed by feedforward neural networks, which play a crucial role in introducing non-linearity to assist the model in learning complex patterns. Despite the popularity of TNNs, there has been limited numbers of hardware accelerators targeting these two critical blocks. Most prior works have concentrated on sparse architectures that are not flexible for popular TNN variants. This paper introduces \textit{ProTEA}, a runtime programmable accelerator tailored for the dense computations of most of state-of-the-art transformer encoders. \textit{ProTEA} is designed to reduce latency by maximizing parallelism. We introduce an efficient tiling of large matrices that can distribute memory and computing resources across different hardware components within the FPGA. We provide run time evaluations of \textit{ProTEA} on a Xilinx Alveo U55C high-performance data center accelerator card. Experimental results demonstrate that \textit{ProTEA} can host a wide range of popular transformer networks and achieve near optimal performance with a tile size of 64 in the multi-head self-attention block and 6 in the feedforward networks block when configured with 8 parallel attention heads, 12 layers, and an embedding dimension of 768 on the U55C. Comparative results are provided showing \textit{ProTEA} is 2.5$\times$ faster than an NVIDIA Titan XP GPU. Results also show that it achieves 1.3 -- 2.8$\times$ speed up compared with current state-of-the-art custom designed FPGA accelerators.
Sequence Graph Network for Online Debate Analysis
Jun 26, 2024Online debates involve a dynamic exchange of ideas over time, where participants need to actively consider their opponents' arguments, respond with counterarguments, reinforce their own points, and introduce more compelling arguments as the discussion unfolds. Modeling such a complex process is not a simple task, as it necessitates the incorporation of both sequential characteristics and the capability to capture interactions effectively. To address this challenge, we employ a sequence-graph approach. Building the conversation as a graph allows us to effectively model interactions between participants through directed edges. Simultaneously, the propagation of information along these edges in a sequential manner enables us to capture a more comprehensive representation of context. We also introduce a Sequence Graph Attention layer to illustrate the proposed information update scheme. The experimental results show that sequence graph networks achieve superior results to existing methods in online debates.
Self-supervised Domain Adaptation in Crowd Counting
Jun 07, 2022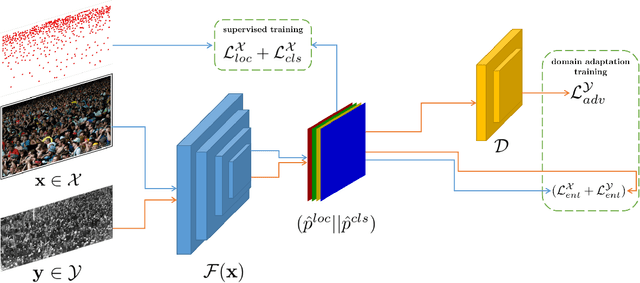
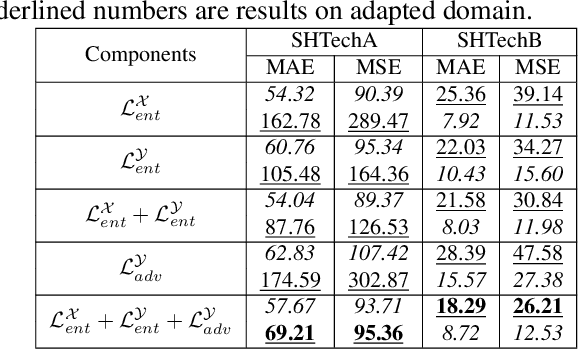
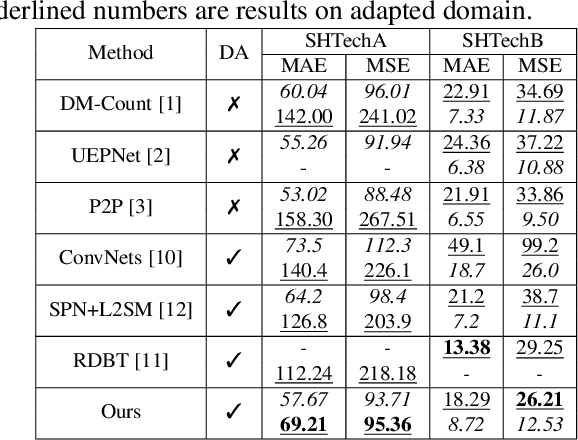

Self-training crowd counting has not been attentively explored though it is one of the important challenges in computer vision. In practice, the fully supervised methods usually require an intensive resource of manual annotation. In order to address this challenge, this work introduces a new approach to utilize existing datasets with ground truth to produce more robust predictions on unlabeled datasets, named domain adaptation, in crowd counting. While the network is trained with labeled data, samples without labels from the target domain are also added to the training process. In this process, the entropy map is computed and minimized in addition to the adversarial training process designed in parallel. Experiments on Shanghaitech, UCF_CC_50, and UCF-QNRF datasets prove a more generalized improvement of our method over the other state-of-the-arts in the cross-domain setting.