 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Domain Adaptation in Crowd Counting
Paper and Code
Jun 07, 2022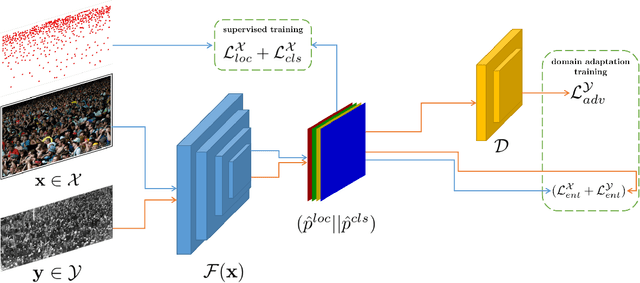
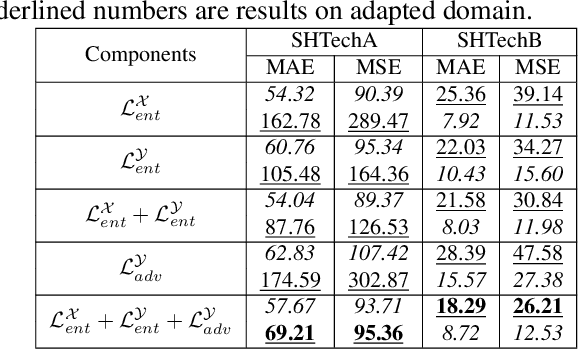
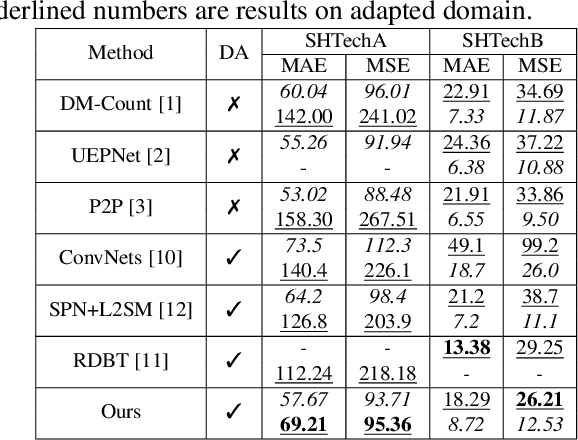

Self-training crowd counting has not been attentively explored though it is one of the important challenges in computer vision. In practice, the fully supervised methods usually require an intensive resource of manual annotation. In order to address this challenge, this work introduces a new approach to utilize existing datasets with ground truth to produce more robust predictions on unlabeled datasets, named domain adaptation, in crowd counting. While the network is trained with labeled data, samples without labels from the target domain are also added to the training process. In this process, the entropy map is computed and minimized in addition to the adversarial training process designed in parallel. Experiments on Shanghaitech, UCF_CC_50, and UCF-QNRF datasets prove a more generalized improvement of our method over the other state-of-the-arts in the cross-domain setting.