 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Sentence-Level Semantic Search using Meta-Distillation Learning
Sep 15, 2023



Multilingual semantic search is the task of retrieving relevant contents to a query expressed in different language combinations. This requires a better semantic understanding of the user's intent and its contextual meaning. Multilingual semantic search is less explored and more challenging than its monolingual or bilingual counterparts, due to the lack of multilingual parallel resources for this task and the need to circumvent "language bias". In this work, we propose an alignment approach: MAML-Align, specifically for low-resource scenarios. Our approach leverages meta-distillation learning based on MAML, an optimization-based Model-Agnostic Meta-Learner. MAML-Align distills knowledge from a Teacher meta-transfer model T-MAML, specialized in transferring from monolingual to bilingual semantic search, to a Student model S-MAML, which meta-transfers from bilingual to multilingual semantic search. To the best of our knowledge, we are the first to extend meta-distillation to a multilingual search application. Our empirical results show that on top of a strong baseline based on sentence transformers, our meta-distillation approach boosts the gains provided by MAML and significantly outperforms naive fine-tuning methods. Furthermore, multilingual meta-distillation learning improves generalization even to unseen languages.
Cross-lingual Lifelong Learning
May 23, 2022

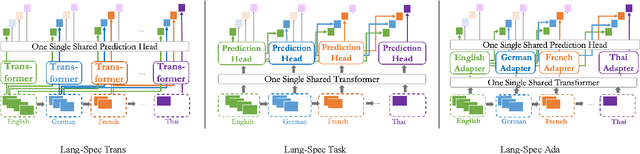

The longstanding goal of multi-lingual learning has been to develop a universal cross-lingual model that can withstand the changes in multi-lingual data distributions. However, most existing models assume full access to the target languages in advance, whereas in realistic scenarios this is not often the case, as new languages can be incorporated later on. In this paper, we present the Cross-lingual Lifelong Learning (CLL) challenge, where a model is continually fine-tuned to adapt to emerging data from different languages. We provide insights into what makes multilingual sequential learning particularly challenging. To surmount such challenges, we benchmark a representative set of cross-lingual continual learning algorithms and analyze their knowledge preservation, accumulation, and generalization capabilities compared to baselines on carefully curated datastreams. The implications of this analysis include a recipe for how to measure and balance between different cross-lingual continual learning desiderata, which goes beyond conventional transfer learning.
X-METRA-ADA: Cross-lingual Meta-Transfer Learning Adaptation to Natural Language Understanding and Question Answering
Apr 20, 2021
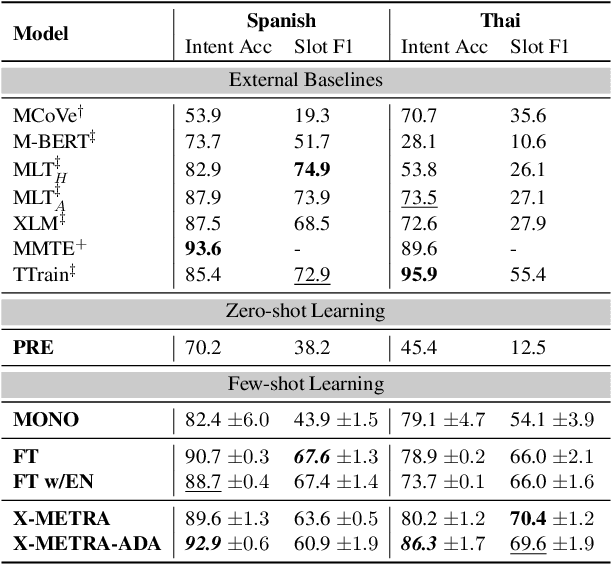

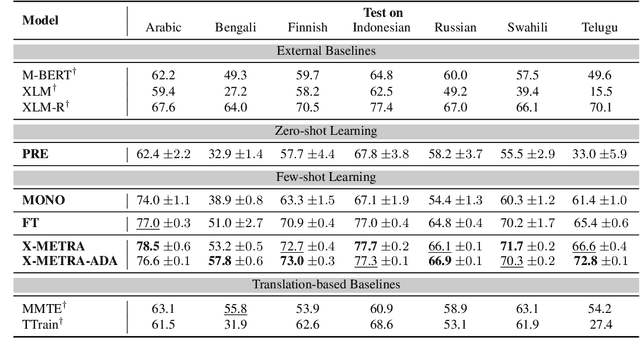
Multilingual models, such as M-BERT and XLM-R, have gained increasing popularity, due to their zero-shot cross-lingual transfer learning capabilities. However, their generalization ability is still inconsistent for typologically diverse languages and across different benchmarks. Recently, meta-learning has garnered attention as a promising technique for enhancing transfer learning under low-resource scenarios: particularly for cross-lingual transfer in Natural Language Understanding (NLU). In this work, we propose X-METRA-ADA, a cross-lingual MEta-TRAnsfer learning ADAptation approach for NLU. Our approach adapts MAML, an optimization-based meta-learning approach, to learn to adapt to new languages. We extensively evaluate our framework on two challenging cross-lingual NLU tasks: multilingual task-oriented dialog and typologically diverse question answering. We show that our approach outperforms naive fine-tuning, reaching competitive performance on both tasks for most languages. Our analysis reveals that X-METRA-ADA can leverage limited data for faster adaptation.
Expanding the Text Classification Toolbox with Cross-Lingual Embeddings
Mar 26, 2019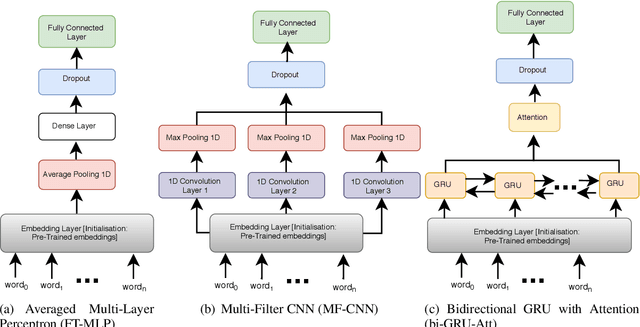

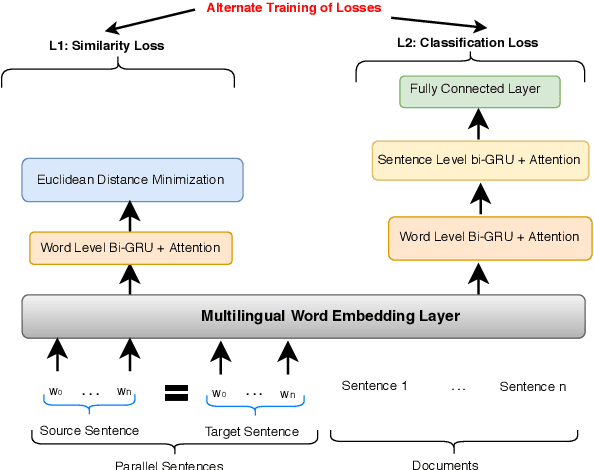
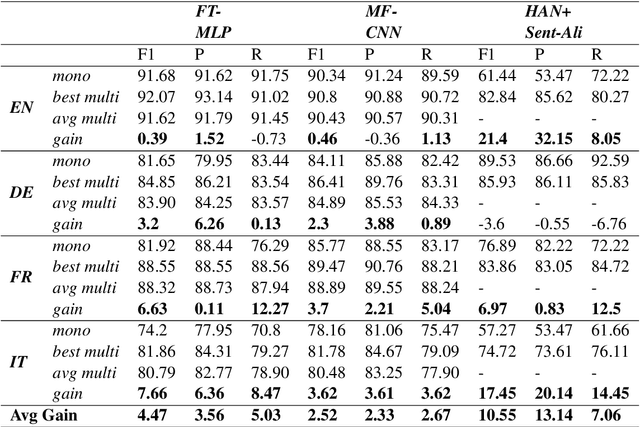
Most work in text classification and Natural Language Processing (NLP) focuses on English or a handful of other languages that have text corpora of hundreds of millions of words. This is creating a new version of the digital divide: the artificial intelligence (AI) divide. Transfer-based approaches, such as Cross-Lingual Text Classification (CLTC) - the task of categorizing texts written in different languages into a common taxonomy, are a promising solution to the emerging AI divide. Recent work on CLTC has focused on demonstrating the benefits of using bilingual word embeddings as features, relegating the CLTC problem to a mere benchmark based on a simple averaged perceptron. In this paper, we explore more extensively and systematically two flavors of the CLTC problem: news topic classification and textual churn intent detection (TCID) in social media. In particular, we test the hypothesis that embeddings with context are more effective, by multi-tasking the learning of multilingual word embeddings and text classification; we explore neural architectures for CLTC; and we move from bi- to multi-lingual word embeddings. For all architectures, types of word embeddings and datasets, we notice a consistent gain trend in favor of multilingual joint training, especially for low-resourced languages.
Churn Intent Detection in Multilingual Chatbot Conversations and Social Media
Aug 25, 2018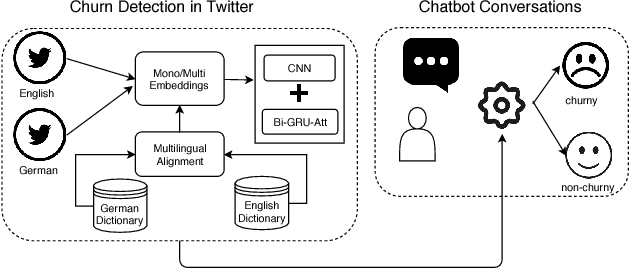


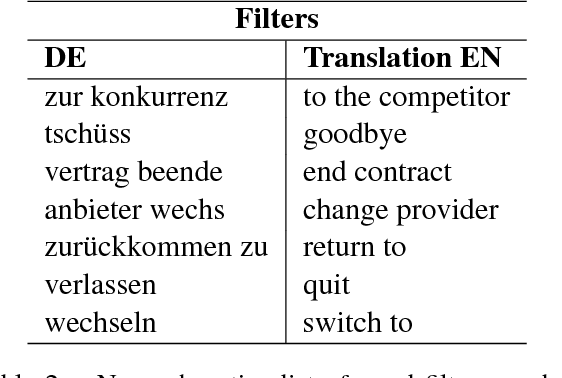
We propose a new method to detect when users express the intent to leave a service, also known as churn. While previous work focuses solely on social media, we show that this intent can be detected in chatbot conversations. As companies increasingly rely on chatbots they need an overview of potentially churny users. To this end, we crowdsource and publish a dataset of churn intent expressions in chatbot interactions in German and English. We show that classifiers trained on social media data can detect the same intent in the context of chatbots. We introduce a classification architecture that outperforms existing work on churn intent detection in social media. Moreover, we show that, using bilingual word embeddings, a system trained on combined English and German data outperforms monolingual approaches. As the only existing dataset is in English, we crowdsource and publish a novel dataset of German tweets. We thus underline the universal aspect of the problem, as examples of churn intent in English help us identify churn in German tweets and chatbot conversations.