 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2A: Multimodal Memory Agent with Dual-Layer Hybrid Memory for Long-Term Personalized Interactions
Feb 07, 2026This work addresses the challenge of personalized question answering in long-term human-machine interactions: when conversational history spans weeks or months and exceeds the context window, existing personalization mechanisms struggle to continuously absorb and leverage users' incremental concepts, aliases, and preferences. Current personalized multimodal models are predominantly static-concepts are fixed at initialization and cannot evolve during interactions. We propose M2A, an agentic dual-layer hybrid memory system that maintains personalized multimodal information through online updates. The system employs two collaborative agents: ChatAgent manages user interactions and autonomously decides when to query or update memory, while MemoryManager breaks down memory requests from ChatAgent into detailed operations on the dual-layer memory bank, which couples a RawMessageStore (immutable conversation log) with a SemanticMemoryStore (high-level observations), providing memories at different granularities. In addition, we develop a reusable data synthesis pipeline that injects concept-grounded sessions from Yo'LLaVA and MC-LLaVA into LoCoMo long conversations while preserving temporal coherence. Experiments show that M2A significantly outperforms baselines, demonstrating that transforming personalization from one-shot configuration to a co-evolving memory mechanism provides a viable path for high-quality individualized responses in long-term multimodal interactions. The code is available at https://github.com/Little-Fridge/M2A.
Text-to-Video: a Two-stage Framework for Zero-shot Identity-agnostic Talking-head Generation
Aug 12, 2023

The advent of ChatGPT has introduced innovative methods for information gathering and analysis. However, the information provided by ChatGPT is limited to text, and the visualization of this information remains constrained. Previous research has explored zero-shot text-to-video (TTV) approaches to transform text into videos. However, these methods lacked control over the identity of the generated audio, i.e., not identity-agnostic, hindering their effectiveness. To address this limitation, we propose a novel two-stage framework for person-agnostic video cloning, specifically focusing on TTV generation. In the first stage, we leverage pretrained zero-shot models to achieve text-to-speech (TTS) conversion. In the second stage, an audio-driven talking head generation method is employed to produce compelling videos privided the audio generated in the first stage. This paper presents a comparative analysis of different TTS and audio-driven talking head generation methods, identifying the most promising approach for future research and development. Some audio and videos samples can be found in the following link: https://github.com/ZhichaoWang970201/Text-to-Video/tree/main.
Implicit Data Augmentation Using Feature Interpolation for Diversified Low-Shot Image Generation
Dec 04, 2021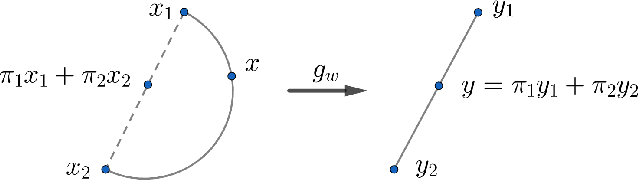
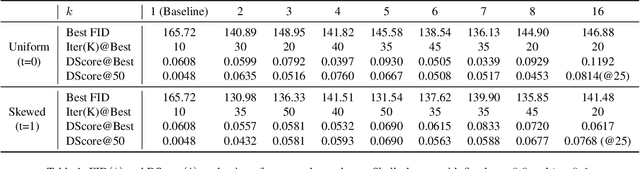
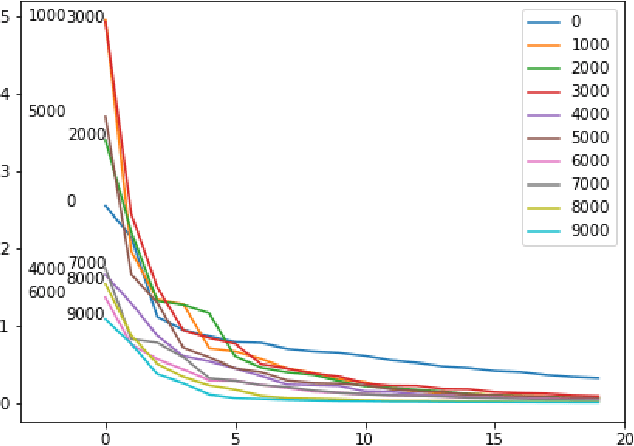
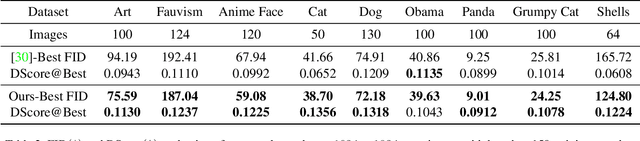
Training of generative models especially Generative Adversarial Networks can easily diverge in low-data setting. To mitigate this issue, we propose a novel implicit data augmentation approach which facilitates stable training and synthesize diverse samples. Specifically, we view the discriminator as a metric embedding of the real data manifold, which offers proper distances between real data points. We then utilize information in the feature space to develop a data-driven augmentation method. We further bring up a simple metric to evaluate the diversity of synthesized samples. Experiments on few-shot generation tasks show our method improves FID and diversity of results compared to current methods, and allows generating high-quality and diverse images with less than 100 training samples.
AWGAN: Empowering High-Dimensional Discriminator Output for Generative Adversarial Networks
Sep 08, 2021
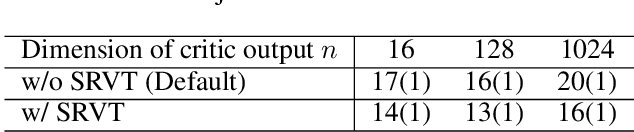
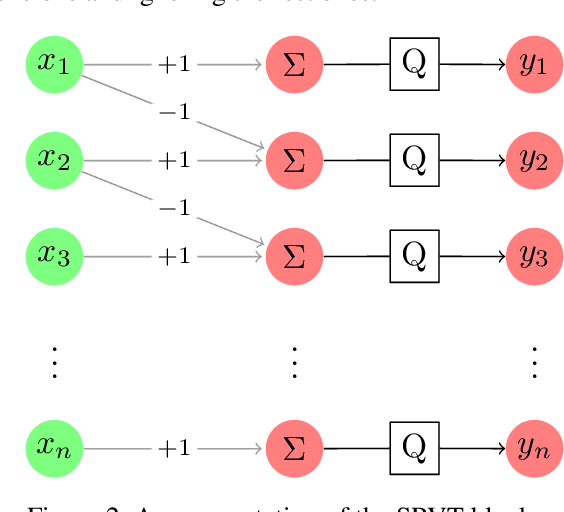
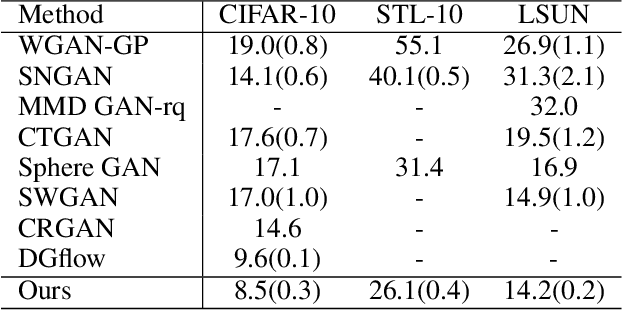
Empirically multidimensional discriminator (critic) output can be advantageous, while a solid explanation for it has not been discussed. In this paper, (i) we rigorously prove that high-dimensional critic output has advantage on distinguishing real and fake distributions; (ii) we also introduce an square-root velocity transformation (SRVT) block which further magnifies this advantage. The proof is based on our proposed maximal p-centrality discrepancy which is bounded above by p-Wasserstein distance and perfectly fits the Wasserstein GAN framework with high-dimensional critic output n. We have also showed when n = 1, the proposed discrepancy is equivalent to 1-Wasserstein distance. The SRVT block is applied to break the symmetric structure of high-dimensional critic output and improve the generalization capability of the discriminator network. In terms of implementation, the proposed framework does not require additional hyper-parameter tuning, which largely facilitates its usage. Experiments on image generation tasks show performance improvement on benchmark datasets.
Adversarial Manifold Matching via Deep Metric Learning for Generative Modeling
Jun 20, 2021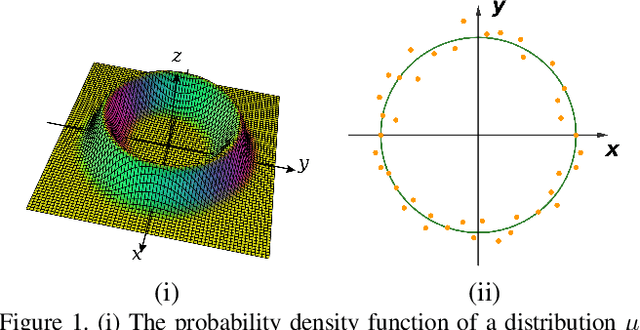
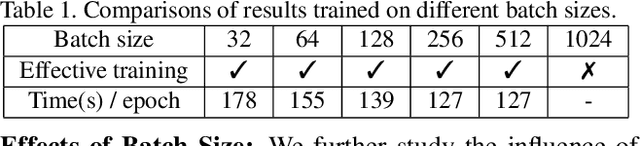
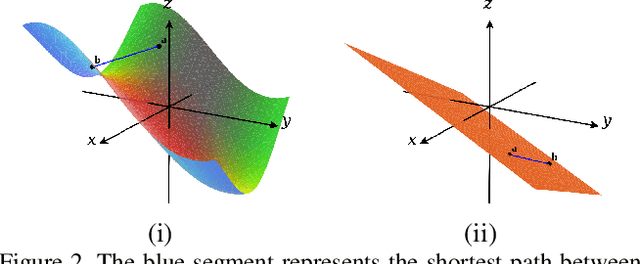
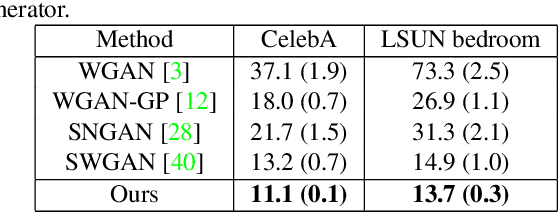
We propose a manifold matching approach to generative models which includes a distribution generator (or data generator) and a metric generator. In our framework, we view the real data set as some manifold embedded in a high-dimensional Euclidean space. The distribution generator aims at generating samples that follow some distribution condensed around the real data manifold. It is achieved by matching two sets of points using their geometric shape descriptors, such as centroid and $p$-diameter, with learned distance metric; the metric generator utilizes both real data and generated samples to learn a distance metric which is close to some intrinsic geodesic distance on the real data manifold. The produced distance metric is further used for manifold matching. The two networks are learned simultaneously during the training process. We apply the approach on both unsupervised and supervised learning tasks: in unconditional image generation task, the proposed method obtains competitive results compared with existing generative models; in super-resolution task, we incorporate the framework in perception-based models and improve visual qualities by producing samples with more natural textures. Both theoretical analysis and real data experiments guarantee the feasibility and effectiveness of the proposed framework.
Analyzing Dynamical Brain Functional Connectivity As Trajectories on Space of Covariance Matrices
May 15, 2019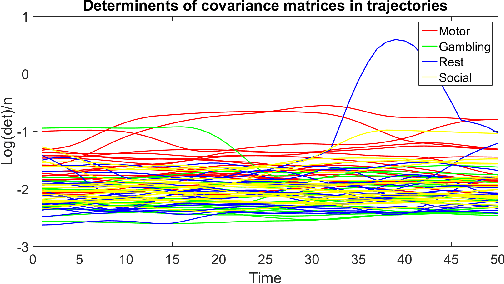
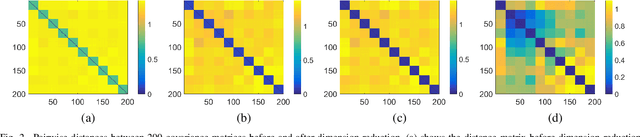
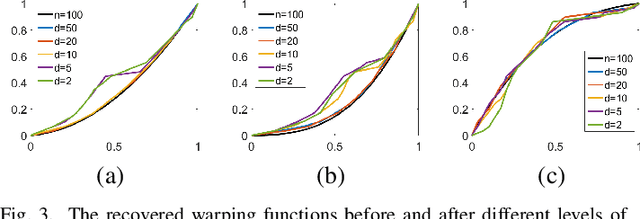
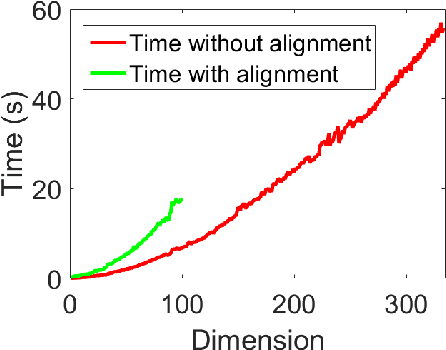
Human brain functional connectivity (FC) is often measured as the similarity of functional MRI responses across brain regions when a brain is either resting or performing a task. This paper aims to statistically analyze the dynamic nature of FC by representing the collective time-series data, over a set of brain regions, as a trajectory on the space of covariance matrices, or symmetric-positive definite matrices (SPDMs). We use a recently developed metric on the space of SPDMs for quantifying differences across FC observations, and for clustering and classification of FC trajectories. To facilitate large scale and high-dimensional data analysis, we propose a novel, metric-based dimensionality reduction technique to reduce data from large SPDMs to small SPDMs. We illustrate this comprehensive framework using data from the Human Connectome Project (HCP) database for multiple subjects and tasks, with task classification rates that match or outperform state-of-the-art techniques.
Discovering Common Change-Point Patterns in Functional Connectivity Across Subjects
Apr 26, 2019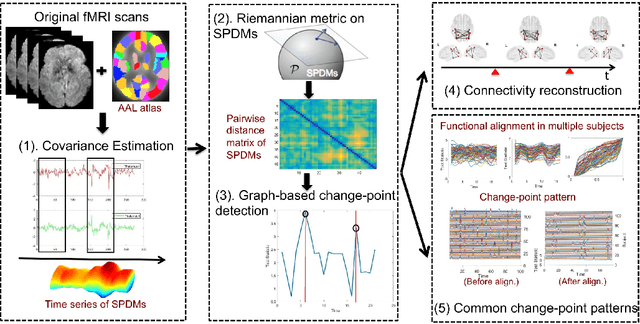
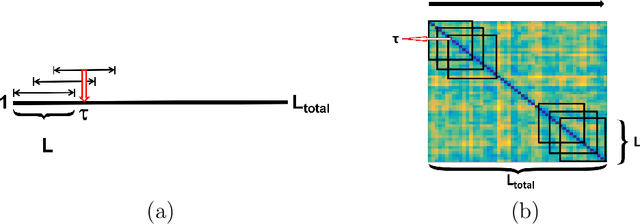
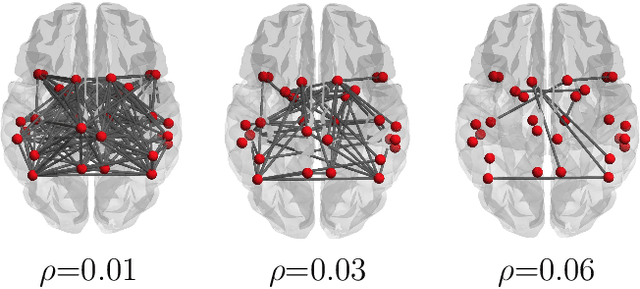
This paper studies change-points in human brain functional connectivity (FC) and seeks patterns that are common across multiple subjects under identical external stimulus. FC relates to the similarity of fMRI responses across different brain regions when the brain is simply resting or performing a task. While the dynamic nature of FC is well accepted, this paper develops a formal statistical test for finding {\it change-points} in times series associated with FC. It represents short-term connectivity by a symmetric positive-definite matrix, and uses a Riemannian metric on this space to develop a graphical method for detecting change-points in a time series of such matrices. It also provides a graphical representation of estimated FC for stationary subintervals in between the detected change-points. Furthermore, it uses a temporal alignment of the test statistic, viewed as a real-valued function over time, to remove inter-subject variability and to discover common change-point patterns across subjects. This method is illustrated using data from Human Connectome Project (HCP) database for multiple subjects and tasks.