 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAP: A Graph-aware Language Model Framework for Knowledge Graph-to-Text Generation
Apr 13, 2022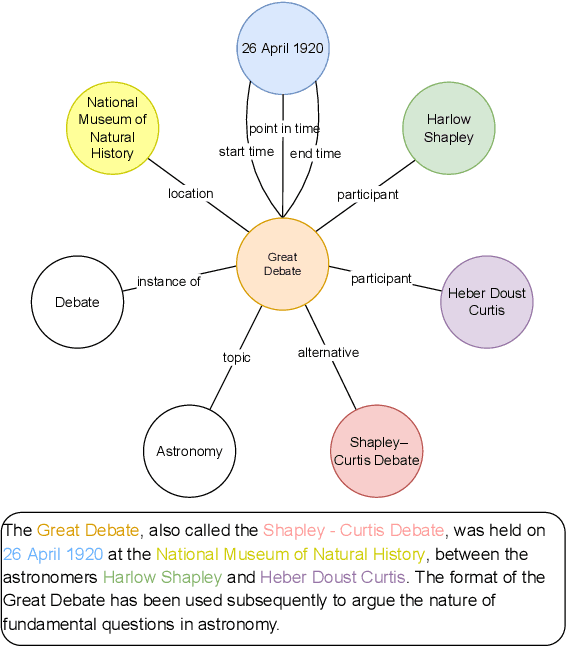

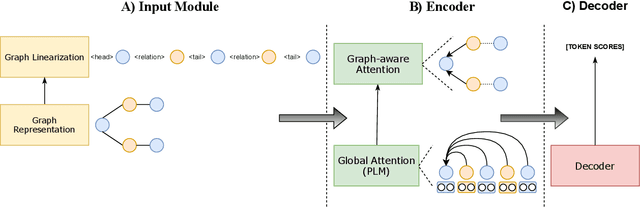
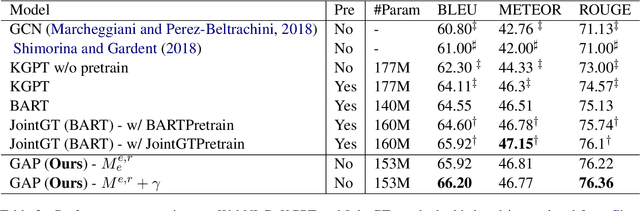
Recent improvements in KG-to-text generation are due to additional auxiliary pre-trained tasks designed to give the fine-tune task a boost in performance. These tasks require extensive computational resources while only suggesting marginal improvements. Here, we demonstrate that by fusing graph-aware elements into existing pre-trained language models, we are able to outperform state-of-the-art models and close the gap imposed by additional pre-train tasks. We do so by proposing a mask structure to capture neighborhood information and a novel type encoder that adds a bias to the graph-attention weights depending on the connection type. Experiments on two KG-to-text benchmark datasets show these models to be superior in quality while involving fewer parameters and no additional pre-trained tasks. By formulating the problem as a framework, we can interchange the various proposed components and begin interpreting KG-to-text generative models based on the topological and type information found in a graph.
Provably Convergent Learned Inexact Descent Algorithm for Low-Dose CT Reconstruction
Apr 27, 2021
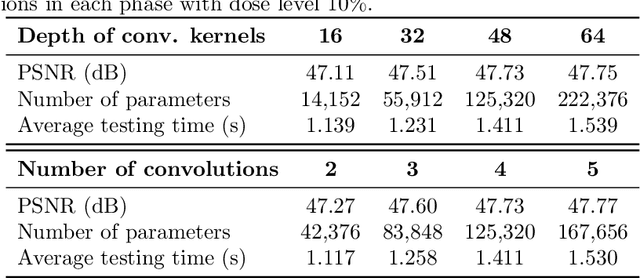
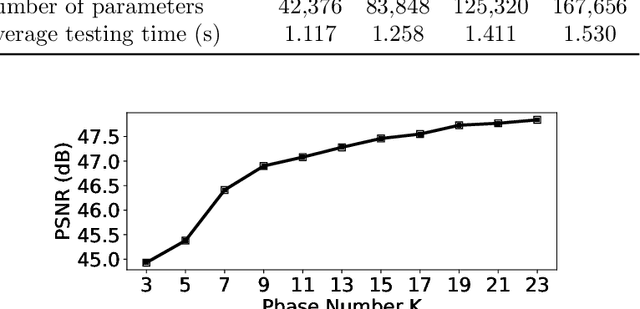
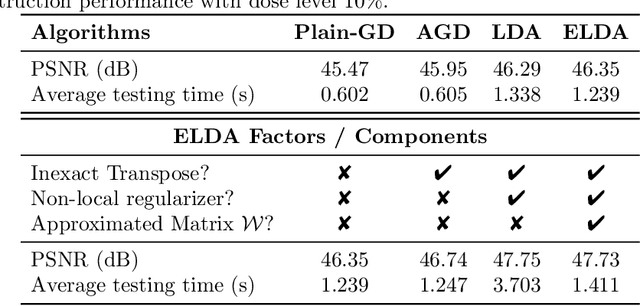
We propose a provably convergent method, called Efficient Learned Descent Algorithm (ELDA), for low-dose CT (LDCT) reconstruction. ELDA is a highly interpretable neural network architecture with learned parameters and meanwhile retains convergence guarantee as classical optimization algorithms. To improve reconstruction quality, the proposed ELDA also employs a new non-local feature mapping and an associated regularizer. We compare ELDA with several state-of-the-art deep image methods, such as RED-CNN and Learned Primal-Dual, on a set of LDCT reconstruction problems. Numerical experiments demonstrate improvement of reconstruction quality using ELDA with merely 19 layers, suggesting the promising performance of ELDA in solution accuracy and parameter efficiency.