 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAP: A Graph-aware Language Model Framework for Knowledge Graph-to-Text Generation
Paper and Code

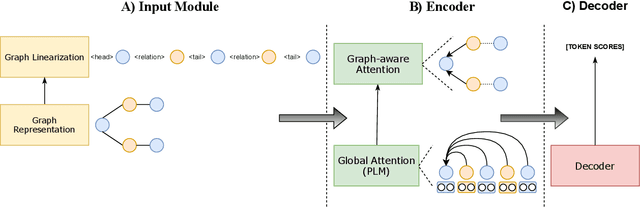
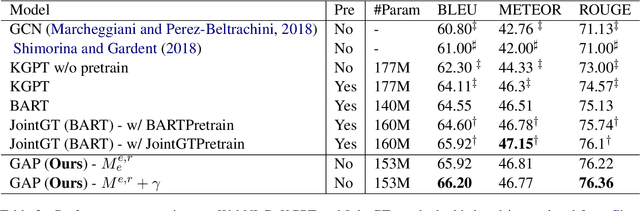
Recent improvements in KG-to-text generation are due to additional auxiliary pre-trained tasks designed to give the fine-tune task a boost in performance. These tasks require extensive computational resources while only suggesting marginal improvements. Here, we demonstrate that by fusing graph-aware elements into existing pre-trained language models, we are able to outperform state-of-the-art models and close the gap imposed by additional pre-train tasks. We do so by proposing a mask structure to capture neighborhood information and a novel type encoder that adds a bias to the graph-attention weights depending on the connection type. Experiments on two KG-to-text benchmark datasets show these models to be superior in quality while involving fewer parameters and no additional pre-trained tasks. By formulating the problem as a framework, we can interchange the various proposed components and begin interpreting KG-to-text generative models based on the topological and type information found in a graph.