 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: A Foundation Model-driven Framework for Robust Task Planning and Failure Recovery in Robotic Systems
Mar 08, 2025
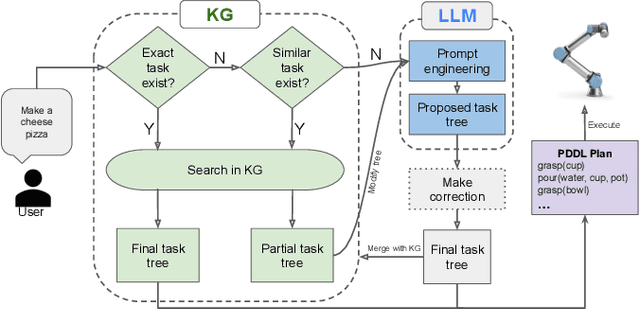
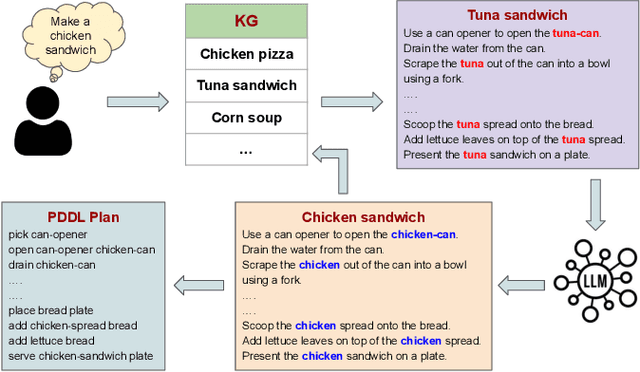
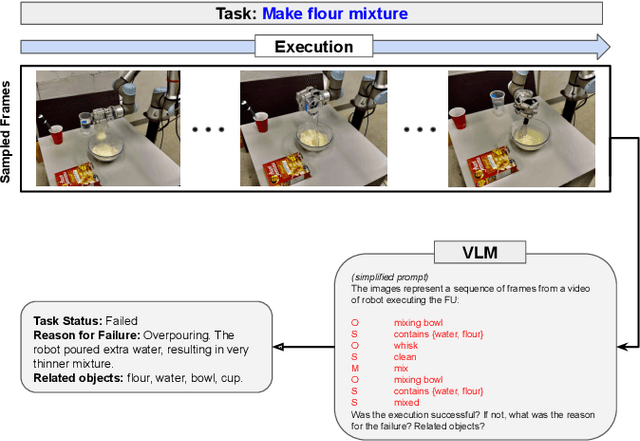
Modern robotic systems, deployed across domains from industrial automation to domestic assistance, face a critical challenge: executing tasks with precision and adaptability in dynamic, unpredictable environments. To address this, we propose STAR (Smart Task Adaptation and Recovery), a novel framework that synergizes Foundation Models (FMs) with dynamically expanding Knowledge Graphs (KGs) to enable resilient task planning and autonomous failure recovery. While FMs offer remarkable generalization and contextual reasoning, their limitations, including computational inefficiency, hallucinations, and output inconsistencies hinder reliable deployment. STAR mitigates these issues by embedding learned knowledge into structured, reusable KGs, which streamline information retrieval, reduce redundant FM computations, and provide precise, scenario-specific insights. The framework leverages FM-driven reasoning to diagnose failures, generate context-aware recovery strategies, and execute corrective actions without human intervention or system restarts. Unlike conventional approaches that rely on rigid protocols, STAR dynamically expands its KG with experiential knowledge, ensuring continuous adaptation to novel scenarios. To evaluate the effectiveness of this approach, we developed a comprehensive dataset that includes various robotic tasks and failure scenarios. Through extensive experimentation, STAR demonstrated an 86% task planning accuracy and 78% recovery success rate, showing significant improvements over baseline methods. The framework's ability to continuously learn from experience while maintaining structured knowledge representation makes it particularly suitable for long-term deployment in real-world applications.
Consolidating Trees of Robotic Plans Generated Using Large Language Models to Improve Reliability
Jan 15, 2024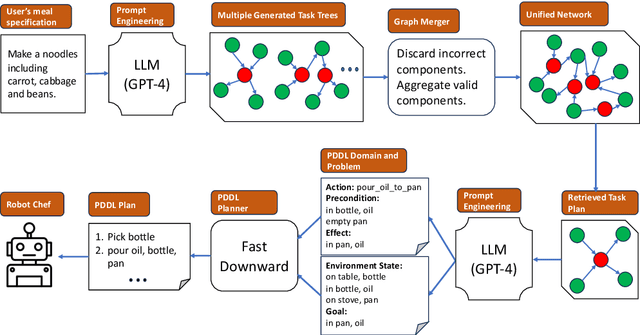

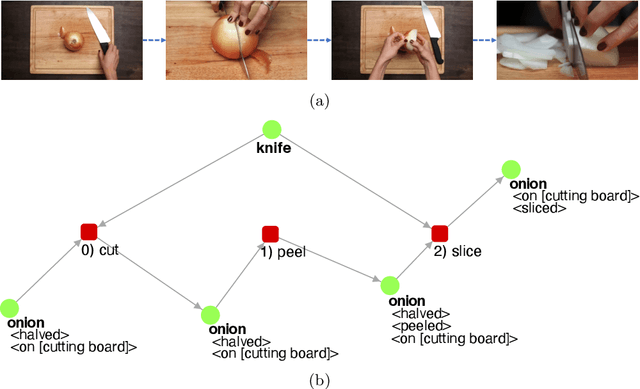
The inherent probabilistic nature of Large Language Models (LLMs) introduces an element of unpredictability, raising concerns about potential discrepancies in their output. This paper introduces an innovative approach aims to generate correct and optimal robotic task plans for diverse real-world demands and scenarios. LLMs have been used to generate task plans, but they are unreliable and may contain wrong, questionable, or high-cost steps. The proposed approach uses LLM to generate a number of task plans as trees and amalgamates them into a graph by removing questionable paths. Then an optimal task tree can be retrieved to circumvent questionable and high-cost nodes, thereby improving planning accuracy and execution efficiency. The approach is further improved by incorporating a large knowledge network. Leveraging GPT-4 further, the high-level task plan is converted into a low-level Planning Domain Definition Language (PDDL) plan executable by a robot. Evaluation results highlight the superior accuracy and efficiency of our approach compared to previous methodologies in the field of task planning.
From Cooking Recipes to Robot Task Trees -- Improving Planning Correctness and Task Efficiency by Leveraging LLMs with a Knowledge Network
Sep 17, 2023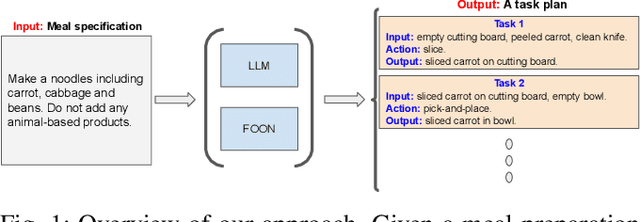

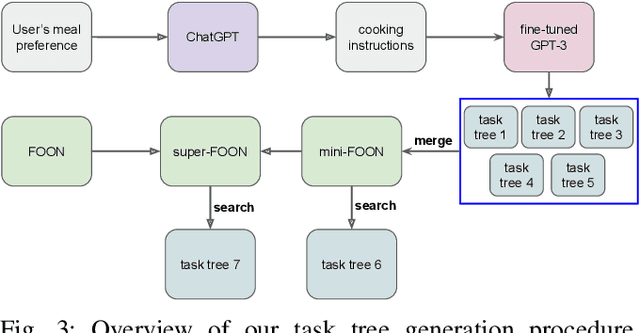

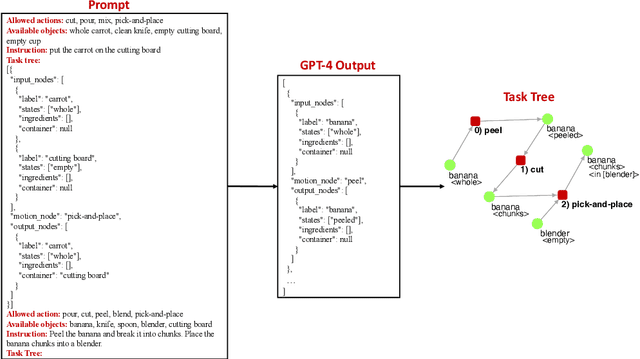
Task planning for robotic cooking involves generating a sequence of actions for a robot to prepare a meal successfully. This paper introduces a novel task tree generation pipeline producing correct planning and efficient execution for cooking tasks. Our method first uses a large language model (LLM) to retrieve recipe instructions and then utilizes a fine-tuned GPT-3 to convert them into a task tree, capturing sequential and parallel dependencies among subtasks. The pipeline then mitigates the uncertainty and unreliable features of LLM outputs using task tree retrieval. We combine multiple LLM task tree outputs into a graph and perform a task tree retrieval to avoid questionable nodes and high-cost nodes to improve planning correctness and improve execution efficiency. Our evaluation results show its superior performance compared to previous works in task planning accuracy and efficiency.
Evaluating Recipes Generated from Functional Object-Oriented Network
Jun 01, 2021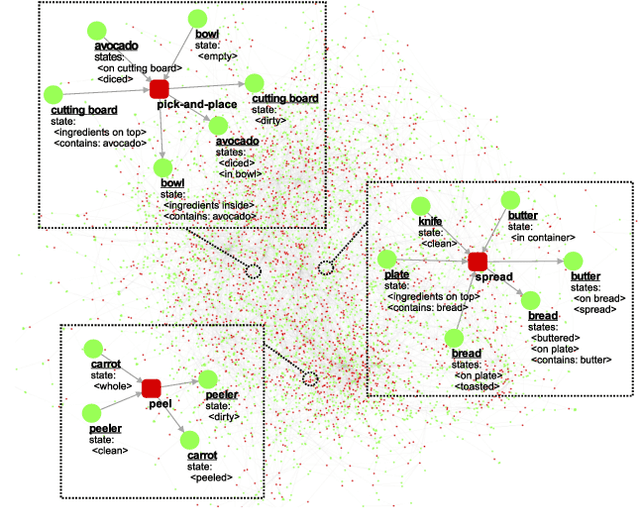
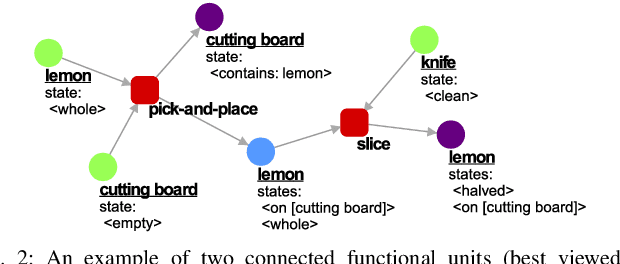
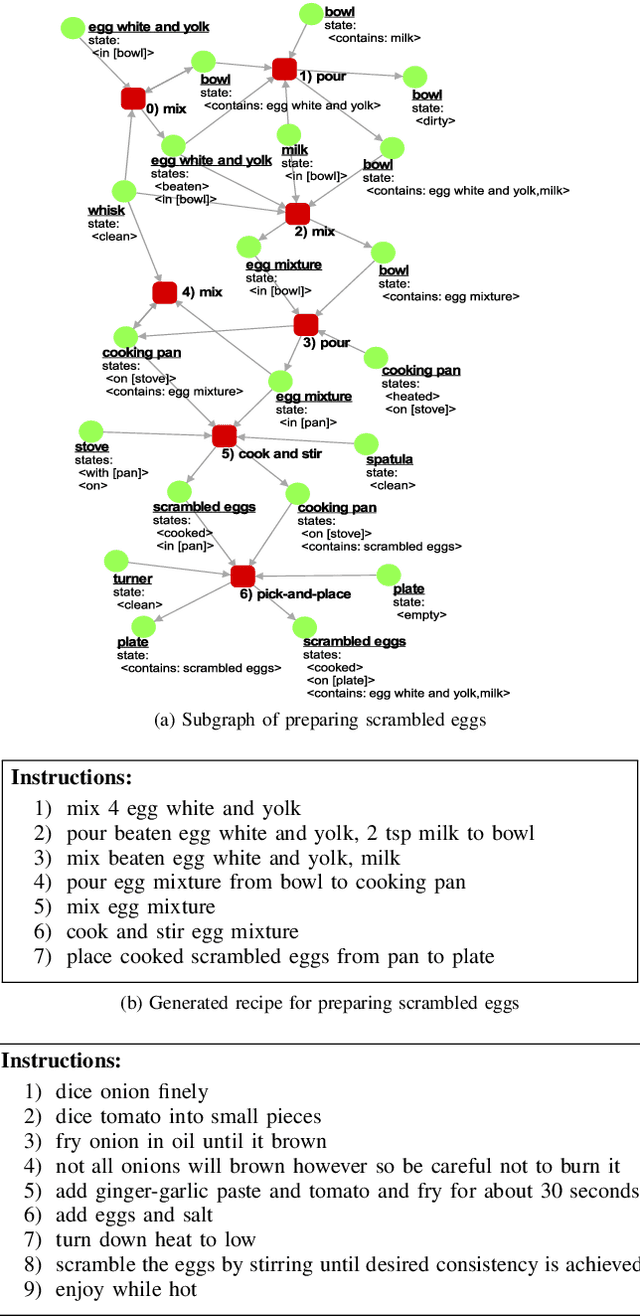

The functional object-oriented network (FOON) has been introduced as a knowledge representation, which takes the form of a graph, for symbolic task planning. To get a sequential plan for a manipulation task, a robot can obtain a task tree through a knowledge retrieval process from the FOON. To evaluate the quality of an acquired task tree, we compare it with a conventional form of task knowledge, such as recipes or manuals. We first automatically convert task trees to recipes, and we then compare them with the human-created recipes in the Recipe1M+ dataset via a survey. Our preliminary study finds no significant difference between the recipes in Recipe1M+ and the recipes generated from FOON task trees in terms of correctness, completeness, and clarity.
Cooking Object's State Identification Without Using Pretrained Model
Mar 03, 2021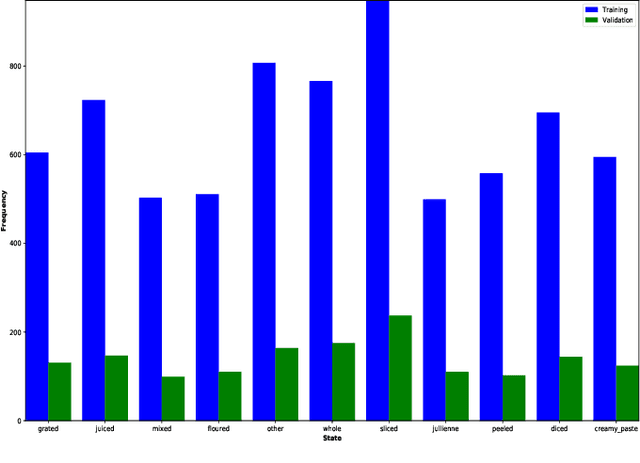
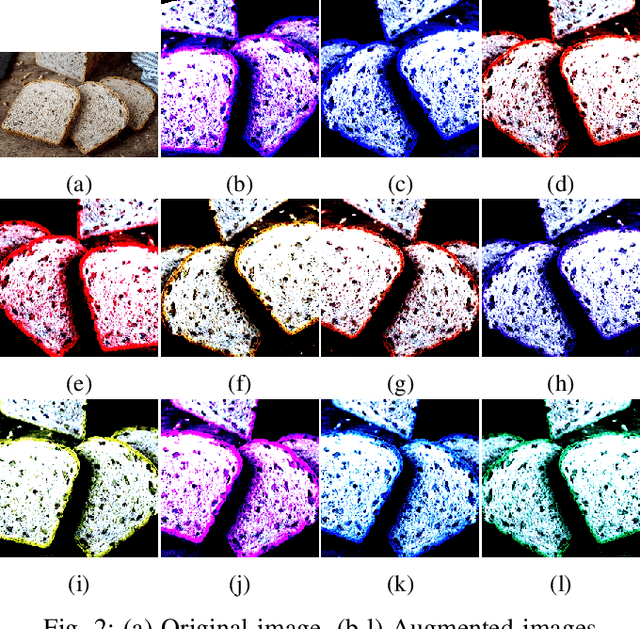
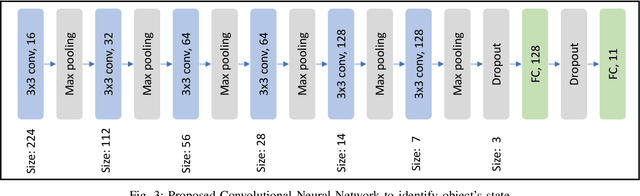
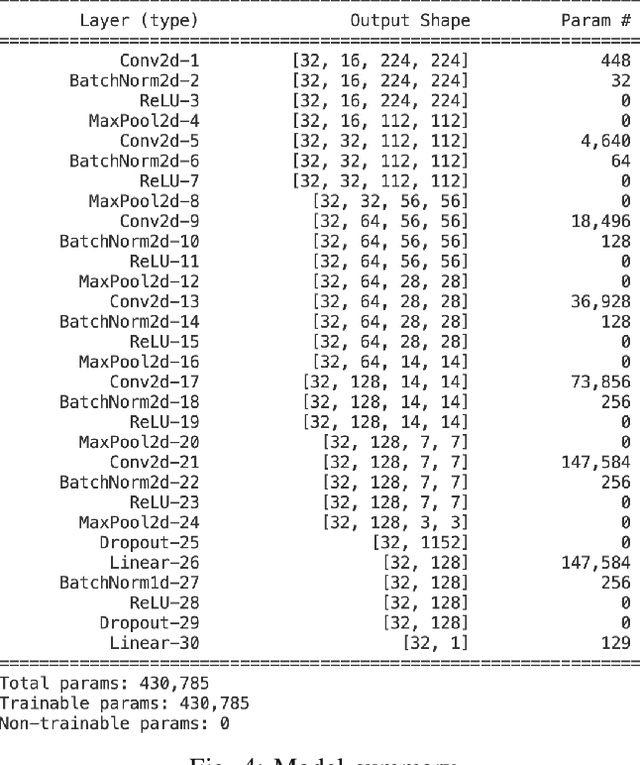
Recently, Robotic Cooking has been a very promising field. To execute a recipe, a robot has to recognize different objects and their states. Contrary to object recognition, state identification has not been explored that much. But it is very important because different recipe might require different state of an object. Moreover, robotic grasping depends on the state. Pretrained model usually perform very well in this type of tests. Our challenge was to handle this problem without using any pretrained model. In this paper, we have proposed a CNN and trained it from scratch. The model is trained and tested on the dataset from cooking state recognition challenge. We have also evaluated the performance of our network from various perspective. Our model achieves 65.8% accuracy on the unseen test dataset.
A Gray Box Interpretable Visual Debugging Approach for Deep Sequence Learning Model
Nov 20, 2018
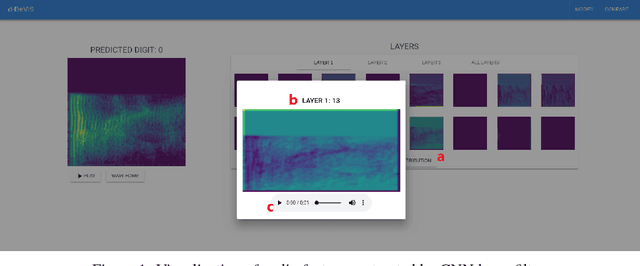
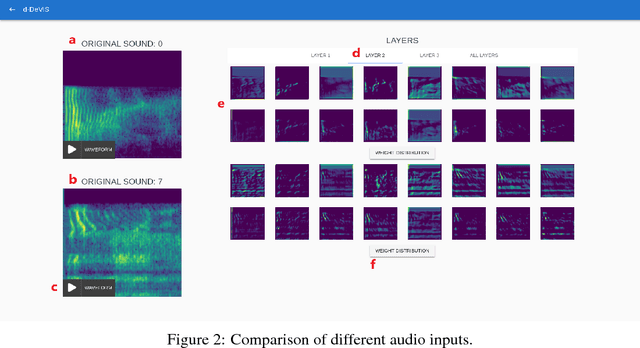
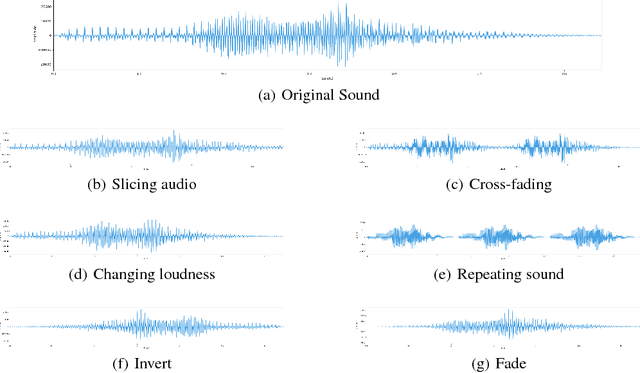
Deep Learning algorithms are often used as black box type learning and they are too complex to understand. The widespread usability of Deep Learning algorithms to solve various machine learning problems demands deep and transparent understanding of the internal representation as well as decision making. Moreover, the learning models, trained on sequential data, such as audio and video data, have intricate internal reasoning process due to their complex distribution of features. Thus, a visual simulator might be helpful to trace the internal decision making mechanisms in response to adversarial input data, and it would help to debug and design appropriate deep learning models. However, interpreting the internal reasoning of deep learning model is not well studied in the literature. In this work, we have developed a visual interactive web application, namely d-DeVIS, which helps to visualize the internal reasoning of the learning model which is trained on the audio data. The proposed system allows to perceive the behavior as well as to debug the model by interactively generating adversarial audio data point. The web application of d-DeVIS is available at ddevis.herokuapp.com.