 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSD-QA: Spoken Dialectal Question Answering for the Real World
Sep 24, 2021


Question answering (QA) systems are now available through numerous commercial applications for a wide variety of domains, serving millions of users that interact with them via speech interfaces. However, current benchmarks in QA research do not account for the errors that speech recognition models might introduce, nor do they consider the language variations (dialects) of the users. To address this gap, we augment an existing QA dataset to construct a multi-dialect, spoken QA benchmark on five languages (Arabic, Bengali, English, Kiswahili, Korean) with more than 68k audio prompts in 24 dialects from 255 speakers. We provide baseline results showcasing the real-world performance of QA systems and analyze the effect of language variety and other sensitive speaker attributes on downstream performance. Last, we study the fairness of the ASR and QA models with respect to the underlying user populations. The dataset, model outputs, and code for reproducing all our experiments are available: https://github.com/ffaisal93/SD-QA.
On the Evaluation of Machine Translation for Terminology Consistency
Jun 24, 2021
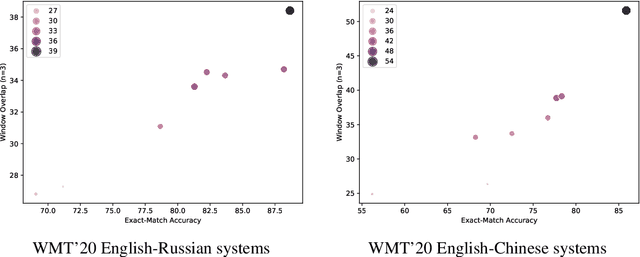


As neural machine translation (NMT) systems become an important part of professional translator pipelines, a growing body of work focuses on combining NMT with terminologies. In many scenarios and particularly in cases of domain adaptation, one expects the MT output to adhere to the constraints provided by a terminology. In this work, we propose metrics to measure the consistency of MT output with regards to a domain terminology. We perform studies on the COVID-19 domain over 5 languages, also performing terminology-targeted human evaluation. We open-source the code for computing all proposed metrics: https://github.com/mahfuzibnalam/terminology_evaluation