 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Attention Networks for Attribution of Early Modern Print
Jun 12, 2023



In this paper, we develop machine learning techniques to identify unknown printers in early modern (c.~1500--1800) English printed books. Specifically, we focus on matching uniquely damaged character type-imprints in anonymously printed books to works with known printers in order to provide evidence of their origins. Until now, this work has been limited to manual investigations by analytical bibliographers. We present a Contrastive Attention-based Metric Learning approach to identify similar damage across character image pairs, which is sensitive to very subtle differences in glyph shapes, yet robust to various confounding sources of noise associated with digitized historical books. To overcome the scarce amount of supervised data, we design a random data synthesis procedure that aims to simulate bends, fractures, and inking variations induced by the early printing process. Our method successfully improves downstream damaged type-imprint matching among printed works from this period, as validated by in-domain human experts. The results of our approach on two important philosophical works from the Early Modern period demonstrate potential to extend the extant historical research about the origins and content of these books.
Sequential changepoint detection for label shift in classification
Sep 18, 2020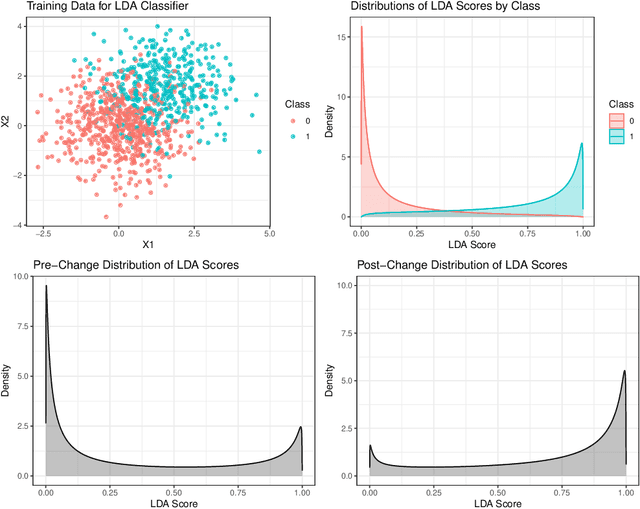
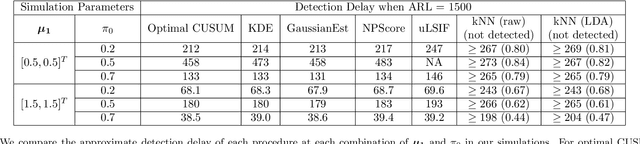

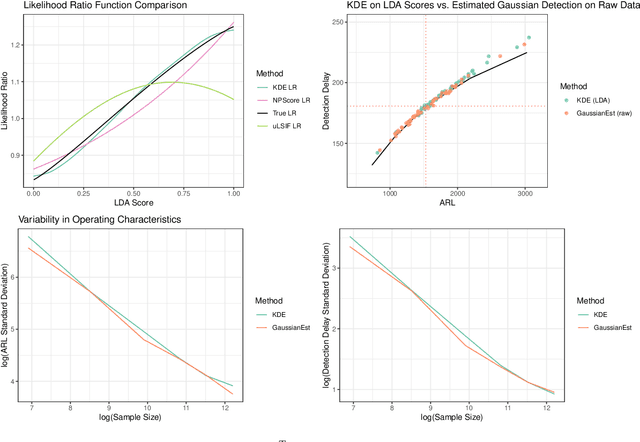
Classifier predictions often rely on the assumption that new observations come from the same distribution as training data. When the underlying distribution changes, so does the optimal classifier rule, and predictions may no longer be valid. We consider the problem of detecting a change to the overall fraction of positive cases, known as label shift, in sequentially-observed binary classification data. We reduce this problem to the problem of detecting a change in the one-dimensional classifier scores, which allows us to develop simple nonparametric sequential changepoint detection procedures. Our procedures leverage classifier training data to estimate the detection statistic, and converge to their parametric counterparts in the size of the training data. In simulations, we show that our method compares favorably to other detection procedures in the label shift setting.
A Probabilistic Generative Model for Typographical Analysis of Early Modern Printing
May 04, 2020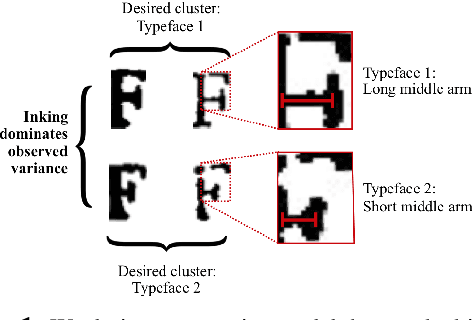
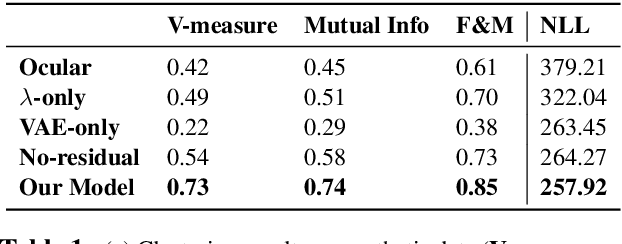

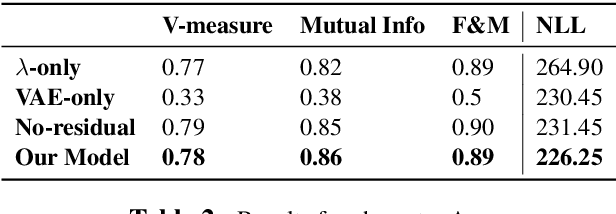
We propose a deep and interpretable probabilistic generative model to analyze glyph shapes in printed Early Modern documents. We focus on clustering extracted glyph images into underlying templates in the presence of multiple confounding sources of variance. Our approach introduces a neural editor model that first generates well-understood printing phenomena like spatial perturbations from template parameters via interpertable latent variables, and then modifies the result by generating a non-interpretable latent vector responsible for inking variations, jitter, noise from the archiving process, and other unforeseen phenomena associated with Early Modern printing. Critically, by introducing an inference network whose input is restricted to the visual residual between the observation and the interpretably-modified template, we are able to control and isolate what the vector-valued latent variable captures. We show that our approach outperforms rigid interpretable clustering baselines (Ocular) and overly-flexible deep generative models (VAE) alike on the task of completely unsupervised discovery of typefaces in mixed-font documents.
Fairer and more accurate, but for whom?
Jun 30, 2017



Complex statistical machine learning models are increasingly being used or considered for use in high-stakes decision-making pipelines in domains such as financial services, health care, criminal justice and human services. These models are often investigated as possible improvements over more classical tools such as regression models or human judgement. While the modeling approach may be new, the practice of using some form of risk assessment to inform decisions is not. When determining whether a new model should be adopted, it is therefore essential to be able to compare the proposed model to the existing approach across a range of task-relevant accuracy and fairness metrics. Looking at overall performance metrics, however, may be misleading. Even when two models have comparable overall performance, they may nevertheless disagree in their classifications on a considerable fraction of cases. In this paper we introduce a model comparison framework for automatically identifying subgroups in which the differences between models are most pronounced. Our primary focus is on identifying subgroups where the models differ in terms of fairness-related quantities such as racial or gender disparities. We present experimental results from a recidivism prediction task and a hypothetical lending example.
Distribution-Free Predictive Inference For Regression
Mar 08, 2017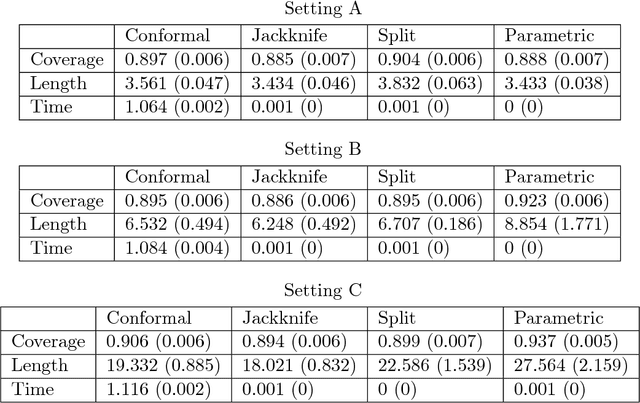
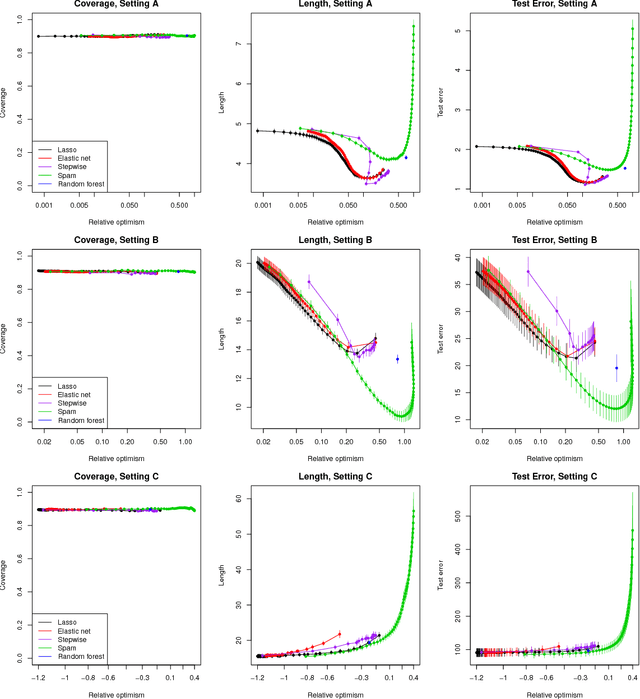


We develop a general framework for distribution-free predictive inference in regression, using conformal inference. The proposed methodology allows for the construction of a prediction band for the response variable using any estimator of the regression function. The resulting prediction band preserves the consistency properties of the original estimator under standard assumptions, while guaranteeing finite-sample marginal coverage even when these assumptions do not hold. We analyze and compare, both empirically and theoretically, the two major variants of our conformal framework: full conformal inference and split conformal inference, along with a related jackknife method. These methods offer different tradeoffs between statistical accuracy (length of resulting prediction intervals) and computational efficiency. As extensions, we develop a method for constructing valid in-sample prediction intervals called {\it rank-one-out} conformal inference, which has essentially the same computational efficiency as split conformal inference. We also describe an extension of our procedures for producing prediction bands with locally varying length, in order to adapt to heteroskedascity in the data. Finally, we propose a model-free notion of variable importance, called {\it leave-one-covariate-out} or LOCO inference. Accompanying this paper is an R package {\tt conformalInference} that implements all of the proposals we have introduced. In the spirit of reproducibility, all of our empirical results can also be easily (re)generated using this package.