 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep residual learning implementation of Metamorphosis
Feb 01, 2022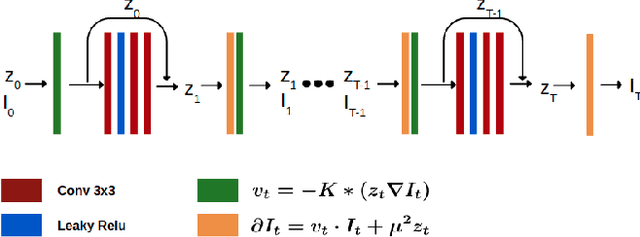
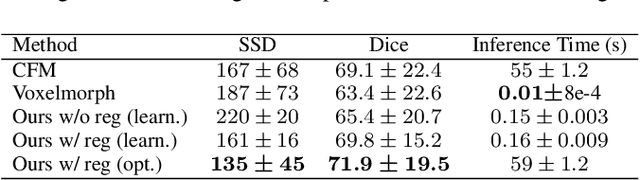
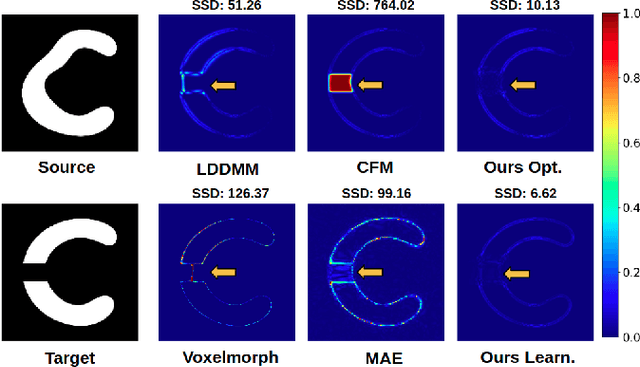
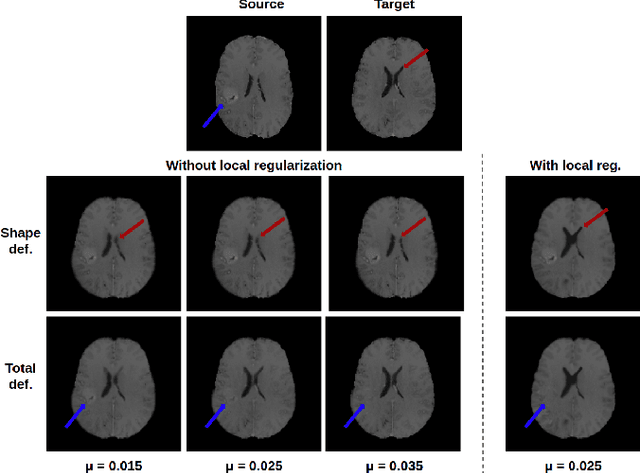
In medical imaging, most of the image registration methods implicitly assume a one-to-one correspondence between the source and target images (i.e., diffeomorphism). However, this is not necessarily the case when dealing with pathological medical images (e.g., presence of a tumor, lesion, etc.). To cope with this issue, the Metamorphosis model has been proposed. It modifies both the shape and the appearance of an image to deal with the geometrical and topological differences. However, the high computational time and load have hampered its applications so far. Here, we propose a deep residual learning implementation of Metamorphosis that drastically reduces the computational time at inference. Furthermore, we also show that the proposed framework can easily integrate prior knowledge of the localization of topological changes (e.g., segmentation masks) that can act as spatial regularization to correctly disentangle appearance and shape changes. We test our method on the BraTS 2021 dataset, showing that it outperforms current state-of-the-art methods in the alignment of images with brain tumors.
Knowledge distillation from multi-modal to mono-modal segmentation networks
Jun 17, 2021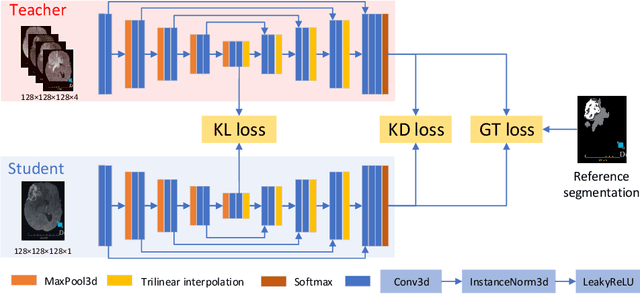
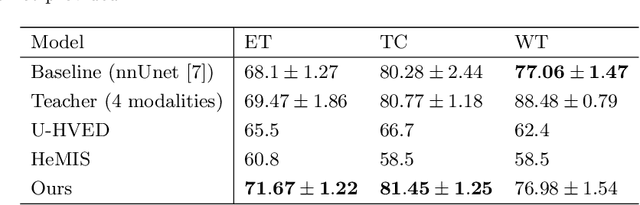
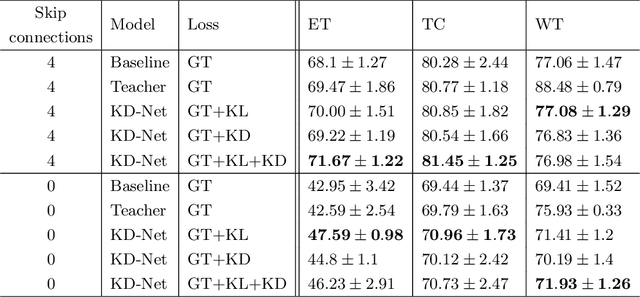
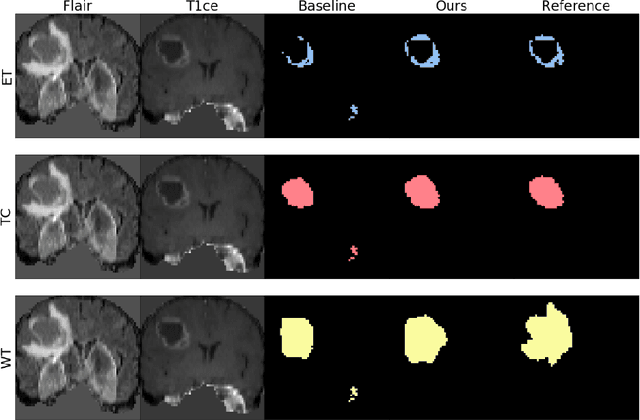
The joint use of multiple imaging modalities for medical image segmentation has been widely studied in recent years. The fusion of information from different modalities has demonstrated to improve the segmentation accuracy, with respect to mono-modal segmentations, in several applications. However, acquiring multiple modalities is usually not possible in a clinical setting due to a limited number of physicians and scanners, and to limit costs and scan time. Most of the time, only one modality is acquired. In this paper, we propose KD-Net, a framework to transfer knowledge from a trained multi-modal network (teacher) to a mono-modal one (student). The proposed method is an adaptation of the generalized distillation framework where the student network is trained on a subset (1 modality) of the teacher's inputs (n modalities). We illustrate the effectiveness of the proposed framework in brain tumor segmentation with the BraTS 2018 dataset. Using different architectures, we show that the student network effectively learns from the teacher and always outperforms the baseline mono-modal network in terms of segmentation accuracy.
* MICCAI 2020