 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure and Scale in Simplicial Sequence Modelling
May 31, 2026Modern large-scale deep learning exhibits two striking empirical phenomena: behavioural scaling laws (predictable performance gains with increasing scale) and emergent mechanisms (structured internal representations and circuits in deep neural networks). We hypothesise that these two phenomena are connected: that predictable changes in behaviour are the result of predictable changes in internal computational structure. In this paper, we report preliminary evidence of such a connection. We find a correlation between scaling patterns in performance and representations in small transformers trained to predict the outputs of a hidden Markov model, for which residual activations are known to linearly encode a belief distribution over latent states in a probability simplex.
Temporal Task Diversity: Inductive Biases Under Non-Stationarity in Synthetic Sequence Modelling
May 18, 2026Modern deep learning science often assumes that neural networks learn from a fixed data distribution. However, many practically important learning problems involve data distributions that change throughout training. How does such non-stationarity impact the inductive biases of deep learning towards models with different structural, generalisation, and safety properties? A fruitful testbed for studying inductive bias is in-context linear regression sequence modelling, where small transformers display strikingly different generalisation patterns depending on the diversity of the (fixed) training task distribution. In this paper, we explore the effect of diversifying the task distribution across training time, finding that such temporal diversity leads to an increased bias towards generalisation over memorisation.
Stagewise Reinforcement Learning and the Geometry of the Regret Landscape
Jan 12, 2026Singular learning theory characterizes Bayesian learning as an evolving tradeoff between accuracy and complexity, with transitions between qualitatively different solutions as sample size increases. We extend this theory to deep reinforcement learning, proving that the concentration of the generalized posterior over policies is governed by the local learning coefficient (LLC), an invariant of the geometry of the regret function. This theory predicts that Bayesian phase transitions in reinforcement learning should proceed from simple policies with high regret to complex policies with low regret. We verify this prediction empirically in a gridworld environment exhibiting stagewise policy development: phase transitions over SGD training manifest as "opposing staircases" where regret decreases sharply while the LLC increases. Notably, the LLC detects phase transitions even when estimated on a subset of states where the policies appear identical in terms of regret, suggesting it captures changes in the underlying algorithm rather than just performance.
You Are What You Eat -- AI Alignment Requires Understanding How Data Shapes Structure and Generalisation
Feb 08, 2025In this position paper, we argue that understanding the relation between structure in the data distribution and structure in trained models is central to AI alignment. First, we discuss how two neural networks can have equivalent performance on the training set but compute their outputs in essentially different ways and thus generalise differently. For this reason, standard testing and evaluation are insufficient for obtaining assurances of safety for widely deployed generally intelligent systems. We argue that to progress beyond evaluation to a robust mathematical science of AI alignment, we need to develop statistical foundations for an understanding of the relation between structure in the data distribution, internal structure in models, and how these structures underlie generalisation.
Dynamics of Transient Structure in In-Context Linear Regression Transformers
Jan 31, 2025



Modern deep neural networks display striking examples of rich internal computational structure. Uncovering principles governing the development of such structure is a priority for the science of deep learning. In this paper, we explore the transient ridge phenomenon: when transformers are trained on in-context linear regression tasks with intermediate task diversity, they initially behave like ridge regression before specializing to the tasks in their training distribution. This transition from a general solution to a specialized solution is revealed by joint trajectory principal component analysis. Further, we draw on the theory of Bayesian internal model selection to suggest a general explanation for the phenomena of transient structure in transformers, based on an evolving tradeoff between loss and complexity. We empirically validate this explanation by measuring the model complexity of our transformers as defined by the local learning coefficient.
The Developmental Landscape of In-Context Learning
Feb 04, 2024We show that in-context learning emerges in transformers in discrete developmental stages, when they are trained on either language modeling or linear regression tasks. We introduce two methods for detecting the milestones that separate these stages, by probing the geometry of the population loss in both parameter space and function space. We study the stages revealed by these new methods using a range of behavioral and structural metrics to establish their validity.
Computational Complexity of Detecting Proximity to Losslessly Compressible Neural Network Parameters
Jun 05, 2023To better understand complexity in neural networks, we theoretically investigate the idealised phenomenon of lossless network compressibility, whereby an identical function can be implemented with a smaller network. We give an efficient formal algorithm for optimal lossless compression in the setting of single-hidden-layer hyperbolic tangent networks. To measure lossless compressibility, we define the rank of a parameter as the minimum number of hidden units required to implement the same function. Losslessly compressible parameters are atypical, but their existence has implications for nearby parameters. We define the proximate rank of a parameter as the rank of the most compressible parameter within a small $L^\infty$ neighbourhood. Unfortunately, detecting nearby losslessly compressible parameters is not so easy: we show that bounding the proximate rank is an NP-complete problem, using a reduction from Boolean satisfiability via a geometric problem involving covering points in the plane with small squares. These results underscore the computational complexity of measuring neural network complexity, laying a foundation for future theoretical and empirical work in this direction.
Functional Equivalence and Path Connectivity of Reducible Hyperbolic Tangent Networks
May 08, 2023Understanding the learning process of artificial neural networks requires clarifying the structure of the parameter space within which learning takes place. A neural network parameter's functional equivalence class is the set of parameters implementing the same input--output function. For many architectures, almost all parameters have a simple and well-documented functional equivalence class. However, there is also a vanishing minority of reducible parameters, with richer functional equivalence classes caused by redundancies among the network's units. In this paper, we give an algorithmic characterisation of unit redundancies and reducible functional equivalence classes for a single-hidden-layer hyperbolic tangent architecture. We show that such functional equivalence classes are piecewise-linear path-connected sets, and that for parameters with a majority of redundant units, the sets have a diameter of at most 7 linear segments.
Invariance in Policy Optimisation and Partial Identifiability in Reward Learning
Mar 14, 2022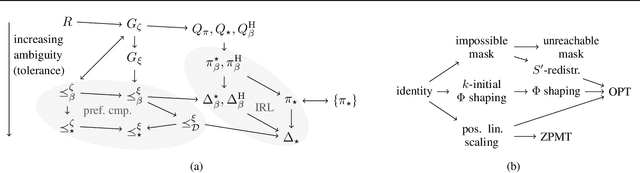
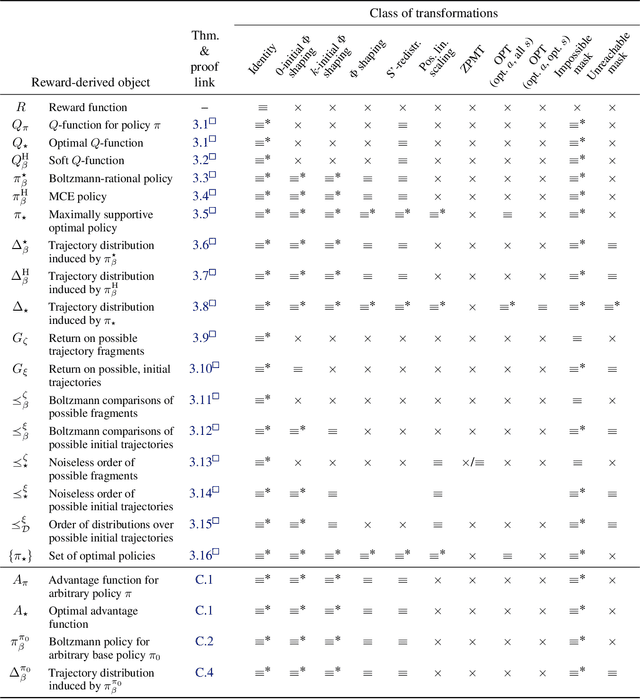
It's challenging to design reward functions for complex, real-world tasks. Reward learning lets one instead infer reward functions from data. However, multiple reward functions often fit the data equally well, even in the infinite-data limit. Prior work often considers reward functions to be uniquely recoverable, by imposing additional assumptions on data sources. By contrast, we formally characterise the partial identifiability of popular data sources, including demonstrations and trajectory preferences, under multiple common sets of assumptions. We analyse the impact of this partial identifiability on downstream tasks such as policy optimisation, including under changes in environment dynamics. We unify our results in a framework for comparing data sources and downstream tasks by their invariances, with implications for the design and selection of data sources for reward learning.