 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariance in Policy Optimisation and Partial Identifiability in Reward Learning
Paper and Code
Mar 14, 2022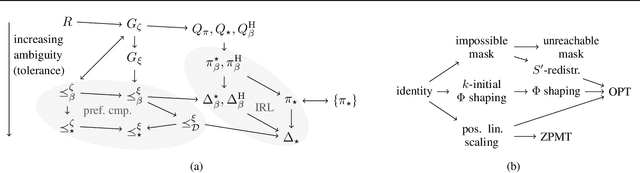
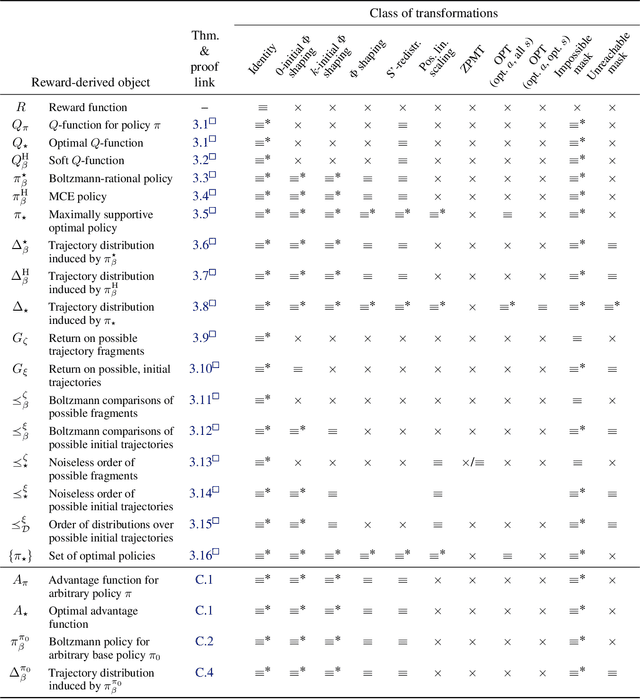
It's challenging to design reward functions for complex, real-world tasks. Reward learning lets one instead infer reward functions from data. However, multiple reward functions often fit the data equally well, even in the infinite-data limit. Prior work often considers reward functions to be uniquely recoverable, by imposing additional assumptions on data sources. By contrast, we formally characterise the partial identifiability of popular data sources, including demonstrations and trajectory preferences, under multiple common sets of assumptions. We analyse the impact of this partial identifiability on downstream tasks such as policy optimisation, including under changes in environment dynamics. We unify our results in a framework for comparing data sources and downstream tasks by their invariances, with implications for the design and selection of data sources for reward learning.