 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Sound Source Localization in Robotics: Focusing on Deep Learning Methods
Jul 01, 2025Sound source localization (SSL) adds a spatial dimension to auditory perception, allowing a system to pinpoint the origin of speech, machinery noise, warning tones, or other acoustic events, capabilities that facilitate robot navigation, human-machine dialogue, and condition monitoring. While existing surveys provide valuable historical context, they typically address general audio applications and do not fully account for robotic constraints or the latest advancements in deep learning. This review addresses these gaps by offering a robotics-focused synthesis, emphasizing recent progress in deep learning methodologies. We start by reviewing classical methods such as Time Difference of Arrival (TDOA), beamforming, Steered-Response Power (SRP), and subspace analysis. Subsequently, we delve into modern machine learning (ML) and deep learning (DL) approaches, discussing traditional ML and neural networks (NNs), convolutional neural networks (CNNs), convolutional recurrent neural networks (CRNNs), and emerging attention-based architectures. The data and training strategy that are the two cornerstones of DL-based SSL are explored. Studies are further categorized by robot types and application domains to facilitate researchers in identifying relevant work for their specific contexts. Finally, we highlight the current challenges in SSL works in general, regarding environmental robustness, sound source multiplicity, and specific implementation constraints in robotics, as well as data and learning strategies in DL-based SSL. Also, we sketch promising directions to offer an actionable roadmap toward robust, adaptable, efficient, and explainable DL-based SSL for next-generation robots.
Testing Human-Hand Segmentation on In-Distribution and Out-of-Distribution Data in Human-Robot Interactions Using a Deep Ensemble Model
Jan 13, 2025



Reliable detection and segmentation of human hands are critical for enhancing safety and facilitating advanced interactions in human-robot collaboration. Current research predominantly evaluates hand segmentation under in-distribution (ID) data, which reflects the training data of deep learning (DL) models. However, this approach fails to address out-of-distribution (OOD) scenarios that often arise in real-world human-robot interactions. In this study, we present a novel approach by evaluating the performance of pre-trained DL models under both ID data and more challenging OOD scenarios. To mimic realistic industrial scenarios, we designed a diverse dataset featuring simple and cluttered backgrounds with industrial tools, varying numbers of hands (0 to 4), and hands with and without gloves. For OOD scenarios, we incorporated unique and rare conditions such as finger-crossing gestures and motion blur from fast-moving hands, addressing both epistemic and aleatoric uncertainties. To ensure multiple point of views (PoVs), we utilized both egocentric cameras, mounted on the operator's head, and static cameras to capture RGB images of human-robot interactions. This approach allowed us to account for multiple camera perspectives while also evaluating the performance of models trained on existing egocentric datasets as well as static-camera datasets. For segmentation, we used a deep ensemble model composed of UNet and RefineNet as base learners. Performance evaluation was conducted using segmentation metrics and uncertainty quantification via predictive entropy. Results revealed that models trained on industrial datasets outperformed those trained on non-industrial datasets, highlighting the importance of context-specific training. Although all models struggled with OOD scenarios, those trained on industrial datasets demonstrated significantly better generalization.
Evaluating deep learning models for fault diagnosis of a rotating machinery with epistemic and aleatoric uncertainty
Dec 25, 2024
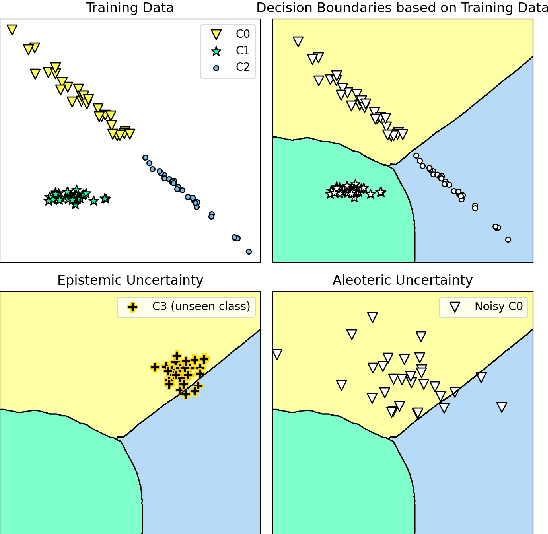

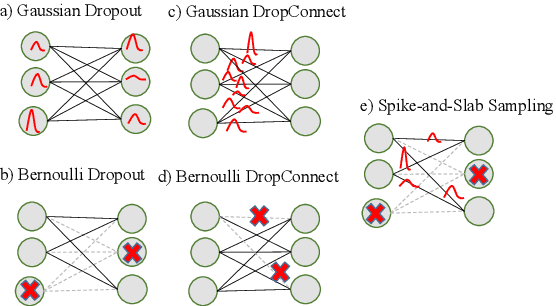
Uncertainty-aware deep learning (DL) models recently gained attention in fault diagnosis as a way to promote the reliable detection of faults when out-of-distribution (OOD) data arise from unseen faults (epistemic uncertainty) or the presence of noise (aleatoric uncertainty). In this paper, we present the first comprehensive comparative study of state-of-the-art uncertainty-aware DL architectures for fault diagnosis in rotating machinery, where different scenarios affected by epistemic uncertainty and different types of aleatoric uncertainty are investigated. The selected architectures include sampling by dropout, Bayesian neural networks, and deep ensembles. Moreover, to distinguish between in-distribution and OOD data in the different scenarios two uncertainty thresholds, one of which is introduced in this paper, are alternatively applied. Our empirical findings offer guidance to practitioners and researchers who have to deploy real-world uncertainty-aware fault diagnosis systems. In particular, they reveal that, in the presence of epistemic uncertainty, all DL models are capable of effectively detecting, on average, a substantial portion of OOD data across all the scenarios. However, deep ensemble models show superior performance, independently of the uncertainty threshold used for discrimination. In the presence of aleatoric uncertainty, the noise level plays an important role. Specifically, low noise levels hinder the models' ability to effectively detect OOD data. Even in this case, however, deep ensemble models exhibit a milder degradation in performance, dominating the others. These achievements, combined with their shorter inference time, make deep ensemble architectures the preferred choice.
Automated Optimal Layout Generator for Animal Shelters: A framework based on Genetic Algorithm, TOPSIS and Graph Theory
May 23, 2024Overpopulation in animal shelters contributes to increased disease spread and higher expenses on animal healthcare, leading to fewer adoptions and more shelter deaths. Additionally, one of the greatest challenges that shelters face is the noise level in the dog kennel area, which is physically and physiologically hazardous for both animals and staff. This paper proposes a multi-criteria optimization framework to automatically design cage layouts that maximize shelter capacity, minimize tension in the dog kennel area by reducing the number of cages facing each other, and ensure accessibility for staff and visitors. The proposed framework uses a Genetic Algorithm (GA) to systematically generate and improve layouts. A novel graph theory-based algorithm is introduced to process solutions and calculate fitness values. Additionally, the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) is used to rank and sort the layouts in each iteration. The graph-based algorithm calculates variables such as cage accessibility and shortest paths to access points. Furthermore, a heuristic algorithm is developed to calculate layout scores based on the number of cages facing each other. This framework provides animal shelter management with a flexible decision-support system that allows for different strategies by assigning various weights to the TOPSIS criteria. Results from cats' and dogs' kennel areas show that the proposed framework can suggest optimal layouts that respect different priorities within acceptable runtimes.
Deep reinforcement learning for machine scheduling: Methodology, the state-of-the-art, and future directions
Oct 04, 2023Machine scheduling aims to optimize job assignments to machines while adhering to manufacturing rules and job specifications. This optimization leads to reduced operational costs, improved customer demand fulfillment, and enhanced production efficiency. However, machine scheduling remains a challenging combinatorial problem due to its NP-hard nature. Deep Reinforcement Learning (DRL), a key component of artificial general intelligence, has shown promise in various domains like gaming and robotics. Researchers have explored applying DRL to machine scheduling problems since 1995. This paper offers a comprehensive review and comparison of DRL-based approaches, highlighting their methodology, applications, advantages, and limitations. It categorizes these approaches based on computational components: conventional neural networks, encoder-decoder architectures, graph neural networks, and metaheuristic algorithms. Our review concludes that DRL-based methods outperform exact solvers, heuristics, and tabular reinforcement learning algorithms in terms of computation speed and generating near-global optimal solutions. These DRL-based approaches have been successfully applied to static and dynamic scheduling across diverse machine environments and job characteristics. However, DRL-based schedulers face limitations in handling complex operational constraints, configurable multi-objective optimization, generalization, scalability, interpretability, and robustness. Addressing these challenges will be a crucial focus for future research in this field. This paper serves as a valuable resource for researchers to assess the current state of DRL-based machine scheduling and identify research gaps. It also aids experts and practitioners in selecting the appropriate DRL approach for production scheduling.
Synthesizing Rolling Bearing Fault Samples in New Conditions: A framework based on a modified CGAN
Jun 29, 2022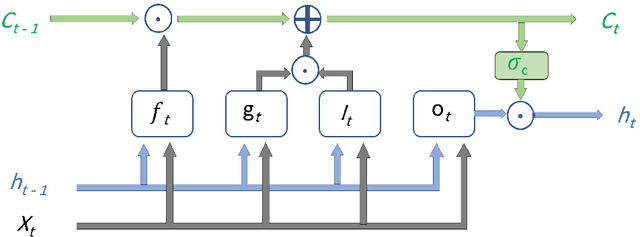


Bearings are one of the vital components of rotating machines that are prone to unexpected faults. Therefore, bearing fault diagnosis and condition monitoring is essential for reducing operational costs and downtime in numerous industries. In various production conditions, bearings can be operated under a range of loads and speeds, which causes different vibration patterns associated with each fault type. Normal data is ample as systems usually work in desired conditions. On the other hand, fault data is rare, and in many conditions, there is no data recorded for the fault classes. Accessing fault data is crucial for developing data-driven fault diagnosis tools that can improve both the performance and safety of operations. To this end, a novel algorithm based on Conditional Generative Adversarial Networks (CGANs) is introduced. Trained on the normal and fault data on any actual fault conditions, this algorithm generates fault data from normal data of target conditions. The proposed method is validated on a real-world bearing dataset, and fault data are generated for different conditions. Several state-of-the-art classifiers and visualization models are implemented to evaluate the quality of the synthesized data. The results demonstrate the efficacy of the proposed algorithm.
Fault Detection and Diagnosis with Imbalanced and Noisy Data: A Hybrid Framework for Rotating Machinery
Feb 09, 2022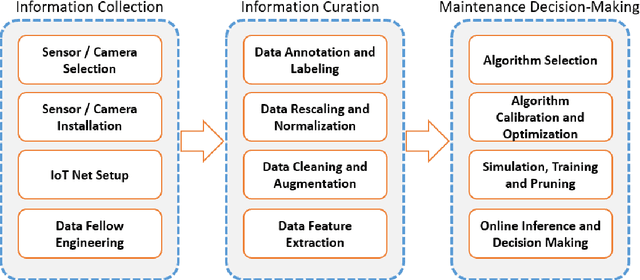
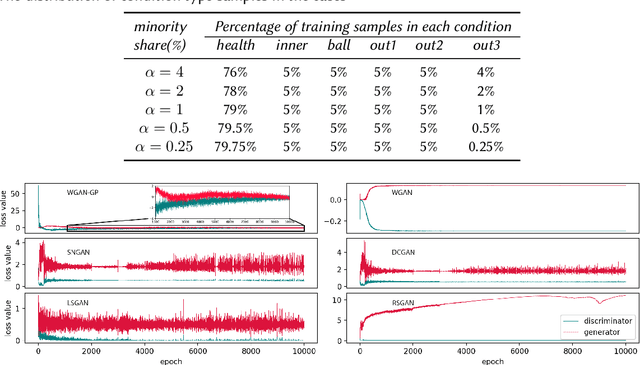
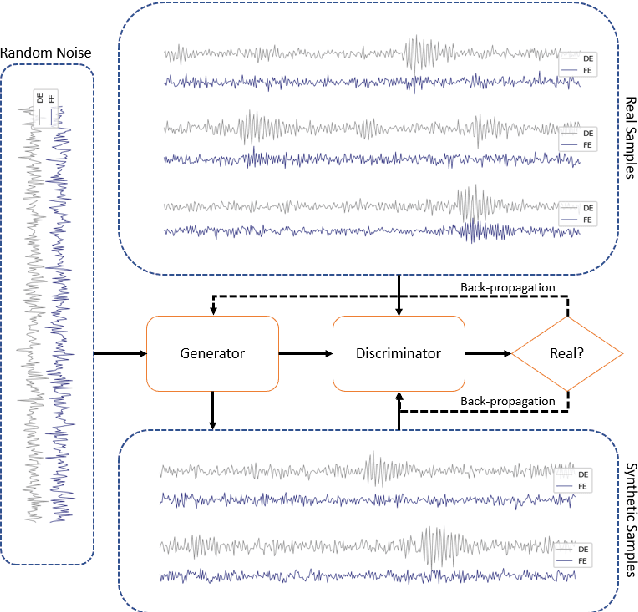
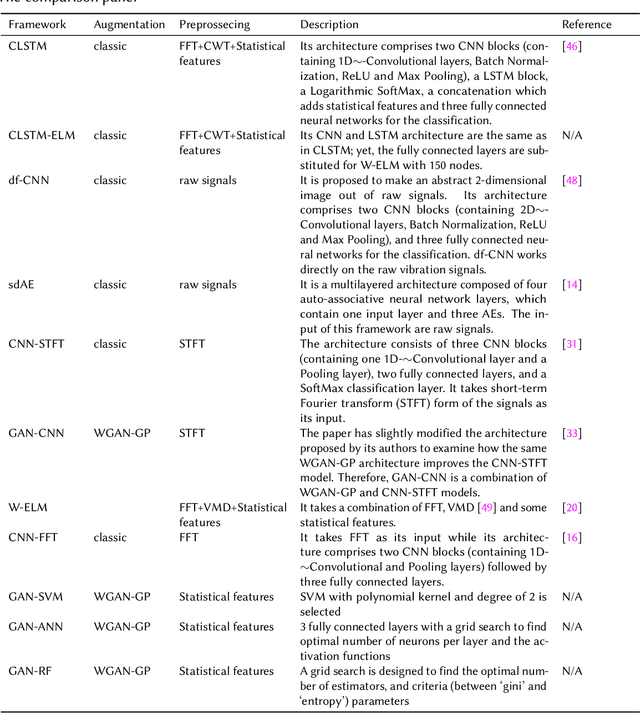
Fault diagnosis plays an essential role in reducing the maintenance costs of rotating machinery manufacturing systems. In many real applications of fault detection and diagnosis, data tend to be imbalanced, meaning that the number of samples for some fault classes is much less than the normal data samples. At the same time, in an industrial condition, accelerometers encounter high levels of disruptive signals and the collected samples turn out to be heavily noisy. As a consequence, many traditional Fault Detection and Diagnosis (FDD) frameworks get poor classification performances when dealing with real-world circumstances. Three main solutions have been proposed in the literature to cope with this problem: (1) the implementation of generative algorithms to increase the amount of under-represented input samples, (2) the employment of a classifier being powerful to learn from imbalanced and noisy data, (3) the development of an efficient data pre-processing including feature extraction and data augmentation. This paper proposes a hybrid framework which uses the three aforementioned components to achieve an effective signal-based FDD system for imbalanced conditions. Specifically, it first extracts the fault features, using Fourier and wavelet transforms to make full use of the signals. Then, it employs Wasserstein Generative Adversarial Networks (WGAN) to generate synthetic samples to populate the rare fault class and enhance the training set. Moreover, to achieve a higher performance a novel combination of Convolutional Long Short-term Memory (CLSTM) and Weighted Extreme Learning Machine (WELM) is proposed. To verify the effectiveness of the developed framework, different datasets settings on different imbalance severities and noise degrees were used. The comparative results demonstrate that in different scenarios GAN-CLSTM-ELM outperforms the other state-of-the-art FDD frameworks.
Automatic Visual Inspection of Rare Defects: A Framework based on GP-WGAN and Enhanced Faster R-CNN
May 02, 2021
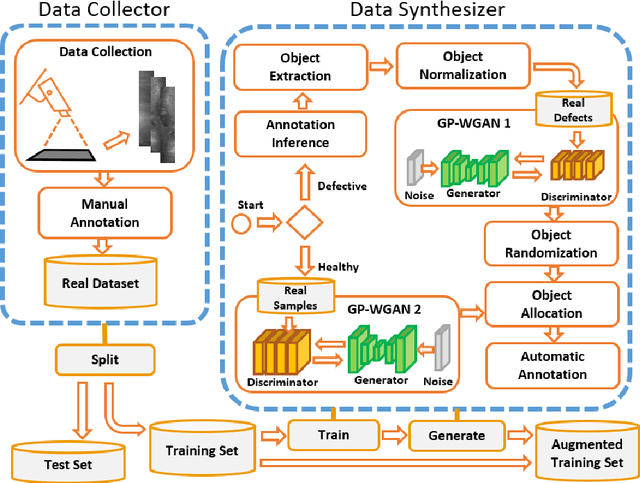
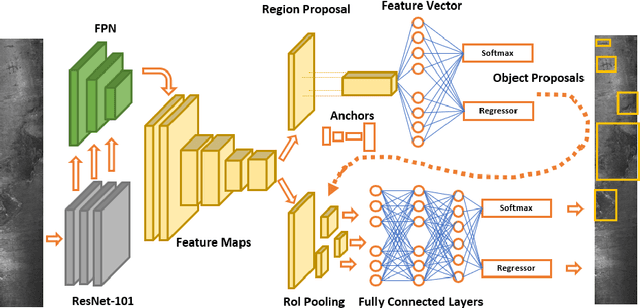
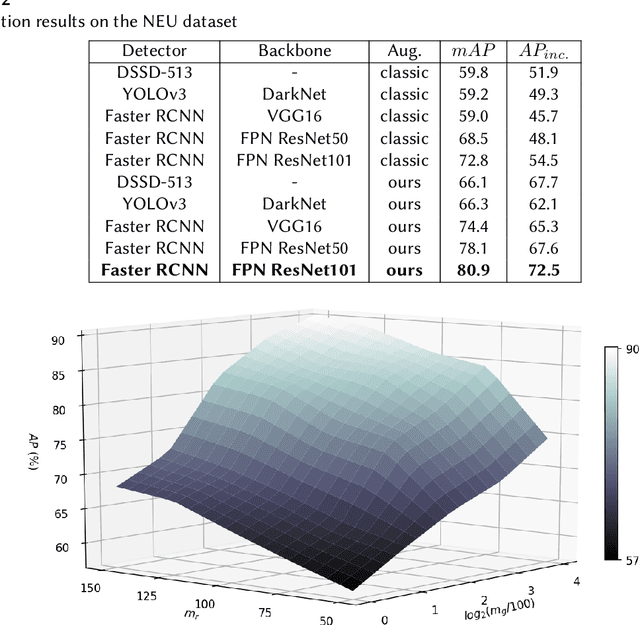
A current trend in industries such as semiconductors and foundry is to shift their visual inspection processes to Automatic Visual Inspection (AVI) systems, to reduce their costs, mistakes, and dependency on human experts. This paper proposes a two-staged fault diagnosis framework for AVI systems. In the first stage, a generation model is designed to synthesize new samples based on real samples. The proposed augmentation algorithm extracts objects from the real samples and blends them randomly, to generate new samples and enhance the performance of the image processor. In the second stage, an improved deep learning architecture based on Faster R-CNN, Feature Pyramid Network (FPN), and a Residual Network is proposed to perform object detection on the enhanced dataset. The performance of the algorithm is validated and evaluated on two multi-class datasets. The experimental results performed over a range of imbalance severities demonstrate the superiority of the proposed framework compared to other solutions.