 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Voice-Assistant NLU using BERT-based Interchangeable Rephrase
Apr 16, 2021
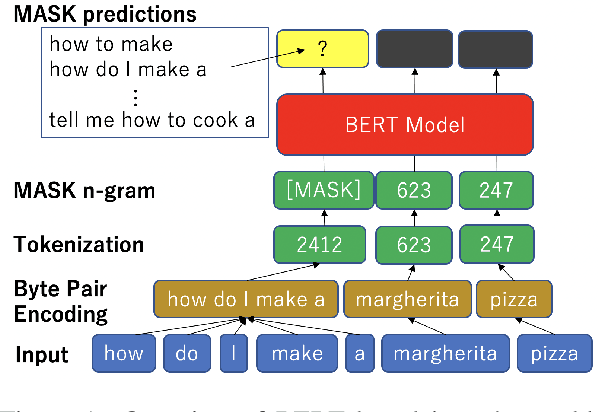
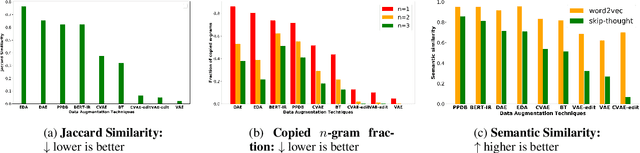
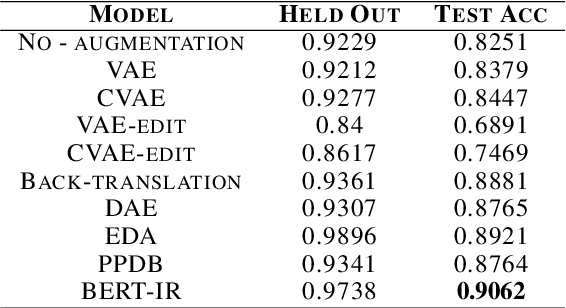
We introduce a data augmentation technique based on byte pair encoding and a BERT-like self-attention model to boost performance on spoken language understanding tasks. We compare and evaluate this method with a range of augmentation techniques encompassing generative models such as VAEs and performance-boosting techniques such as synonym replacement and back-translation. We show our method performs strongly on domain and intent classification tasks for a voice assistant and in a user-study focused on utterance naturalness and semantic similarity.
Learning and Evaluating Musical Features with Deep Autoencoders
Jun 15, 2017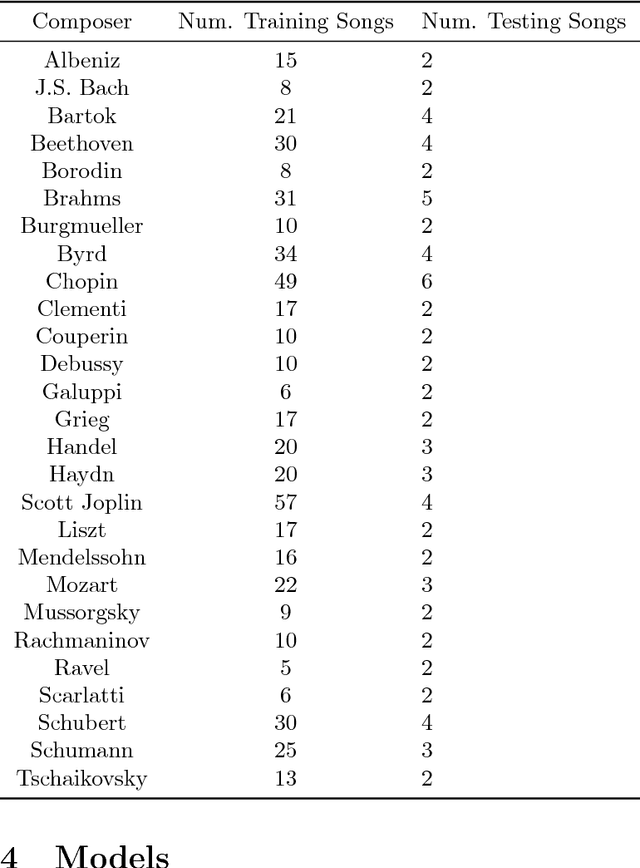

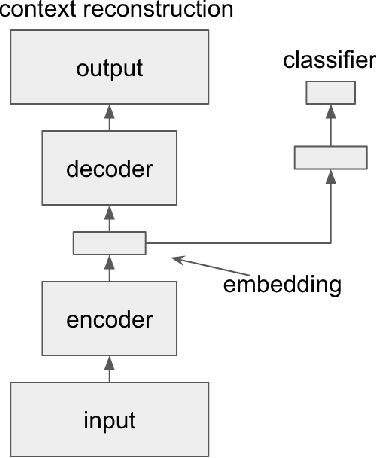
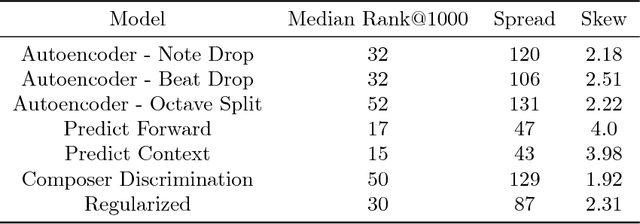
In this work we describe and evaluate methods to learn musical embeddings. Each embedding is a vector that represents four contiguous beats of music and is derived from a symbolic representation. We consider autoencoding-based methods including denoising autoencoders, and context reconstruction, and evaluate the resulting embeddings on a forward prediction and a classification task.
You Are What You Eat Listen to, Watch, and Read
Dec 13, 2016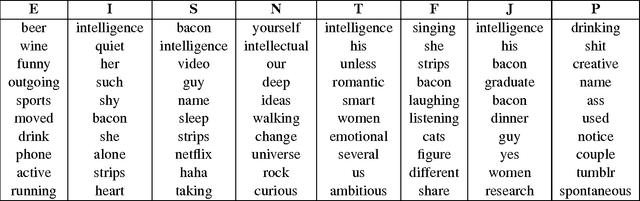
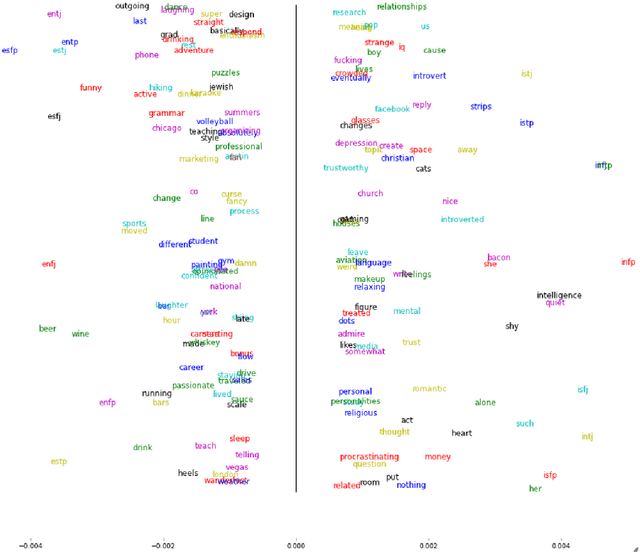

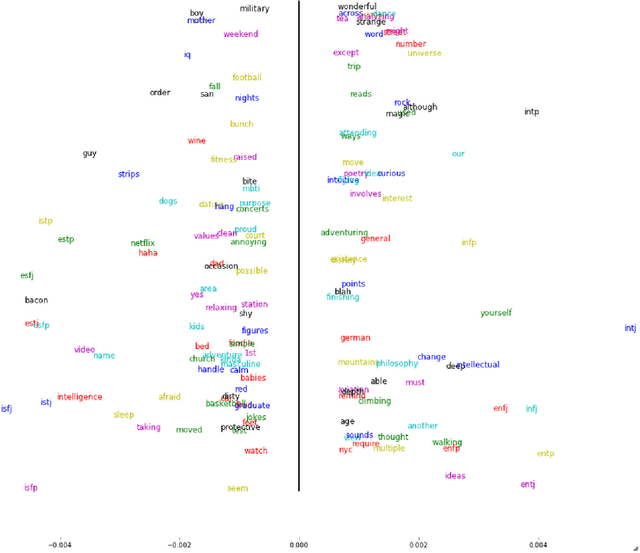
This article describes a data driven method for deriving the relationship between personality and media preferences. A qunatifiable representation of such a relationship can be leveraged for use in recommendation systems and ameliorate the "cold start" problem. Here, the data is comprised of an original collection of 1,316 Okcupid dating profiles. Of these profiles, 800 are labeled with one of 16 possible Myers-Briggs Type Indicators (MBTI). A personality specific topic model describing a person's favorite books, movies, shows, music, and food was generated using latent Dirichlet allocation (LDA). There were several significant findings, for example, intuitive thinking types preferred sci-fi/fantasy entertainment, extraversion correlated positively with upbeat dance music, and jazz, folk, and international cuisine correlated positively with those characterized by openness to experience. Many other correlations confirmed previous findings describing the relationship among personality, writing style, and personal preferences. (For complete word/personality type assocations see the Appendix).
A Robotic Prosthesis for an Amputee Drummer
Dec 13, 2016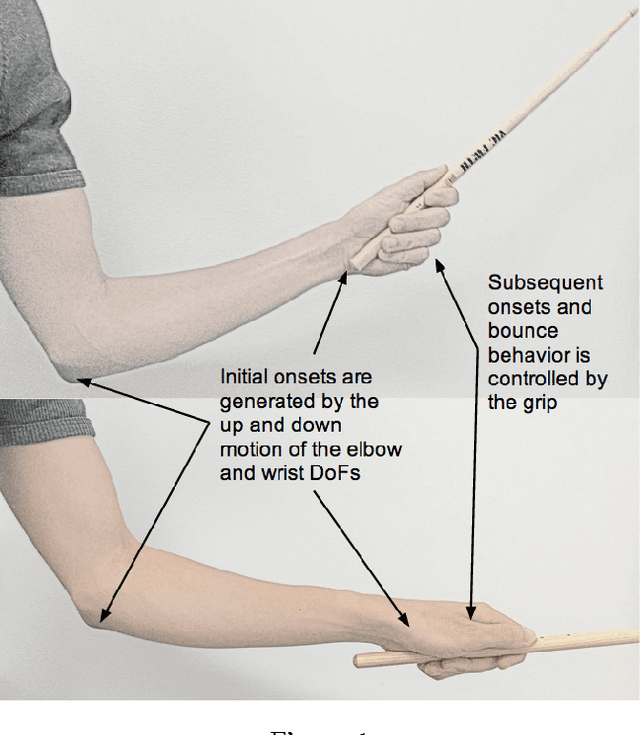
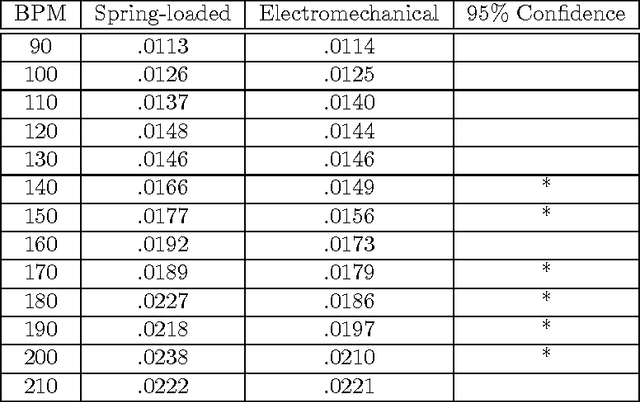
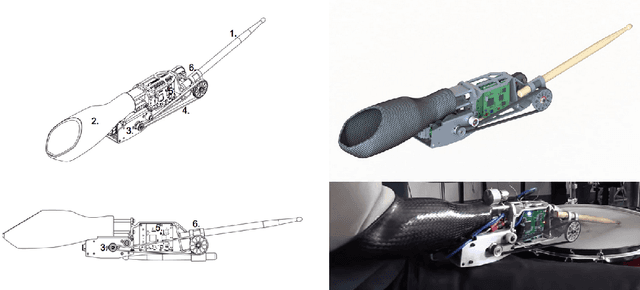
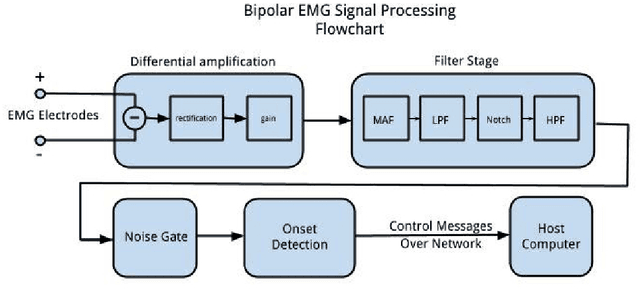
The design and evaluation of a robotic prosthesis for a drummer with a transradial amputation is presented. The principal objective of the prosthesis is to simulate the role fingers play in drumming. This primarily includes controlling the manner in which the drum stick rebounds after initial impact. This is achieved using a DC motor driven by a variable impedance control framework in a shared control system. The user's ability to perform with and control the prosthesis is evaluated using a musical synchronization study. A secondary objective of the prosthesis is to explore the implications of musical expression and human-robotic interaction when a second, completely autonomous, stick is added to the prosthesis. This wearable robotic musician interacts with the user by listening to the music and responding with different rhythms and behaviors. We recount some empirical findings based on the user's experience of performing under such a paradigm.
A Unit Selection Methodology for Music Generation Using Deep Neural Networks
Dec 12, 2016
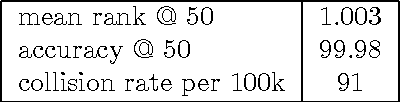

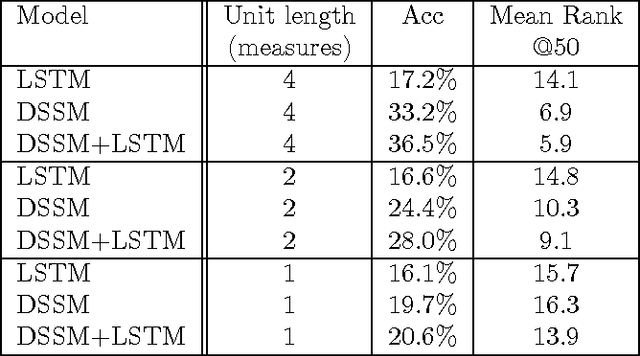
Several methods exist for a computer to generate music based on data including Markov chains, recurrent neural networks, recombinancy, and grammars. We explore the use of unit selection and concatenation as a means of generating music using a procedure based on ranking, where, we consider a unit to be a variable length number of measures of music. We first examine whether a unit selection method, that is restricted to a finite size unit library, can be sufficient for encompassing a wide spectrum of music. We do this by developing a deep autoencoder that encodes a musical input and reconstructs the input by selecting from the library. We then describe a generative model that combines a deep structured semantic model (DSSM) with an LSTM to predict the next unit, where units consist of four, two, and one measures of music. We evaluate the generative model using objective metrics including mean rank and accuracy and with a subjective listening test in which expert musicians are asked to complete a forced-choiced ranking task. We compare our model to a note-level generative baseline that consists of a stacked LSTM trained to predict forward by one note.