 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unit Selection Methodology for Music Generation Using Deep Neural Networks
Paper and Code
Dec 12, 2016
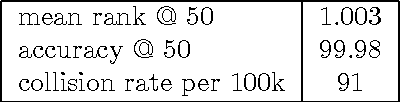

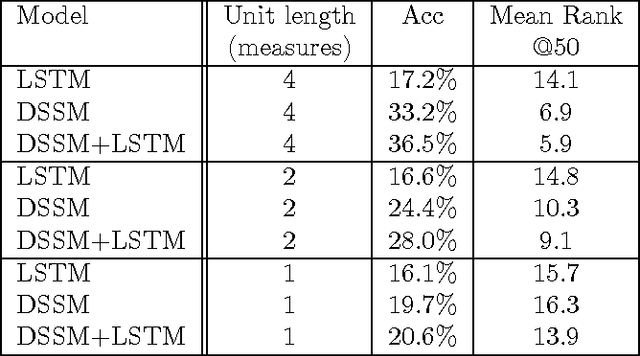
Several methods exist for a computer to generate music based on data including Markov chains, recurrent neural networks, recombinancy, and grammars. We explore the use of unit selection and concatenation as a means of generating music using a procedure based on ranking, where, we consider a unit to be a variable length number of measures of music. We first examine whether a unit selection method, that is restricted to a finite size unit library, can be sufficient for encompassing a wide spectrum of music. We do this by developing a deep autoencoder that encodes a musical input and reconstructs the input by selecting from the library. We then describe a generative model that combines a deep structured semantic model (DSSM) with an LSTM to predict the next unit, where units consist of four, two, and one measures of music. We evaluate the generative model using objective metrics including mean rank and accuracy and with a subjective listening test in which expert musicians are asked to complete a forced-choiced ranking task. We compare our model to a note-level generative baseline that consists of a stacked LSTM trained to predict forward by one note.